¶ VMware vSphere : Install, Configure, Manage
Lab 25: Configuration de vSphere HA
¶ Introduction
Ce Lab a pour objectif d'illustrer la documentation permettant de se préparer au passage de la certification VMWare Certified Professional - Data Center Virtualization v8 (2V0-21.23).
Plus précisément le chapitre 9 - Déploiement et configuration des clusters vSphere.
Cours Traité : Leçon 5 : Configuration de vSphere HA
Avant de commencer, je tiens à préciser qu'il est préférable d'avoir lu la documentation.
Pour réaliser l'ensemble des différents Labs j'ai dans un premier temps créé un environnement virtuel comprenant les éléments suivants :
- 1 vCenter : LAB-VCENTER-01.LAB.LOCAL
- 3 ESXi Nested : LAB-ESXI-01.LAB.LOCAL, LAB-ESXI-02.LAB.LOCAL et LAB-ESXI-03.LAB.LOCAL
- 1 Windows Server 2025 (eval) : LAB-AD-01 pour l'Active Directory
Selon le lab, tous ces éléments ne sont pas forcément utilisés cependant ils le seront au fur et à mesure des différents labs.
De ce fait, pour reproduire les Lab , il est conseillé d'avoir à disposition un environnement équivalant.
Je vais partir du principe que vous possédez un Lab à disposition.
¶ Objectif et tâches
Configurer vSphere HA et tester sa fonctionnalité :
- Configurer vSphere HA dans un Cluster
- Afficher les informations concernant le Cluster vSphere HA
- Configurer la redondance du réseau de management
- Tester la fonctionnalité vSphere HA
- Afficher l’utilisation des ressources du Cluster vSphere HA
- Configurer le pourcentage de dégradation des ressources à tolérer
¶ Tâche 1 : Configurer vSphere HA dans un Cluster
Vous configurez vSphere HA sur le cluster LAB-VCP-DCV-COMPUTE-01 afin d’obtenir un niveau de disponibilité des machines virtuelles supérieur à celui que chaque hôte ESXi peut fournir individuellement.
- Connectez vous à vCenter en utilisant le compte Administrator@vsphere.local.
Le compte Administrator@vsphere.local est le compte utilisateur par défaut que l'on trouve sur vCenter après son installation.
Pour se connecter il faudra utiliser cette URL : https://<vCenter_FQDN_or_IP_Address>/ui.
Dans le cas de mon Lab ça sera donc soit "lab-vcenter-01.lab.local/ui" soit l'adresse IP de vCenter.
- Ouvrir un navigateur Web et se connecter à l'URL de vCenter

- Se connecter avec l'utilisateur Administrator@vsphere.local
- Dans le menu principal, sélectionnez Inventory et cliquez sur l’icône Hosts and Clusters.
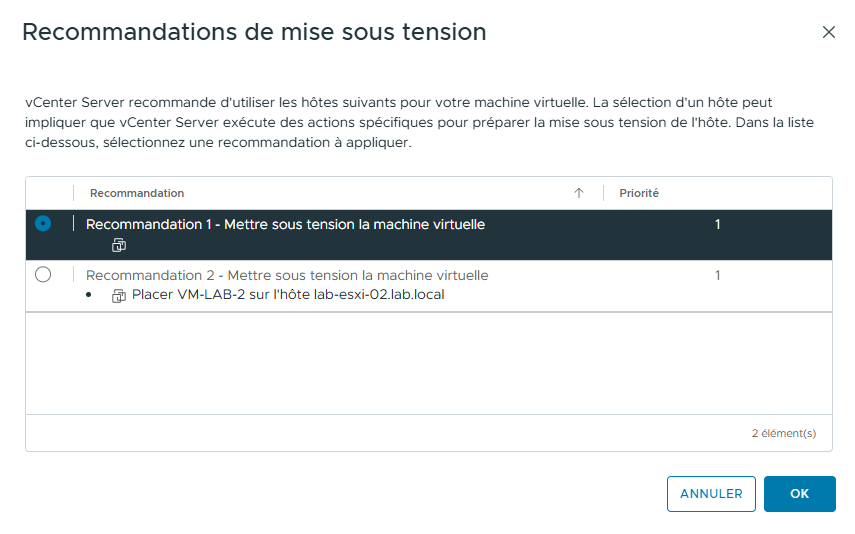
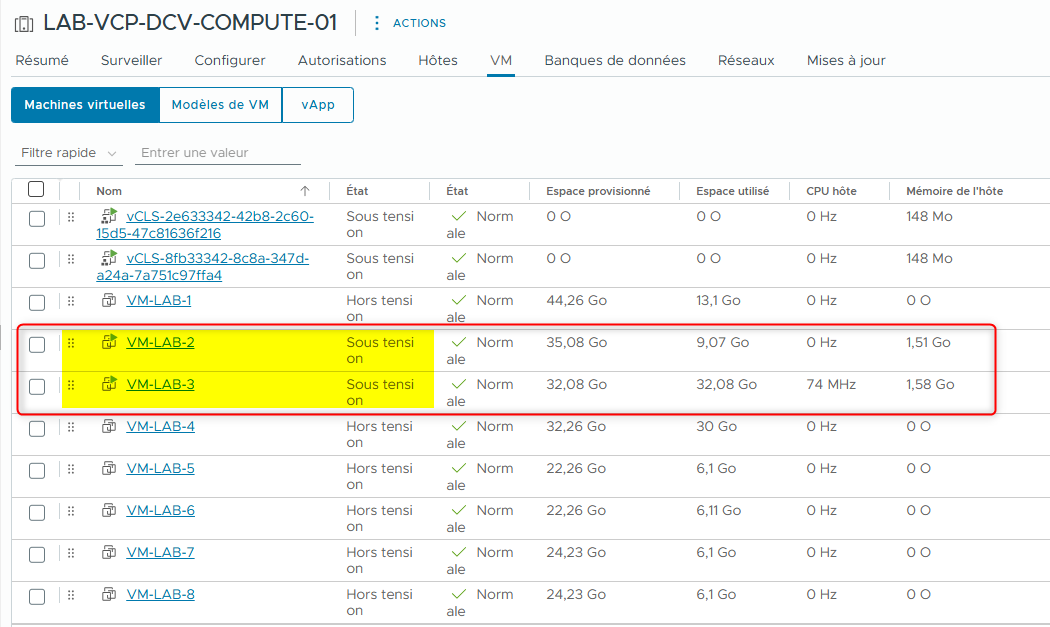
- Mettez sous tension les VMs VM-LAB-2 et VM-LAB-3.
vSphere DRS vous présente des recommandations de placement des VMs.
- Choisissez la première recommandation et cliquez sur OK.
- Sélectionnez LAB-VCP-DCV-COMPUTE-01 et cliquez sur l’onglet Configure dans le volet de droite.
- Sous Services, sélectionnez vSphere Availability et cliquez sur le premier bouton EDIT à droite de vSphere HA.
La boîte de dialogue Edit Cluster Settings s’ouvre.

- Cliquez sur le bouton à bascule vSphere HA pour l’activer et cliquez sur OK.
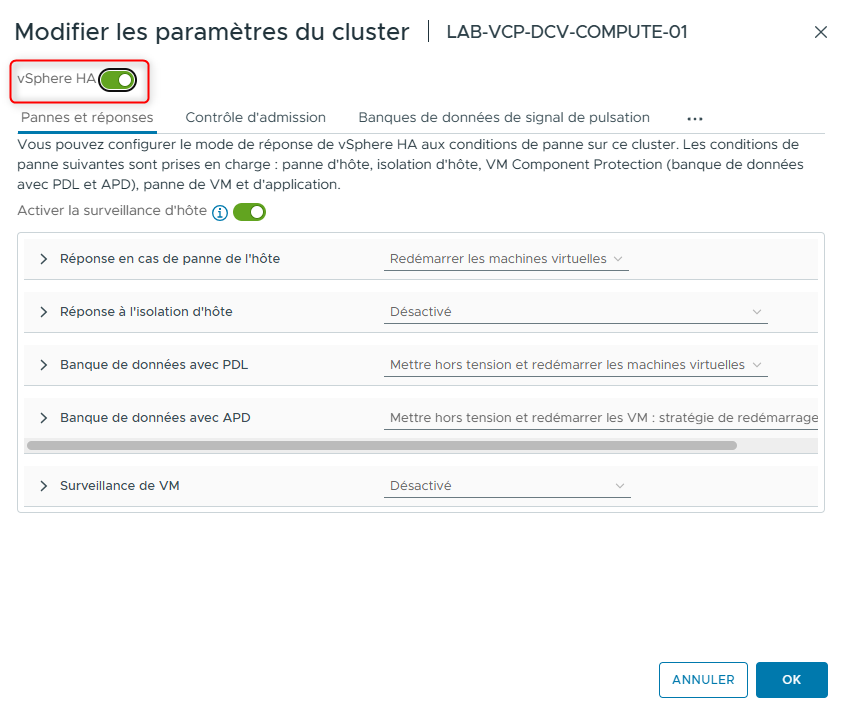
-
Surveillez le volet Recent Tasks et attendez la fin des tâches de configuration vSphere HA.
Cela peut prendre quelques minutes. -
Affichez l’onglet Configure et vérifiez que vSphere HA est activé.
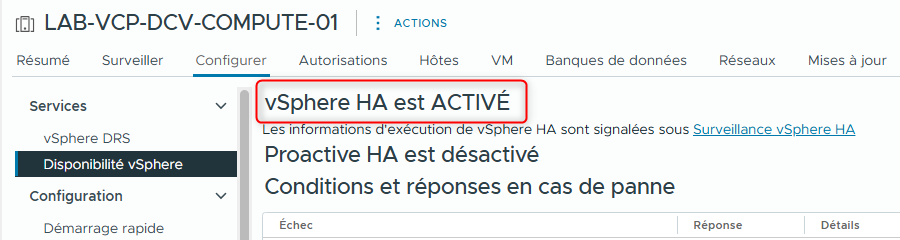
¶ Tâche 2 : Afficher les informations concernant le Cluster vSphere HA
Vous affichez l’état et les informations de configuration du cluster LAB-VCP-DCV-COMPUTE-01. Vous remarquez que les hôtes ESXi du cluster possèdent uniquement un adaptateur VMkernel de management.
- Dans le volet de droite, cliquez sur l’onglet Monitor.
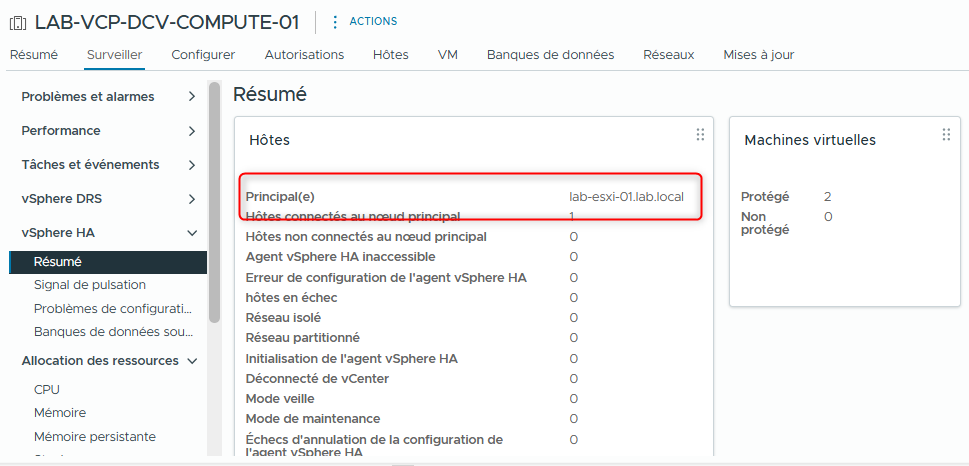
- Sous vSphere HA, sélectionnez Summary.
Les informations récapitulatives de vSphere HA apparaissent.
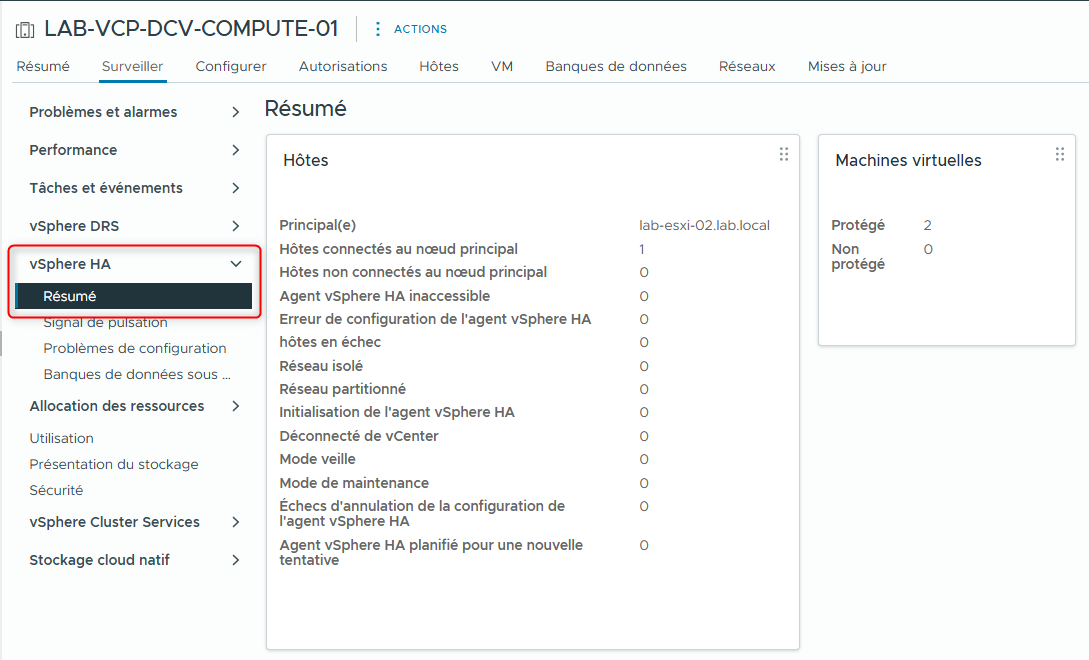
- Notez le nom de l’hôte principal.
- Si aucun hôte principal n’est affiché, cliquez sur l’icône Refresh en haut de la fenêtre.
vSphere HA peut encore être en cours d’initialisation.
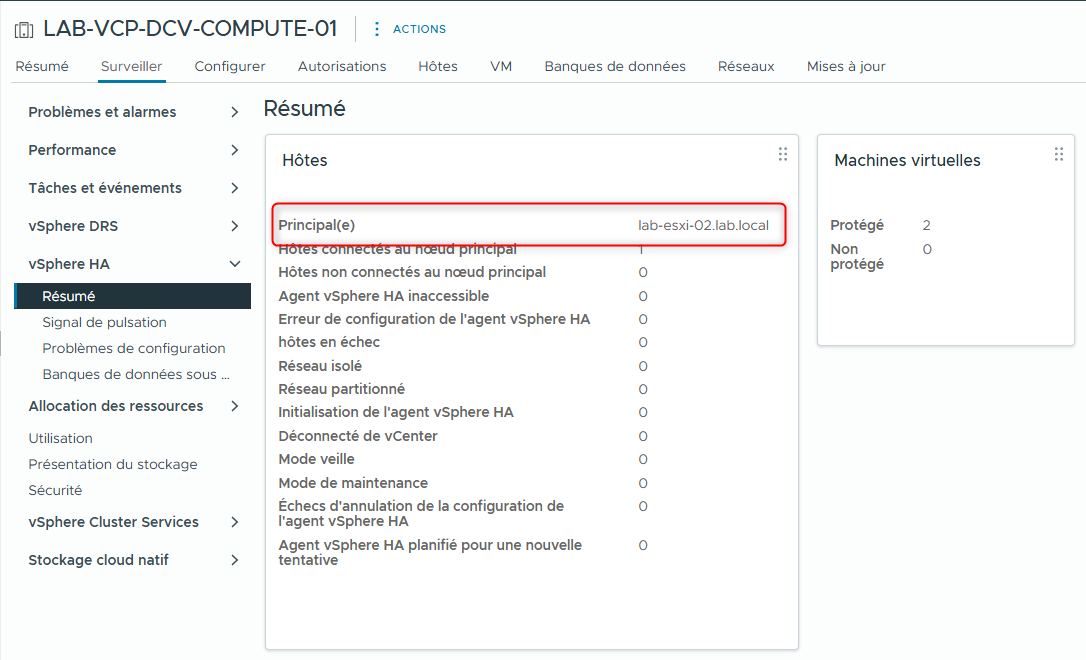
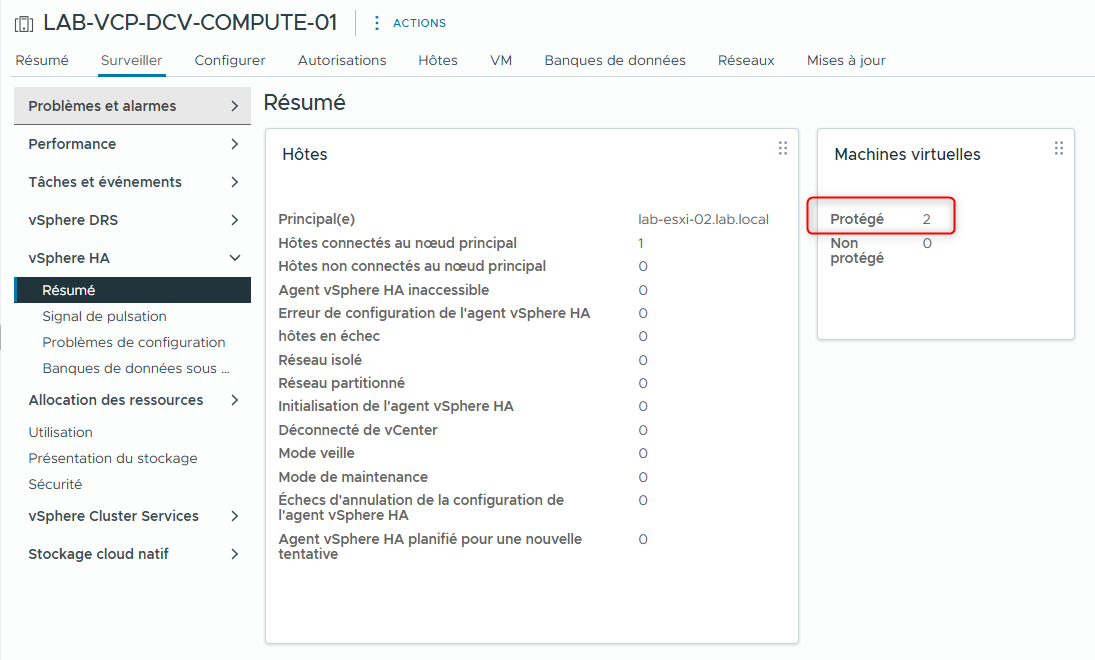
- Notez le nombre de machines virtuelles protégées.
- Cliquez sur l’onglet VMs dans le volet de droite.
¶ Question :
- Q1. Le nombre de machines virtuelles protégées correspond-il au nombre de machines virtuelles allumées dans le cluster ?
¶ Réponse :
- R1. Oui.
Si les deux hôtes sont ajoutés au cluster et qu’aucune erreur ne se produit sur le cluster, le nombre de VMs protégées est égal au nombre de VMs sous tension. Le nombre de VMs protégées inclut les VMs vSphere Cluster Service.
-
Cliquez à nouveau sur l’onglet Monitor.
-
Sous vSphere HA, sélectionnez Heartbeat.
¶ Question :
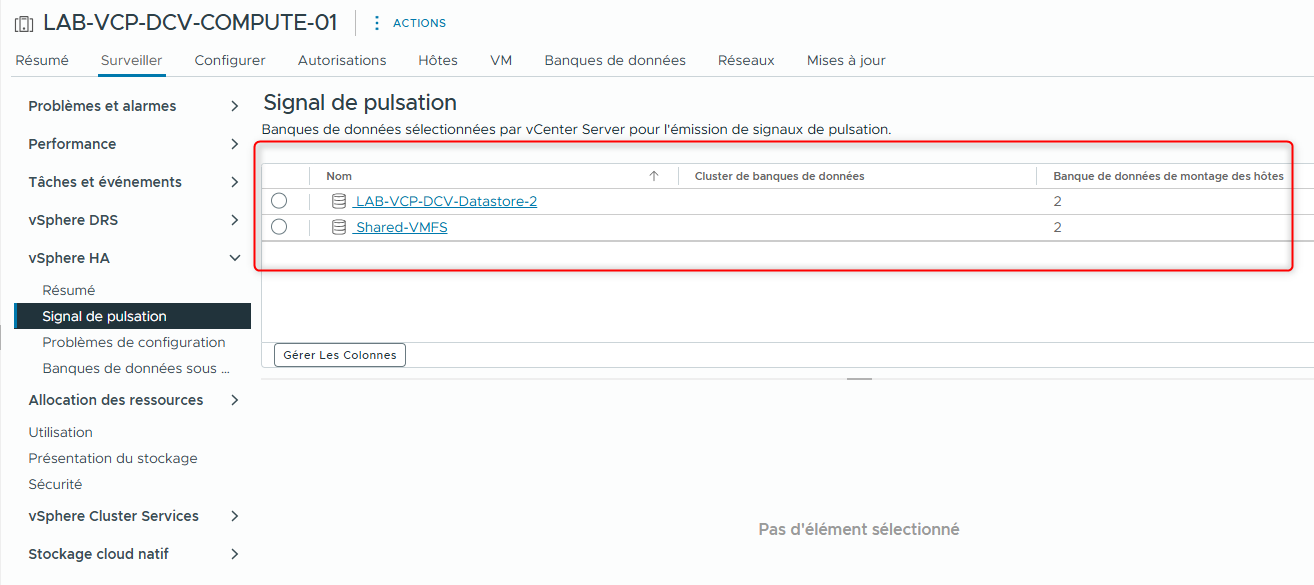
- Q2. Combien de datastores sont utilisés pour surveiller le heartbeat ?
¶ Réponse :
- R2. Deux datastores.
Comme les deux datastores sont partagés par tous les hôtes du cluster, ils sont automatiquement sélectionnés pour le heartbeating.
-
Sous vSphere HA, sélectionnez Configuration Issues et examinez les erreurs ou avertissements affichés.
Vous devriez voir un message d’avertissement indiquant que lab-esxi-02.lab.local n’a pas de redondance du réseau de management.
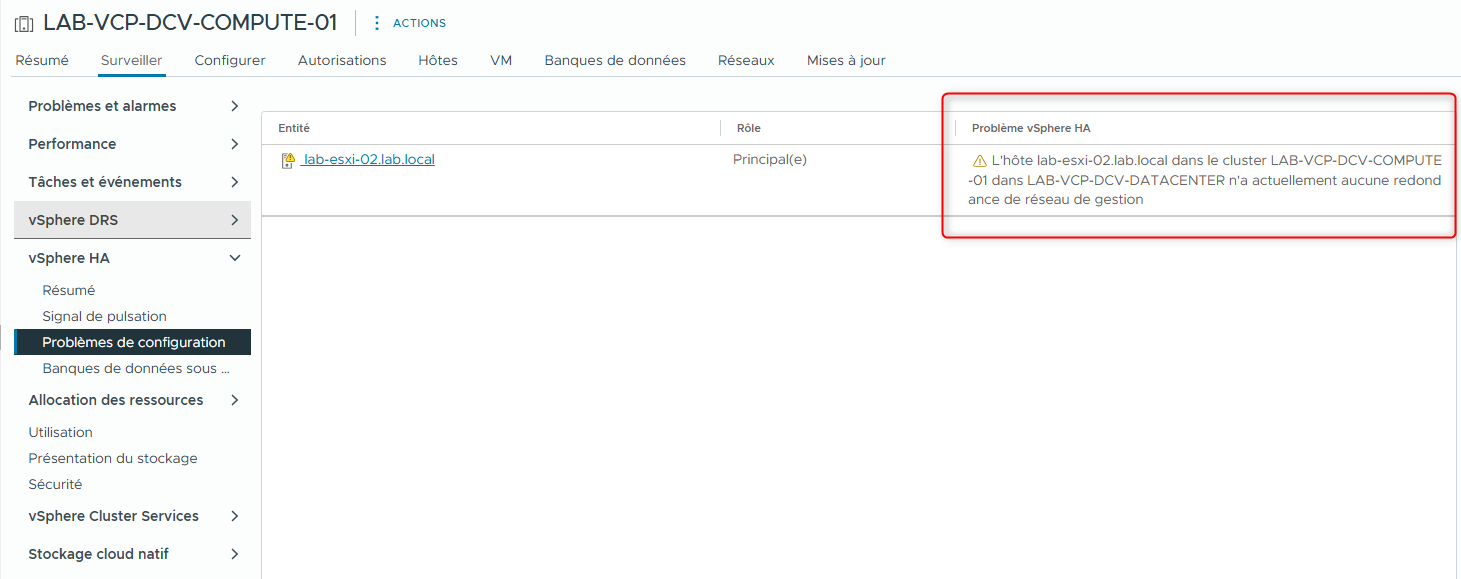
Actuellement, lab-esxi-02.lab.local possède un seul adaptateur VMkernel de management. De plus, le réseau de Management utilise un seul adaptateur physique, vmnic0.
vSphere HA fonctionne toujours avec un seul adaptateur VMkernel, ou un seul adaptateur physique dans le réseau de Management. Cependant, un deuxième adaptateur VMkernel de management ou un deuxième adaptateur physique est nécessaire pour assurer la redondance du réseau de management.
La configuration d’une redondance réseau de management constitue également une bonne pratique.
¶ Question :
- Q3. Pourquoi n’y a-t-il aucun message d’avertissement pour lab-esxi-01.lab.local ?
¶ Réponse :
- R3. Il n’y a pas de message d’avertissement pour lab-esxi-01.lab.local parce que cet hôte possède déjà une redondance réseau de management. Sa configuration réseau permet la tolérance aux pannes, contrairement à lab-esxi-02.lab.local qui n’a qu’un seul adaptateur de management.
¶ Tâche 3 : Configurer la redondance du réseau de management
Vous configurez la redondance du réseau de management en ajoutant un second adaptateur physique (vmnic) au Management Network port group. L’ajout d’un second vmnic crée une redondance et supprime le point de défaillance unique.
- Dans le volet de navigation, sélectionnez lab-esxi-02.lab.local.
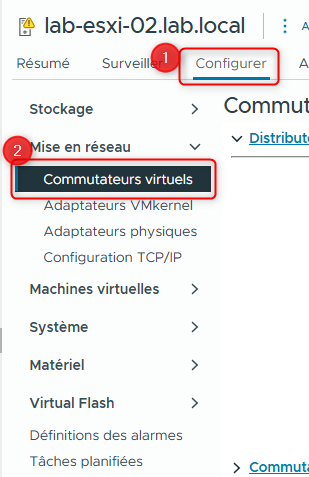
- Dans le volet de droite, cliquez sur l’onglet Configure et, sous Networking, sélectionnez Virtual switches.
-
Réduisez dvs-Lab et développez vSwitch0.
-
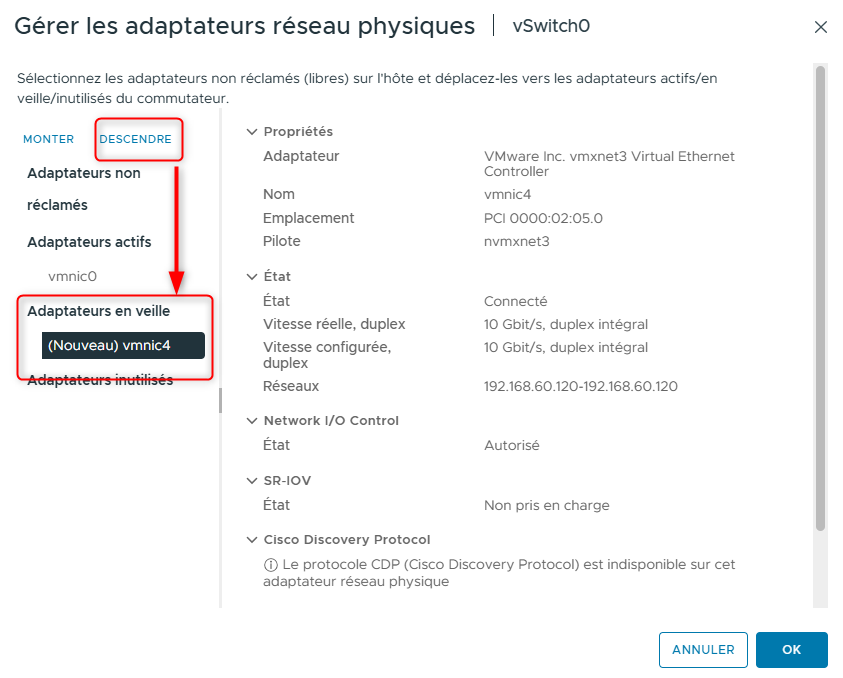
À droite de vSwitch0, cliquez sur MANAGE PHYSICAL ADAPTERS.
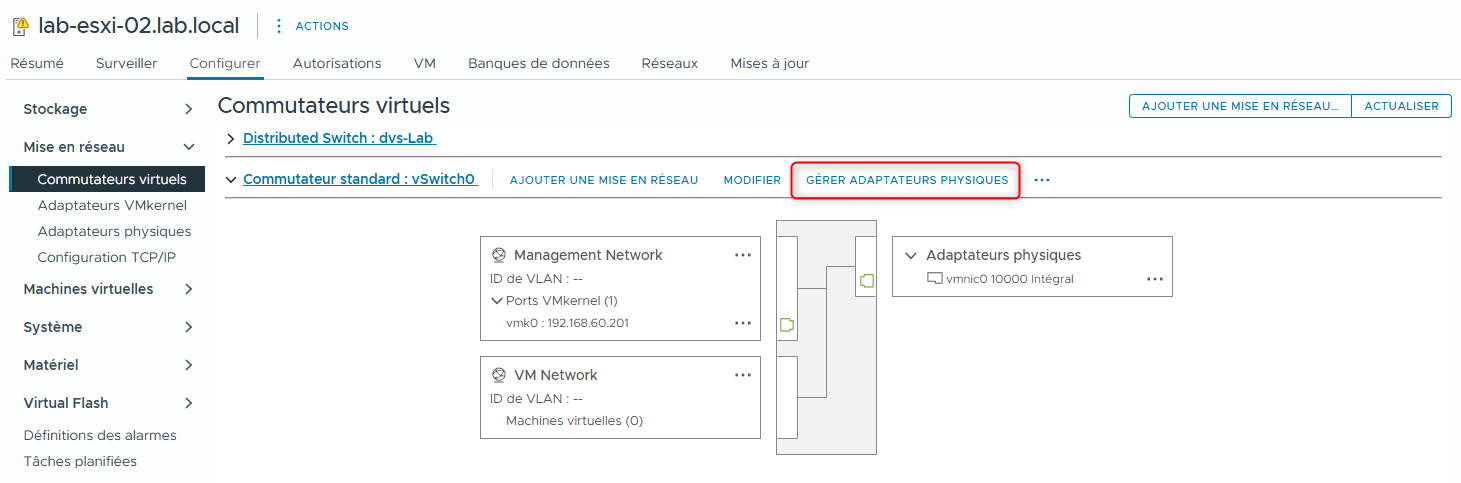
- Sélectionnez vmnic4 et déplacez-le vers le bas jusqu’à ce qu’il apparaisse sous Standby adapters.
-
Cliquez sur OK.
-
Vérifiez que vSwitch0 possède deux adaptateurs physiques : vmnic0 et vmnic4.
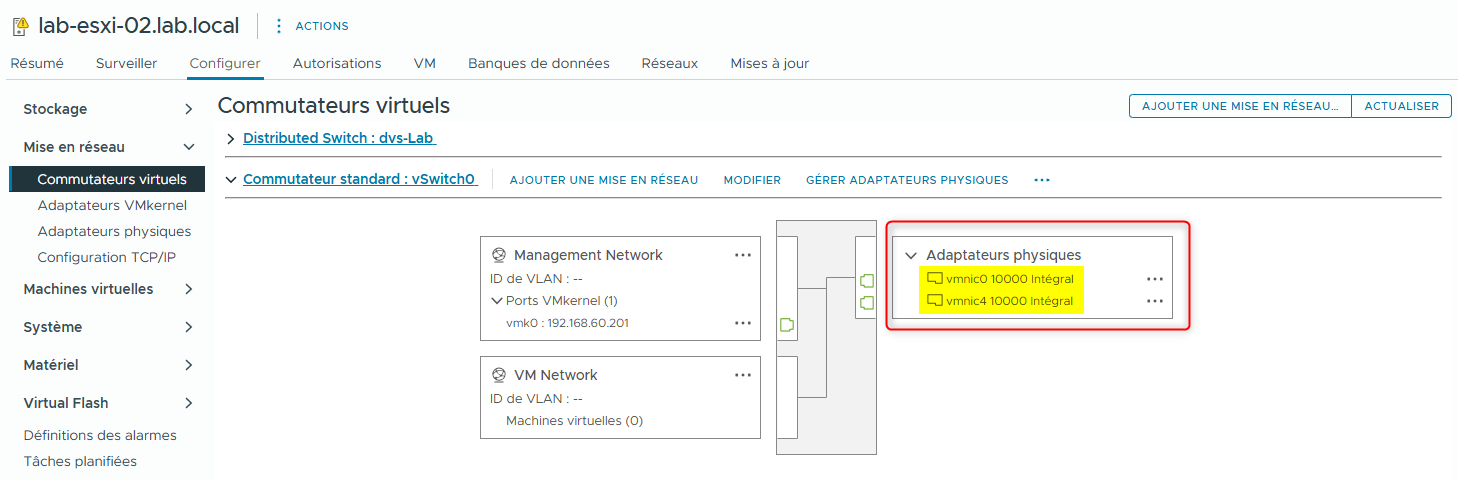
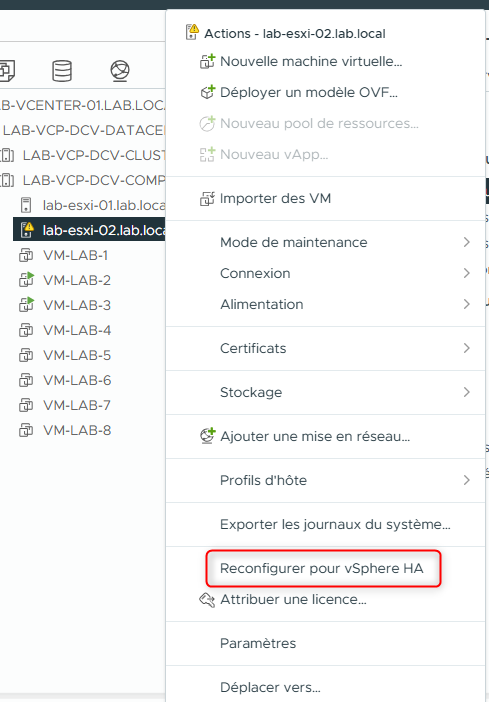
- Dans le volet de navigation, faites un clic droit sur lab-esxi-02.lab.local et sélectionnez Reconfigure for vSphere HA.
Attendez que la tâche de reconfiguration se termine.
- Vérifiez qu’aucun problème de configuration n’est listé pour vSphere HA.
-
Dans le volet de navigation, sélectionnez LAB-VCP-DCV-COMPUTE-01.
-
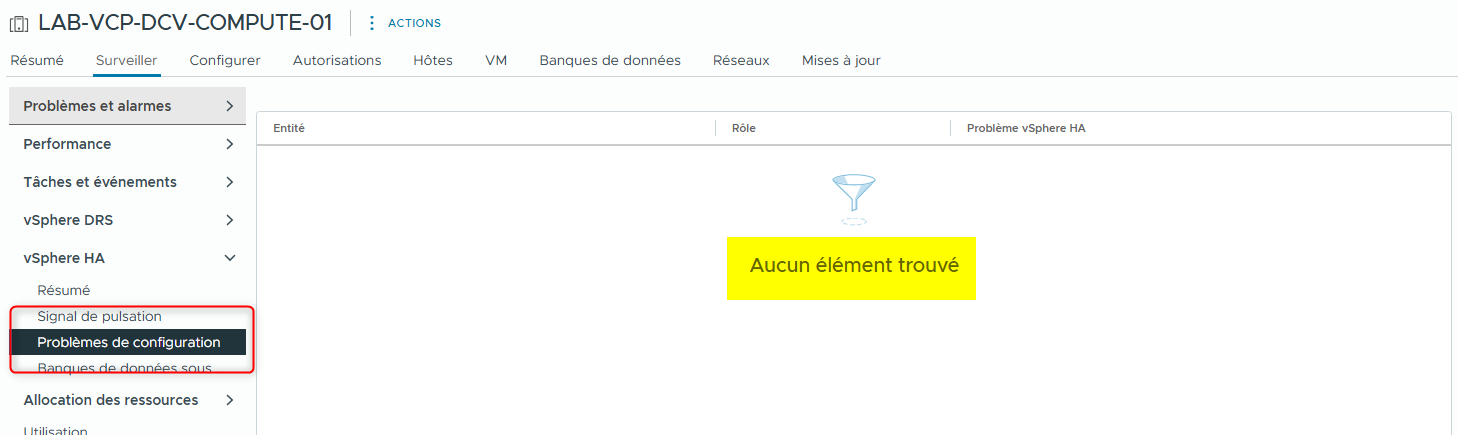
Dans l’onglet Monitor, sélectionnez Configuration Issues sous vSphere HA.
-
Cliquez sur l’icône Refresh en haut de la fenêtre.

- Vérifiez que l’avertissement concernant la redondance du réseau de management pour lab-esxi-02.lab.local disparaît.
¶ Tâche 4 : Tester la fonctionnalité vSphere HA
Vous configurez vSphere HA pour surveiller l’environnement du cluster et détecter les défaillances matérielles.
Lorsqu’une panne d’un hôte ESXi est détectée, vSphere HA redémarre automatiquement les machines virtuelles sur les autres hôtes du cluster.
- Dans le volet de navigation, sélectionnez LAB-VCP-DCV-COMPUTE-01 et cliquez sur l’onglet Monitor.
- Sous vSphere HA, sélectionnez Summary et notez le nom de l’hôte principal.
- Vérifiez que l’hôte principal contient une ou plusieurs machines virtuelles sous tension.
-
Sélectionnez l’hôte principal dans le volet de navigation.
-
Dans le volet de droite, cliquez sur l’onglet VMs et vérifiez que Virtual Machines est sélectionné.
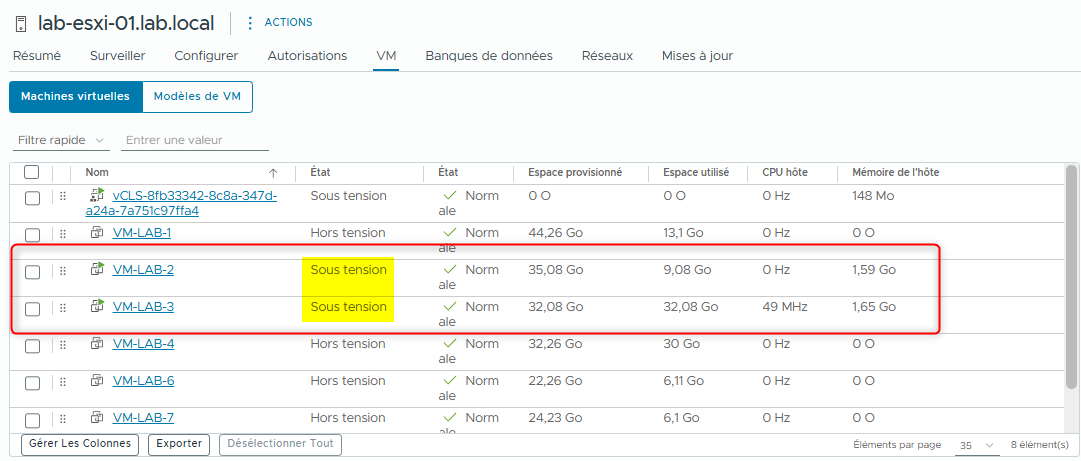
- Si toutes les machines virtuelles sont hors tension sur l’hôte principal, mettez au moins une machine virtuelle sous tension.
- Notez le nom d’une ou plusieurs machines virtuelles sous tension sur l’hôte principal.
Dans mon lab, les VMs suivantes sont sous tension :
- VM-LAB-2
- VM-LAB-3
-
Simulez une panne d’hôte en redémarrant l’hôte principal du cluster.
IMPORTANT
Assurez-vous de redémarrer le système. Ne pas l’arrêter.
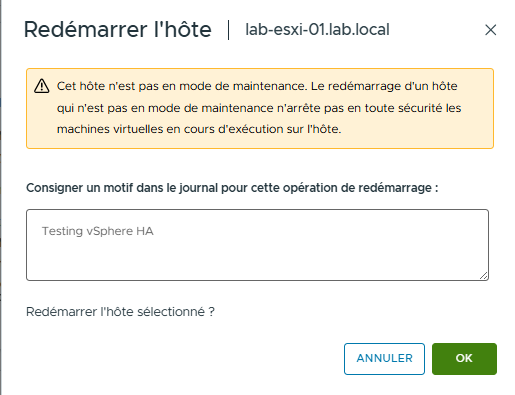
- Dans le volet de navigation, faites un clic droit sur l’hôte ESXi principal et sélectionnez Power > Reboot.
Un message d’avertissement apparaît indiquant que vous avez choisi de redémarrer un hôte qui n’est pas en mode maintenance.
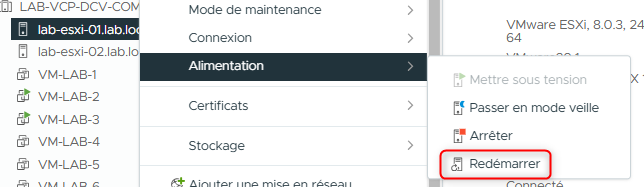
- Saisissez Testing vSphere HA comme raison du redémarrage et cliquez sur OK.
- Observez les événements qui se produisent pendant la récupération du cluster vSphere HA suite à la panne de l’hôte.
-
Sélectionnez LAB-VCP-DCV-COMPUTE-01 dans le volet de navigation et cliquez sur l’onglet Monitor dans le volet de droite.
-
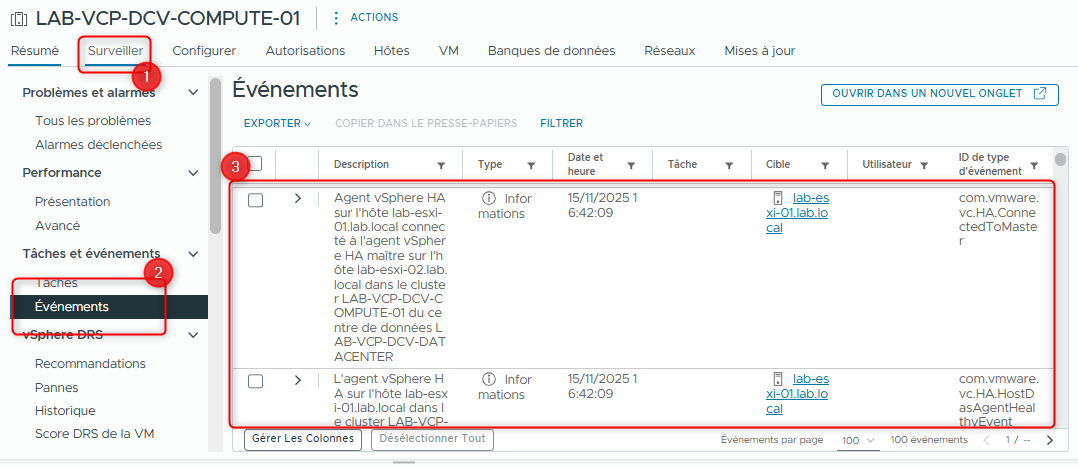
Sous Tasks and Events, sélectionnez Events.
Les entrées du cluster sont triées par date et heure. Notez les entrées qui apparaissent lors de la détection de la panne de l’hôte.
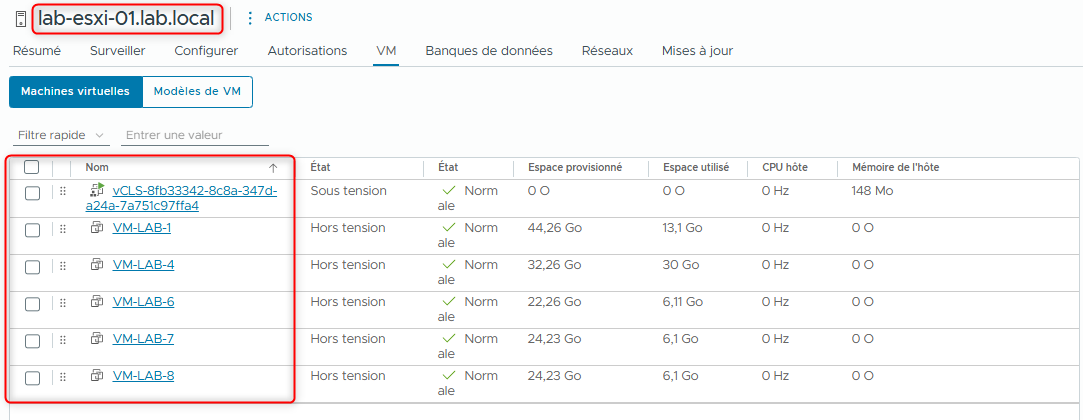
- Dans le volet de navigation, sélectionnez l’hôte que vous avez redémarré et cliquez sur l’onglet VMs dans le volet de droite.
¶ Question :
- Q1. Voyez-vous les machines virtuelles qui étaient en cours d’exécution sur cet hôte (l’hôte principal d’origine) et dont vous avez noté les noms ?
¶ Réponse :
- R1. Non. Vous devrez peut-être actualiser l’écran. Les machines virtuelles qui s’exécutaient auparavant sur cet hôte sont maintenant en cours d’exécution sur l’hôte restant dans le cluster.
-
Dans le volet de navigation, sélectionnez LAB-VCP-DCV-COMPUTE-01.
-
Dans le volet de droite, cliquez sur l’onglet Monitor.
-
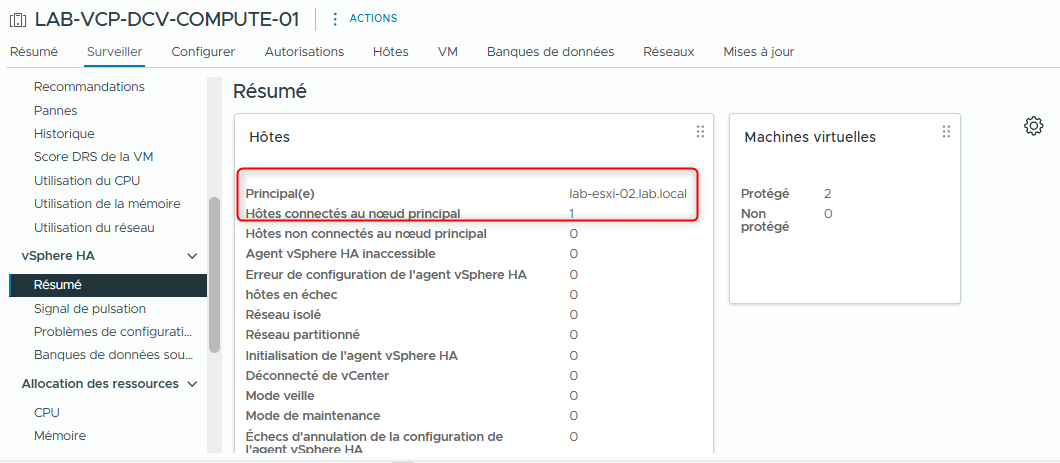
Sous vSphere HA, sélectionnez Summary.
¶ Question :
- Q2. L’hôte principal a-t-il changé ?
¶ Réponse :
- R2. Oui. L’hôte secondaire est élu comme nouveau hôte principal.
- Surveillez l’hôte ESXi principal d’origine dans le volet de navigation jusqu’à ce qu’il soit de nouveau entièrement opérationnel.
Il faut quelques minutes pour que l’hôte principal d’origine redevienne pleinement fonctionnel.
¶ Tâche 5 : Afficher l’utilisation des ressources du cluster vSphere HA
Vous examinez les informations d’utilisation CPU et mémoire du cluster LAB-VCP-DCV-COMPUTE-01.
- Dans le volet de navigation, sélectionnez LAB-VCP-DCV-COMPUTE-01 et cliquez sur l’onglet Monitor dans le volet droit.
- Examinez les informations de réservation CPU pour le cluster.
- Dans le volet droit, sous Resource Allocation, sélectionnez CPU.
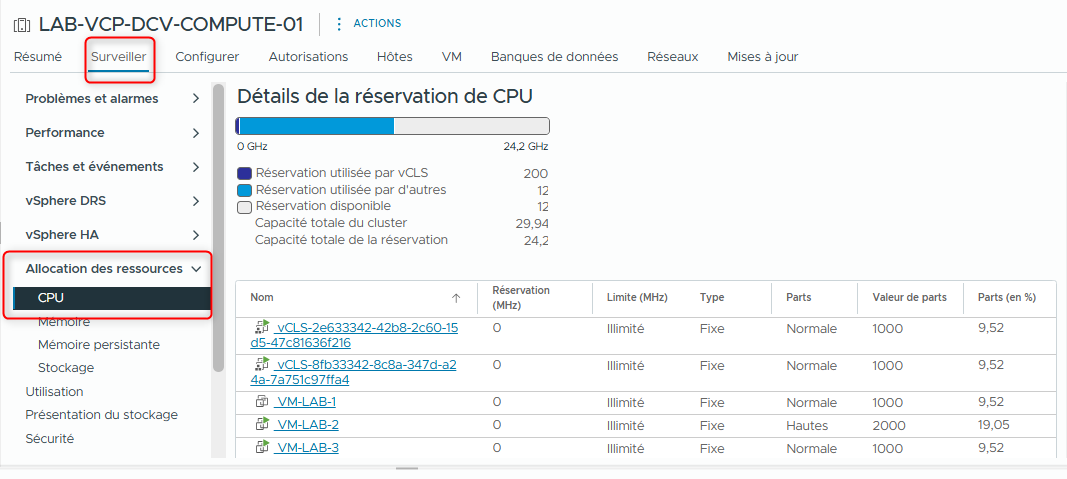
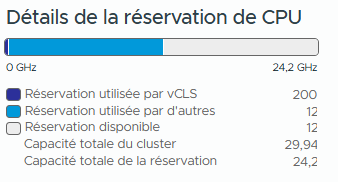
-
Relevez les informations pour le cluster.
- Used Reservation by other
- Available Reservation
- Total Reservation Capacity
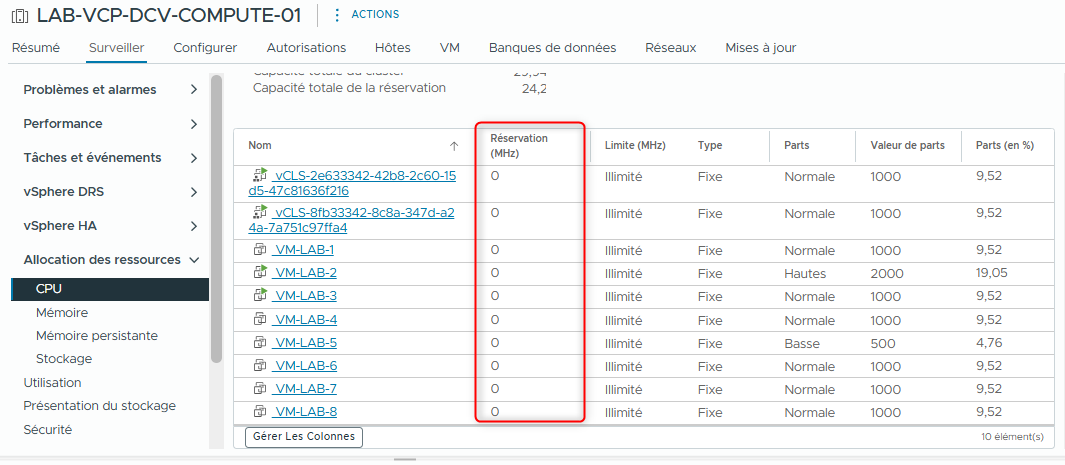
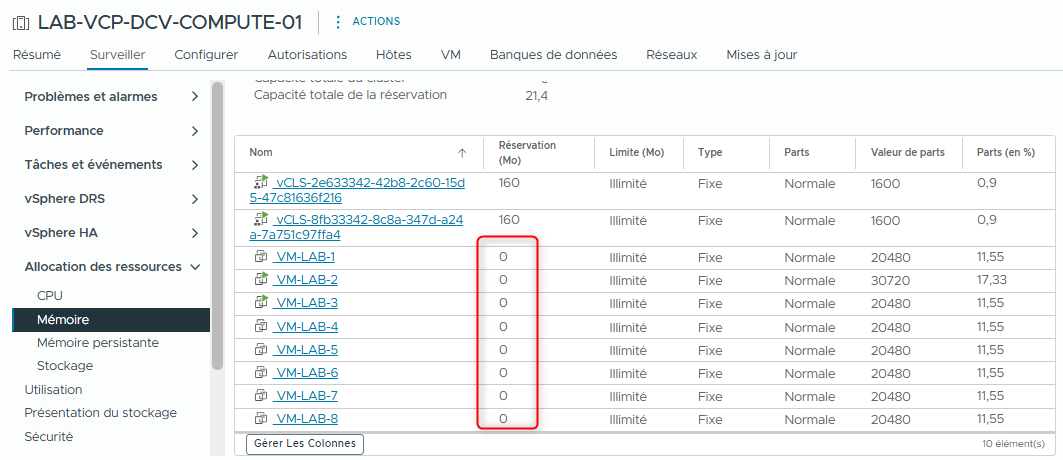
- Vérifiez que la réservation CPU n’est pas définie sur les machines virtuelles.
La colonne Reservation affiche 0 (MHz).
- Examinez les informations de réservation mémoire pour le cluster.
-
Sous Resource Allocation, sélectionnez Memory et relevez les informations pour le cluster.
- Used Reservation by other
- Available Reservation
- Total Reservation Capacity
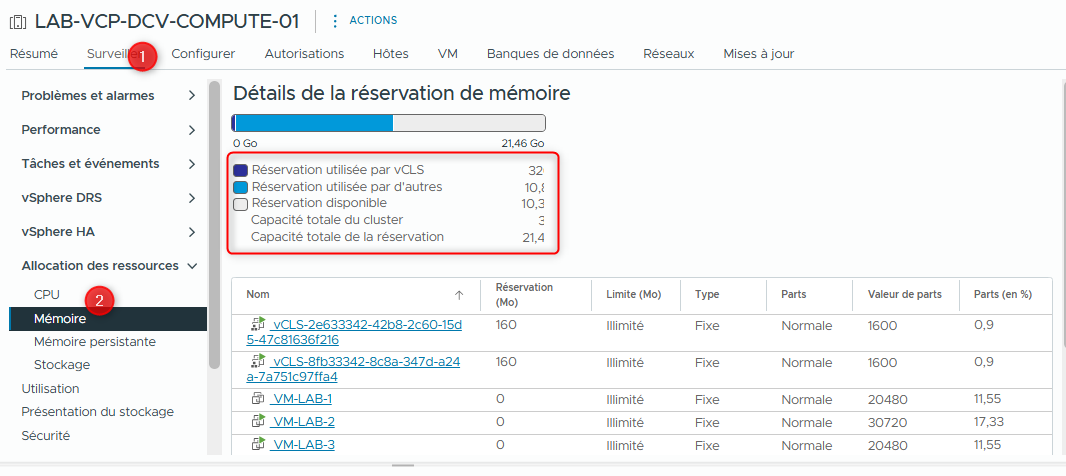
- Vérifiez que la réservation mémoire n’est pas définie sur les machines virtuelles.
La colonne Reservation affiche 0 (MB).
¶ Tâche 6 : Configurer le pourcentage de dégradation des ressources à tolérer
Dans votre cluster vSphere HA, vous spécifiez le pourcentage de dégradation des ressources à tolérer et vous vérifiez qu’un message apparaît lorsque le seuil de réduction est atteint.
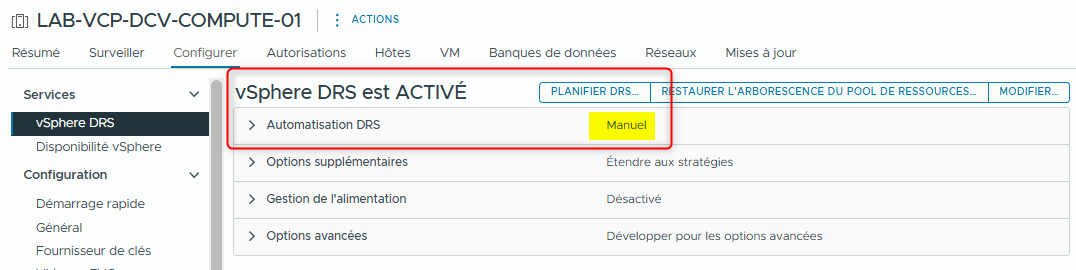
vSphere DRS doit être activé pour utiliser cette option de contrôle d’admission.
- Vérifiez que vSphere DRS est activé sur LAB-VCP-DCV-COMPUTE-01.
- Dans le volet droit, sélectionnez l’onglet Configure.
- vSphere DRS doit être activé. Le niveau d’automatisation est défini sur Manual.
- Pour vSphere HA, configurez le pourcentage de dégradation des ressources à tolérer.
-
Dans le volet droit, sous Services, sélectionnez vSphere Availability.
-
Cliquez sur le premier bouton EDIT, à côté de vSphere HA.
La fenêtre Edit Cluster Settings apparaît.
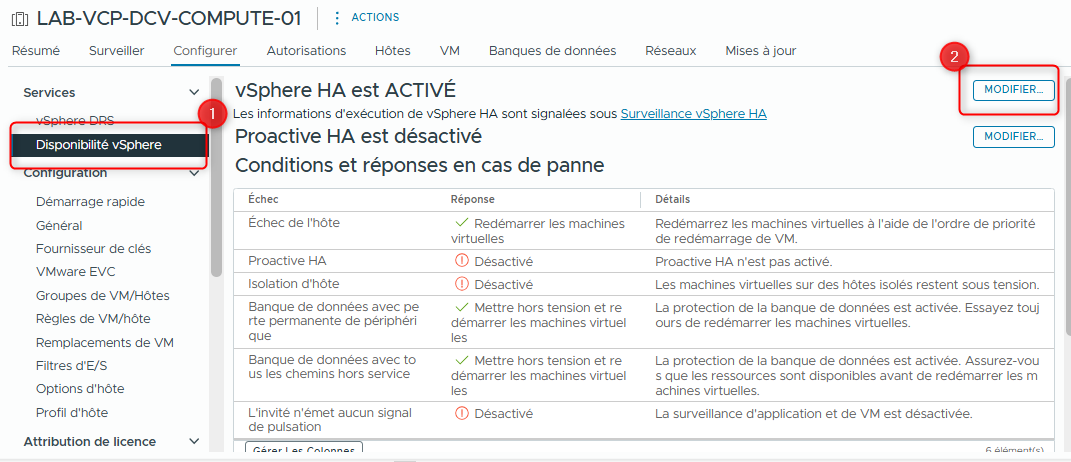
- Cliquez sur l’onglet Admission Control.
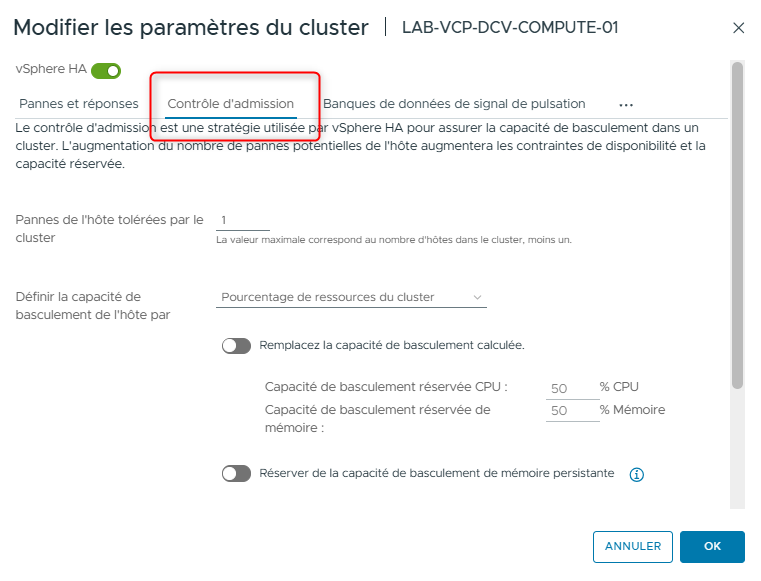
- Dans la zone de texte Performance degradation VMs tolerate, saisissez 0.
Si vous réduisez le seuil à 0 %, un avertissement est généré lorsque l’utilisation du cluster dépasse la capacité disponible du cluster.
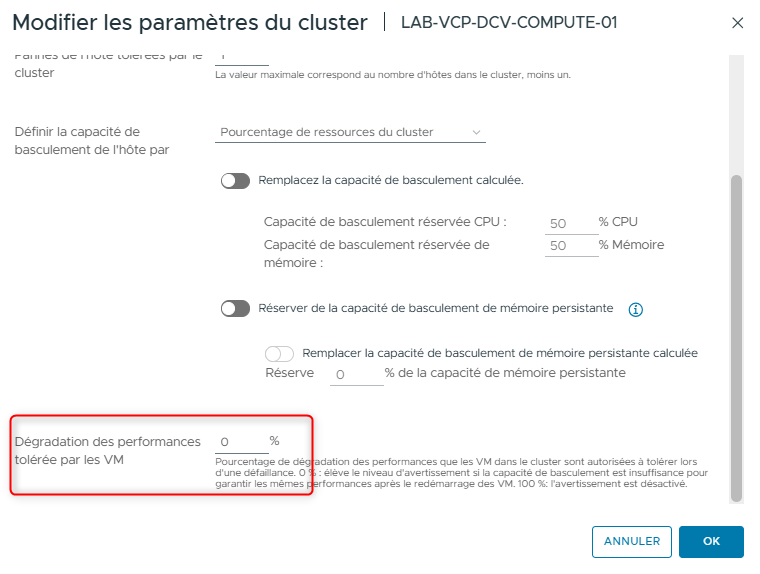
- Cliquez sur OK.
- Générez de l’activité CPU en démarrant le script cpubusy sur certaines VM et en mettant sous tension d’autres VM.
-
Dans le volet de navigation, sélectionnez VM-LAB-5 et, dans le volet droit, cliquez sur l’onglet Summary.
-
Cliquez sur LAUNCH WEB CONSOLE pour ouvrir la console de la VM.
-
Ouvrez un Terminal Linux.
-
Saisissez cd Desktop pour accéder au dossier Desktop.
-
Saisissez ./cpubusy.pl pour démarrer le script cpubusy.
Laissez le script s’exécuter pendant quelques minutes.

- Répétez ces étapes pour VM-LAB-2.

- Mettez sous tension les VM VM-LAB-1 et VM-LAB-3, en vous assurant de les placer sur le même hôte que VM-LAB-2 et VM-LAB-5.
- Vérifiez qu’un message apparaît concernant les ressources de basculement configurées dans le cluster LAB-VCP-DCV-COMPUTE-01.
- Dans le volet de navigation, sélectionnez LAB-VCP-DCV-COMPUTE-01 et cliquez sur l’onglet Summary dans le volet droit.
Vous devriez voir un message informatif indiquant :
Running VMs utilization cannot satisfy the configured failover resources on the cluster LAB-VCP-DCV-COMPUTE-01 in LAB-VCP-DCV-DATACENTER.
Vous devrez peut-être attendre quelques minutes pour que le message apparaisse.

-
Fermez les consoles de VM-LAB-2 et VM-LAB-5.
-
Arrêtez toutes les VM que vous avez mises sous tension.
-
Dans le vSphere Client, cliquez sur l’icône Refresh en haut de la fenêtre.

- Vérifiez que le message concernant les ressources de basculement configurées n’apparaît plus dans l’onglet Summary du cluster.

Lab précédent : Lab 24 : Mise en œuvre des clusters vSphere DRS
Lab suivant : Lab 26 : Utilisation de vSphere Lifecycle Manager