¶ Importance
La plupart des organisations dépendent de services informatiques tels que la messagerie électronique, les bases de données et les applications web. La défaillance de ces services peut entraîner une perte de productivité et de revenus.
En comprenant et en utilisant vSphere HA, vous pouvez configurer des services informatiques hautement disponibles, ce qui est essentiel pour qu’une organisation reste compétitive dans les environnements commerciaux contemporains. De plus, en développant des compétences dans l’utilisation de vSphere DRS, vous pouvez améliorer les niveaux de service en garantissant des ressources appropriées aux machines virtuelles (VMs).
¶ Leçons du module
- Vue d’ensemble des clusters vSphere
- vSphere Distributed Resource Scheduler
- Introduction à vSphere High Availability
- Architecture de vSphere High Availability
- Configuration de vSphere High Availability
¶ Leçon 1 : Vue d’ensemble des clusters vSphere
¶ Objectifs d’apprentissage
• Créer un cluster vSphere
• Identifier les options de cluster que vous pouvez configurer avec Cluster Quickstart
• Afficher les informations sur un cluster vSphere
¶ À propos des clusters vSphere
Un cluster est utilisé dans vSphere pour partager des ressources physiques entre un groupe d’hôtes ESXi.
vCenter gère les ressources d’un cluster comme un pool unique de ressources.
Vous pouvez créer un ou plusieurs clusters en fonction de l’objectif que chaque cluster doit remplir, par exemple :
• Management
• Production
• Compute
Un cluster peut contenir jusqu’à 96 hôtes ESXi.
Dans cette capture d’écran, cinq clusters sont affichés : SA-Compute-01, SA-Compute-02, SA-Management, SB-Development et SB-Management.
Pour prendre en charge 96 hôtes par cluster, vSphere 7 Update 1 ou version ultérieure est requis.
¶ Création d’un cluster vSphere
Vous pouvez créer un cluster en lui attribuant un nom et en sélectionnant les services de cluster appropriés.
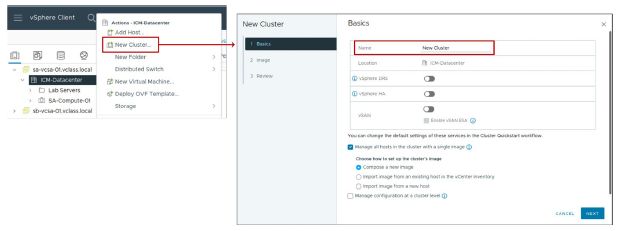
Vous pouvez activer les services suivants dans un cluster vSphere :
- vSphere HA, pour la haute disponibilité
- vSphere DRS, pour le placement des VM et l’équilibrage de charge
- vSAN, pour le stockage défini par logiciel
Vous pouvez également gérer les mises à jour des hôtes en utilisant des images. Avec vSphere Lifecycle Manager, vous pouvez mettre à jour collectivement tous les hôtes du cluster en utilisant une image ESXi spécifiée.
¶ À propos de Cluster Quickstart
Après avoir créé un cluster, vous pouvez utiliser le workflow Cluster Quickstart pour configurer le cluster.
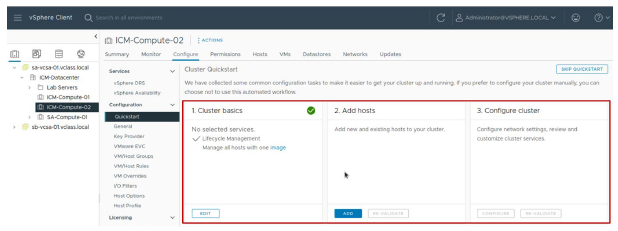
¶ Le workflow Cluster Quickstart
Le workflow Cluster Quickstart vous guide tout au long du processus de déploiement des clusters. Il couvre tous les aspects de la configuration initiale, tels que les paramètres d’hôtes, de réseau et de vSphere. Avec Cluster Quickstart, vous pouvez également ajouter des hôtes supplémentaires à un cluster dans le cadre de l’expansion continue des clusters.
Cluster Quickstart réduit le temps nécessaire à la configuration d’un cluster.
Le workflow inclut les tâches suivantes :
- Configuration des services tels que vSphere HA, vSphere DRS et vSAN
- Vérification de la compatibilité matérielle et logicielle
- Déploiement de vSphere Distributed Switches
- Configuration des paramètres réseau pour vSphere vMotion et vSAN
- Création d’un vSAN stretched cluster ou de vSAN fault domains
- Vérification de la cohérence de la configuration NTP dans tout le cluster
Pour plus d’informations sur la création de clusters, consultez vCenter Server and Host Management à l’adresse suivante : https://docs.vmware.com/en/VMware-vSphere/index.html
¶ Cluster Quickstart : Activation des services
La première étape du workflow Cluster Quickstart consiste à vérifier que les services de cluster corrects sont sélectionnés.
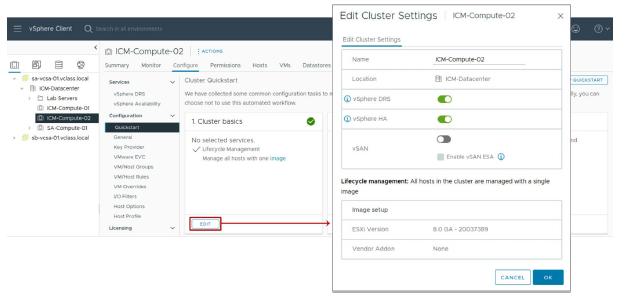
Le volet Cluster basics vous permet de configurer les informations suivantes :
- Modifier le nom du cluster.
- Activer ou désactiver les services vSphere DRS, vSphere HA et vSAN.
- Sélectionner l’image que vSphere Lifecycle Manager doit utiliser pour gérer les hôtes du cluster.
Pour plus d’informations sur la création de clusters, consultez la documentation vCenter Server and Host Management à l’adresse : https://docs.vmware.com/en/VMware-vSphere/index.html
¶ Cluster Quickstart : Ajout d’hôtes
La deuxième étape du workflow Cluster Quickstart consiste à ajouter de nouveaux hôtes ou des hôtes existants au cluster.
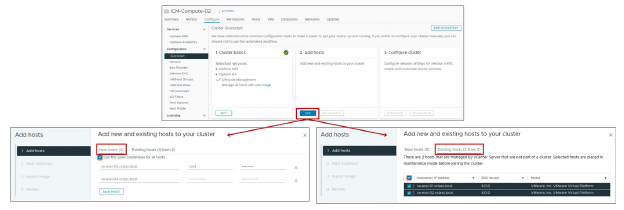
Le volet Add hosts vous permet d’ajouter des hôtes ESXi au cluster.
Sélectionnez New hosts pour ajouter des hôtes à l’inventaire et au cluster simultanément. Pour chaque hôte que vous ajoutez au cluster, vous devez saisir l’adresse IP ou le FQDN de l’hôte.
Sélectionnez Existing hosts pour ajouter au cluster des hôtes déjà présents dans l’inventaire.
Après l’ajout des hôtes, le workflow affiche le nombre total d’hôtes présents dans le cluster et fournit une validation de l’état de santé (health check) de ces hôtes.
¶ Cluster Quickstart : Configuration du cluster
La troisième étape consiste à configurer les paramètres réseau des hôtes et à personnaliser les services du cluster.
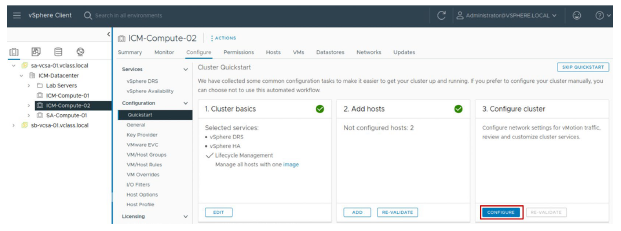
Si vous cliquez sur SKIP QUICKSTART, vous pouvez configurer manuellement votre cluster en utilisant les menus du vSphere Client.
En sautant le workflow Cluster Quickstart, vous ne pouvez pas le restaurer pour le cluster actuel.
Tous les hôtes ajoutés à ce cluster doivent alors être configurés manuellement.
¶ Configuration d’un cluster : Distributed Switches
Pour configurer un cluster, vous pouvez :
- Sélectionner jusqu’à trois distributed switches.
- Sélectionner un réseau pour vSphere vMotion.
- Sélectionner au moins un adaptateur physique.
Vous pouvez également configurer les paramètres réseau ultérieurement.
¶ Configuration d’un cluster : Distributed Switches
Pour configurer un cluster, vous pouvez :
- Sélectionner jusqu’à trois distributed switches.
- Sélectionner un réseau pour vSphere vMotion.
- Sélectionner au moins un adaptateur physique.
Vous pouvez également configurer les paramètres réseau ultérieurement.
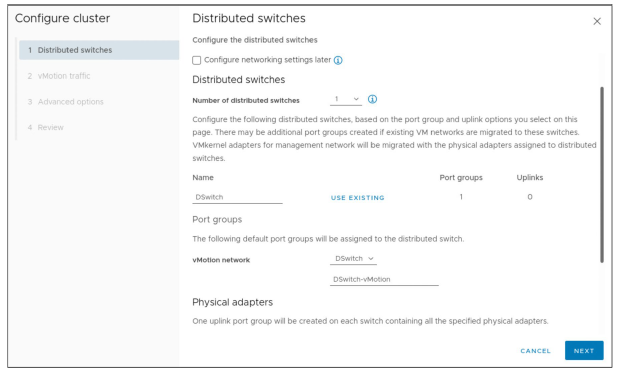
Vous pouvez cocher la case Configure networking settings later pour configurer uniquement les paramètres par défaut des services de cluster et masquer toutes les options liées au host networking.
Cependant, en sélectionnant cette option, vous ne pouvez pas effectuer la configuration réseau en utilisant l’assistant Configure cluster.
¶ Configuration d’un cluster : Trafic vSAN et vMotion
Si vous avez sélectionné vSphere DRS, il vous est demandé de saisir les informations d’adresse IP pour le réseau vSphere vMotion.
Si vous avez sélectionné vSAN, il vous est demandé de saisir les informations d’adresse IP pour le réseau vSAN.
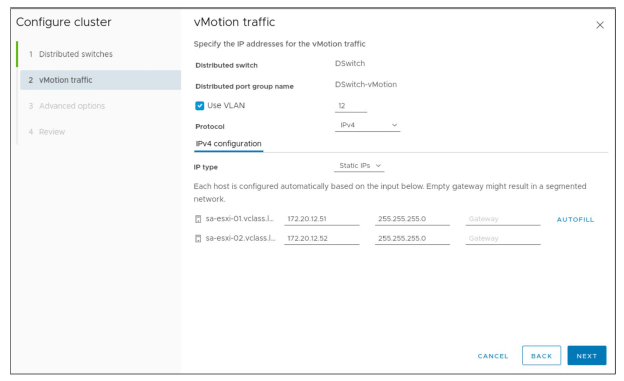
Sur la page du trafic vMotion, si les informations IP des hôtes ESXi sont similaires, vous pouvez saisir les informations pour le premier hôte puis cliquer sur AUTOFILL afin de remplir automatiquement les champs des hôtes suivants.
¶ Configuration d’un Cluster : Options avancées
Vous obtenez différents paramètres en fonction des services de cluster qui sont activés :
• High Availability (optionnel)
• Distributed Resource Scheduler (optionnel)
• Host Options
• Enhanced vMotion Compatibility
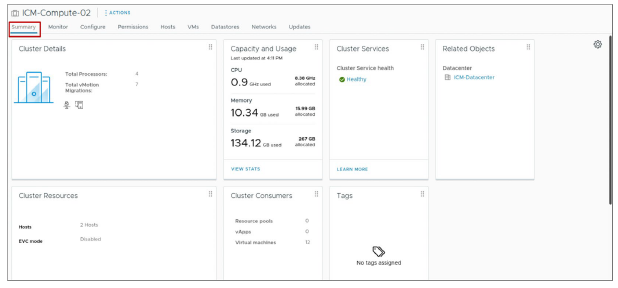
¶ Affichage des informations de synthèse du cluster
L’onglet Summary fournit une vue rapide des informations sur les ressources d’un cluster et sur ses consommateurs.
¶ Surveillance des ressources du cluster
Vous pouvez afficher les détails de l’allocation CPU et mémoire.
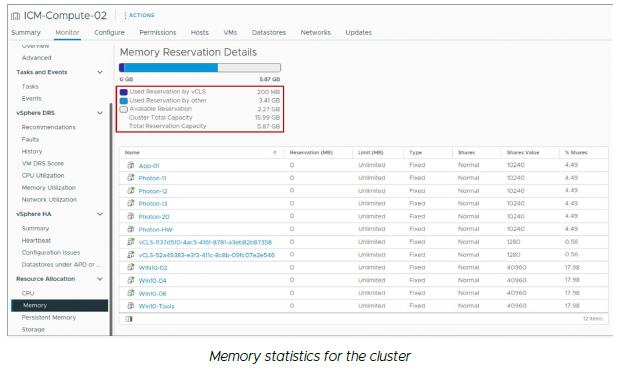
Vous pouvez afficher un rapport du CPU total du cluster, de la mémoire, de la mémoire overhead, de la capacité de stockage, de la capacité réservée par les VMs, ainsi que de la capacité encore disponible.
¶ Machines virtuelles des services de cluster vSphere
Jusqu’à trois vSphere Cluster Service VMs sont présentes dans chaque cluster vSphere.
Ces VMs sont nécessaires pour maintenir la santé et la disponibilité des services de cluster tels que vSphere DRS et vSphere HA.
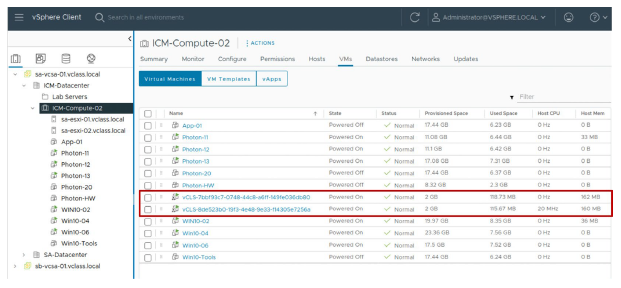
Machines virtuelles des services de cluster vSphere (vSphere Cluster Service VMs)
Les vSphere Cluster Service VMs sont déployées dans un cluster lors de la création du cluster et après l’ajout d’hôtes à ce cluster.
Une vSphere Cluster Service VM est déployée à partir d’un OVA avec un profil minimal installé de Photon OS.
Le vSphere Cluster Services Manager est un service de vCenter qui gère les ressources, l’état d’alimentation et la disponibilité de ces VMs.
Tout impact sur l’état d’alimentation ou sur les ressources de ces VMs peut dégrader la santé des vSphere Cluster Services et entraîner l’arrêt du fonctionnement de vSphere DRS dans le cluster.
Dans le vSphere Client, les vSphere Cluster Service VMs ne sont pas visibles dans la vue Hosts and Clusters.
Cependant, vous pouvez visualiser ces VMs dans l’onglet VMs du cluster.
Vous pouvez également les voir dans la vue VMs and Templates de l’inventaire.
Le cluster vSphere affiche un message d’alerte si des vSphere Cluster Service VMs saines ne sont pas disponibles dans le cluster.
Si des vSphere Cluster Service VMs sont arrêtées manuellement, elles sont automatiquement rallumées par vCenter.
¶ Revue des objectifs d’apprentissage
- Créer un vSphere cluster
- Identifier les options du cluster que vous pouvez configurer avec Cluster Quickstart
- Consulter les informations concernant un vSphere cluster
¶ Leçon 2 : vSphere Distributed Resource Scheduler
¶ Objectifs d’apprentissage
- Décrire les fonctions d’un vSphere DRS cluster
- Expliquer comment vSphere DRS détermine le placement des VMs sur les hôtes du cluster
- Identifier les cas d’utilisation des paramètres vSphere DRS
- Configurer vSphere DRS dans un cluster
- Surveiller un vSphere DRS cluster
¶ À propos de vSphere Distributed Resource Scheduler
vSphere Distributed Resource Scheduler (DRS) aide à améliorer l’allocation des ressources entre tous les hôtes d’un cluster.
Cas d’utilisation de vSphere DRS :
- Placement initial lors de l’allumage d’une VM
- Répartition de charge (load balancing)
- Migration des VMs lorsqu’un hôte ESXi est placé en mode maintenance
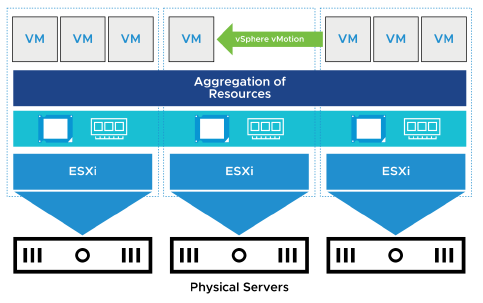
vSphere DRS agrège la capacité de calcul d’un ensemble de serveurs en pools de ressources logiques.
Lorsqu’une VM est mise sous tension dans le cluster, en mode Fully Automated, DRS place automatiquement la VM sur l’hôte disposant du plus de ressources disponibles. En mode Partially Automated ou Manual, DRS fournit des recommandations pour l’allocation des ressources.
DRS cherche à améliorer l’utilisation des ressources du cluster en effectuant des migrations automatiques de VMs grâce à vSphere vMotion. Proposant des recommandations de migration de VMs.
Avant qu’un hôte ESXi ne passe en maintenance mode les VMs qui s’exécutent sur cet hôte doivent être migrées vers un autre hôte (manuellement ou automatiquement via DRS), arrêtées ou suspendues.
¶ vSphere DRS : Focalisé sur les VMs
vSphere DRS est centré sur les VMs :
- Tant qu’une VM est sous tension, vSphere DRS agit individuellement sur chaque VM afin de s’assurer que ses besoins en ressources soient respectés.
- vSphere DRS calcule un score pour chaque VM et fournit des recommandations (ou effectue des migrations) pour répondre aux besoins en ressources de la VM.
L’algorithme DRS recommande la destination optimale des VMs afin d’obtenir les meilleures performances.
Si le cluster est en Fully Automated mode, DRS applique directement ces recommandations et migre automatiquement les VMs vers l’hôte le plus adapté, sur la base de calculs effectués chaque minute.
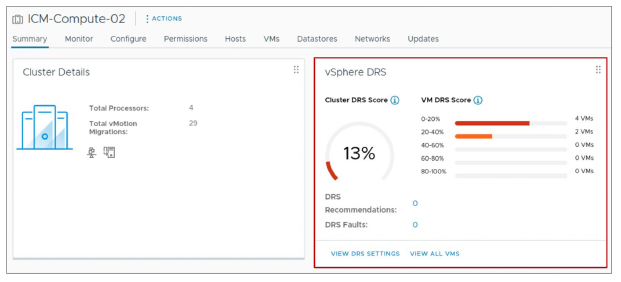
¶ À propos du score DRS de la VM
Le VM DRS score mesure dans quelle mesure les besoins en ressources d’une VM sont satisfaits.
- Un score proche de 0 % indique une forte contention des ressources.
- Un score proche de 100 % indique une faible ou aucune contention des ressources.
Un VM DRS score est calculé à partir des métriques CPU, mémoire et réseau d’une VM.
DRS utilise ces métriques pour évaluer la santé ou le niveau de performance de la VM.
À partir de vSphere 7 et versions ultérieures, l’algorithme DRS s’exécute toutes les minutes.
Le Cluster DRS Score correspond au dernier résultat calculé par DRS et est classé dans l’un des cinq intervalles (buckets). Ces intervalles représentent des plages de 20 % chacune 0-20%, 20-40%, 40-60%, 60-80% et 80-100%
¶ Liste des VM DRS Score
L’onglet Monitor du cluster affiche la liste des VM DRS Score ainsi que des métriques plus détaillées pour toutes les VMs présentes dans le cluster.
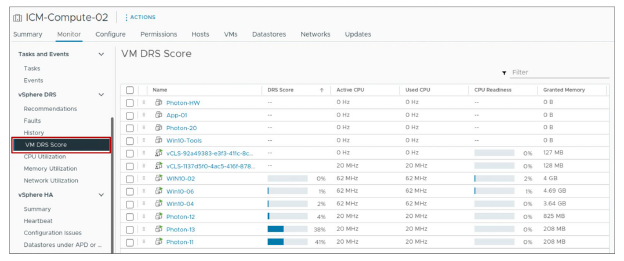
La page VM DRS Score affiche les valeurs suivantes pour les VMs qui sont allumées (powered on) :
- DRS Score
- Active CPU
- Used CPU
- CPU Readiness
- Granted Memory
- Swapped Memory
- Ballooned Memory
¶ Exigences pour un cluster vSphere DRS
Les hôtes ESXi ajoutés à un cluster vSphere DRS doivent respecter certaines exigences pour utiliser correctement les fonctionnalités du cluster :
-
Pour utiliser vSphere DRS pour l’équilibrage de charge, les hôtes du cluster doivent faire partie d’un réseau vSphere vMotion :
— Si les hôtes ne font pas partie d’un réseau vSphere vMotion, vSphere DRS peut toujours fournir des recommandations de placement initial.
— vSphere DRS fonctionne de manière optimale si les VMs respectent les exigences de vSphere vMotion. -
Configurer tous les hôtes gérés pour utiliser un stockage partagé.
¶ Paramètres vSphere DRS : Niveau d’automatisation
Vous pouvez configurer le niveau d’automatisation pour :
- le placement initial des VMs,
- l’équilibrage dynamique pendant l’exécution des VMs.
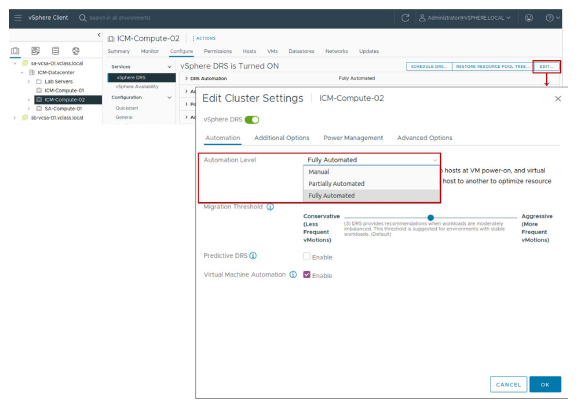
Le niveau d’automatisation détermine si vSphere DRS fait des recommandations de migration ou place automatiquement les VMs sur les hôtes. vSphere DRS prend des décisions de placement lorsqu’une VM est mise sous tension et lorsque les VMs doivent être rééquilibrées entre les hôtes du cluster.
Les niveaux d’automatisation suivants sont disponibles :
• Manual : Lorsque vous mettez une VM sous tension, vSphere DRS affiche une liste d’hôtes recommandés sur lesquels placer la VM. Pour améliorer le score global DRS du cluster, vSphere DRS affiche des recommandations pour la migration manuelle des VMs.
• Partially automated : Lorsque vous mettez une VM sous tension, vSphere DRS la place sur l’hôte le mieux adapté. Pour améliorer le score global DRS du cluster, vSphere DRS affiche des recommandations pour la migration manuelle des VMs.
• Fully automated : Lorsque vous mettez une VM sous tension, vSphere DRS la place sur l’hôte le mieux adapté. Pour améliorer le score global DRS du cluster, vSphere DRS migre automatiquement les VMs entre les hôtes.
¶ Paramètres vSphere DRS : Seuil de migration
Le seuil de migration détermine à quel point vSphere DRS agit de manière agressive pour sélectionner la migration des VMs.
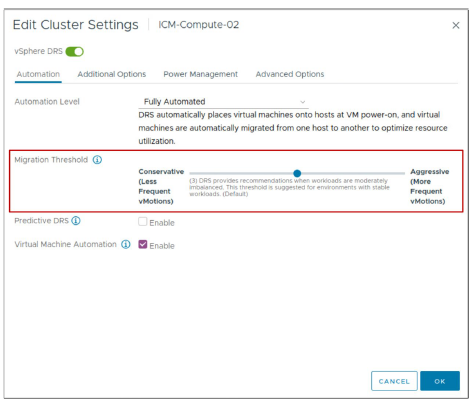
Les paramètres de seuil de migration suivants sont disponibles :
- Niveau 1 (Conservateur) : Applique uniquement les recommandations de priorité 1. vCenter applique uniquement les recommandations nécessaires pour satisfaire les exigences des VMs, comme les règles d’affinité et la mise en maintenance d’un hôte.
- Niveau 2 : Applique les recommandations de priorité 1 et de priorité 2. vCenter applique les recommandations qui promettent une amélioration significative du score global DRS du cluster.
- Niveau 3 (par défaut) : Applique les recommandations de priorité 1, de priorité 2 et de priorité 3. vCenter applique les recommandations qui promettent au moins une bonne amélioration du score global DRS du cluster.
- Niveau 4 : Applique les recommandations de priorité 1, 2, 3 et 4. vCenter applique les recommandations qui promettent même une amélioration modérée du score global DRS du cluster.
- Niveau 5 (Agressif) : Applique toutes les recommandations. vCenter applique les recommandations qui promettent même une légère amélioration du score global DRS du cluster.
¶ Paramètres vSphere DRS : Predictive DRS
Predictive DRS est utilisé pour prévoir la demande future et déterminer quand et où une forte utilisation des ressources se produit.
Pour prendre des décisions prédictives, le collecteur de données vSphere DRS récupère les données suivantes :
- Statistiques d’utilisation des ressources depuis les hôtes ESXi
- Statistiques d’utilisation prévues depuis le serveur VMware Aria Operations
Objectifs de Predictive DRS :
- Déplacer les VMs avant que leur score DRS ne baisse.
- Effectuer les migrations avant que les ressources des hôtes ne soient en contention.
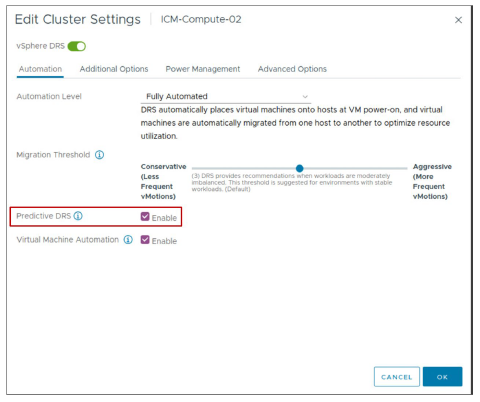
Les statistiques d’utilisation prédites ont toujours la priorité sur les statistiques d’utilisation actuelles.
¶ Affichage des paramètres vSphere DRS
Lorsque vous cliquez sur VIEW DRS SETTINGS, les principaux paramètres de vSphere DRS et leurs valeurs actuelles sont affichés.
Les paramètres vSphere DRS incluent :
• Automation level
• Migration threshold
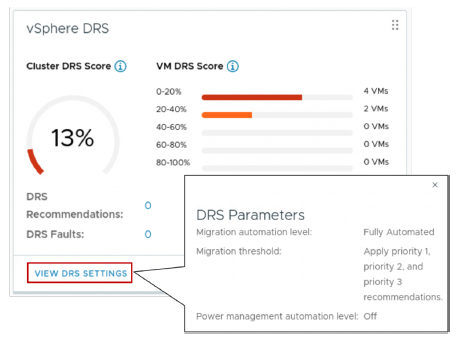
Pour afficher le volet vSphere DRS, allez dans l’onglet Summary du cluster.
¶ Paramètres vSphere DRS : Automatisation au niveau des VM
Vous pouvez personnaliser le niveau d’automatisation pour des VM individuelles dans un cluster afin d’outrepasser le niveau d’automatisation défini pour l’ensemble du cluster.
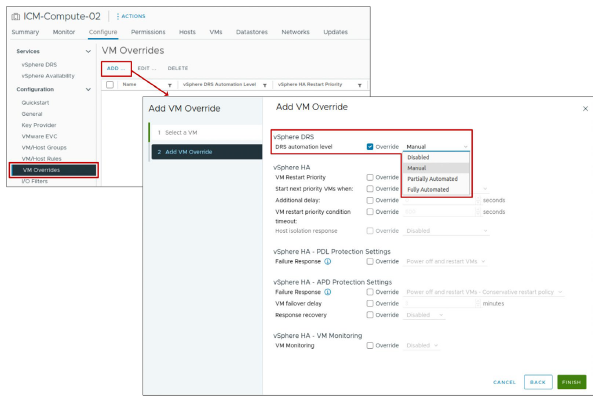
En définissant le niveau d’automatisation pour des VM individuelles, vous pouvez affiner l’automatisation afin de l’adapter à vos besoins.
Par exemple, vous pourriez avoir une VM particulièrement critique pour votre entreprise. Vous souhaitez avoir plus de contrôle sur son placement, vous définissez donc son niveau d’automatisation sur Manual.
Si le niveau d’automatisation d’une VM est défini sur Disabled, vSphere DRS ne migre pas la VM et ne fournit pas non plus de recommandations de placement initial ou de migration.
Choisissez le niveau d’automatisation en fonction de votre environnement et de votre niveau de confort si vous débutez avec les clusters vSphere DRS, vous pouvez choisir Partially Automated afin de garder un certain contrôle sur le déplacement des VM.
Lorsque vous êtes à l’aise avec le fonctionnement et le comportement de vSphere DRS, vous pouvez définir le niveau d’automatisation sur Fully Automated.
Vous pouvez définir le niveau d’automatisation sur Manual pour les VM sur lesquelles vous souhaitez garder plus de contrôle, par exemple vos VM critiques pour l’activité.
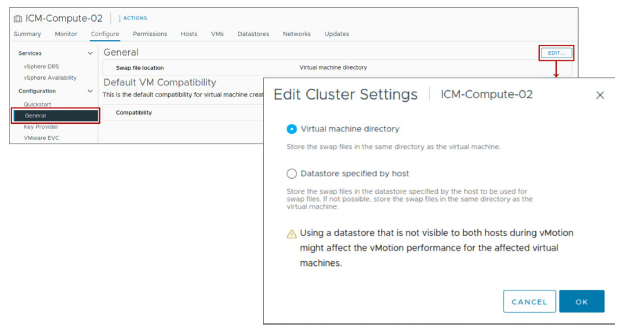
¶ vSphere DRS Settings: VM Swap File Location
Les hôtes ESXi peuvent être configurés pour placer les fichiers d’échange (swap files) des VM sur un datastore local.
Cependant, si vSphere DRS est configuré, il est recommandé de placer les fichiers d’échange des VM sur un datastore partagé.
Sur un datastore VMFS ou NFS, l’espace swap de la VM est constitué de deux fichiers swap.
Sur un datastore vSAN ou vSphere Virtual Volumes, les fichiers swap sont créés comme des objets séparés.
Deux fichiers swap sont créés par l’hôte ESXi lorsqu’une VM est mise sous tension.
Si ces fichiers ne peuvent pas être créés, la VM ne peut pas être démarrée.
Par défaut, les fichiers swap d’une VM se trouvent sur un datastore dans le dossier qui contient les autres fichiers de la VM.
Au lieu d’accepter la valeur par défaut, vous pouvez également utiliser les options suivantes :
- Utiliser les options de configuration par VM pour modifier le datastore vers un autre emplacement de stockage partagé.
- Utiliser le host-local swap, qui permet de spécifier un datastore stocké localement sur l’hôte. Vous pouvez swapper au niveau de chaque hôte. Cependant, cela peut entraîner une légère dégradation des performances pour vSphere vMotion, car les pages swappées vers un fichier swap local sur l’hôte source doivent être transférées sur le réseau vers l’hôte de destination. Actuellement, les datastores vSAN et vSphere Virtual Volumes ne peuvent pas être spécifiés pour le host-local swap.
¶ Paramètres vSphere DRS : Affinité de VM
Les règles d’affinité de machine virtuelle (VM) dans vSphere DRS spécifient que les VMs sélectionnées soient placées soit sur le même host, soit sur des hosts distincts :
- Affinity rules : Pour les VMs qui communiquent intensivement entre elles
- Anti-affinity rules : Pour les VMs où l’équilibrage de charge (load balancing) ou la haute disponibilité (high availability) est souhaité
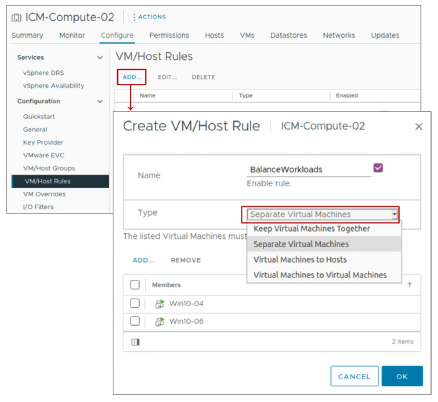
Après la création d’un cluster vSphere DRS, vous pouvez modifier ses propriétés pour créer des règles qui spécifient une affinité. Les types de règles suivants peuvent être créés :
- Affinity rules : vSphere DRS maintient certaines VMs ensemble sur le même host (par exemple, pour des raisons de performance).
- Anti-affinity rules : vSphere DRS s’assure que certaines VMs soient placées sur des hosts différents (par exemple, pour des raisons de disponibilité).
Si deux règles entrent en conflit, vous ne pouvez pas activer les deux.
Lorsque vous ajoutez ou modifiez une règle, et que le cluster est immédiatement en violation de cette règle, le cluster continue à fonctionner et tente de corriger la violation.
Pour les clusters vSphere DRS ayant un niveau d’automatisation manual ou partially automated, les recommandations de migration sont basées à la fois sur le respect des règles et sur l’équilibrage de charge (load balancing).
¶ Paramètres vSphere DRS : Groupes DRS
Les VM groups et les host groups sont utilisés pour définir les règles d’affinité VM-Host.
La règle d’affinité VM-Host spécifie si une VM peut ou ne peut pas être exécutée sur un host.
Types de groupes :
- VM group : Une ou plusieurs VMs
- Host group : Un ou plusieurs ESXi hosts
Une VM peut appartenir à plusieurs VM groups.
Un host peut appartenir à plusieurs host groups.
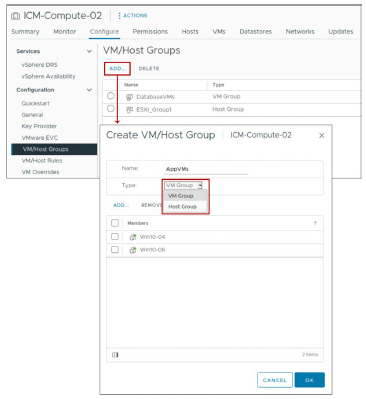
Pour faciliter l’administration, les virtual machines (VMs) peuvent être placées dans des VM groups ou des host groups.
Vous pouvez créer un ou plusieurs VM groups dans un cluster vSphere DRS, chacun composé d’une ou plusieurs VMs.
Un host group est composé d’un ou plusieurs ESXi hosts.
L’utilisation principale des VM groups et des host groups est d’aider à définir les règles d’affinité VM-Host.
¶ Paramètres vSphere DRS : Règles d’affinité VM-Host
Une règle d’affinité VM-Host :
- Définit une relation d’affinité (ou d’anti-affinité) entre un VM group et un host group
- Est soit une règle obligatoire (required rule), soit une règle préférentielle (preferential rule)
Options de règle :
- Must run on hosts in group : Doit s’exécuter sur les hosts du groupe
- Should run on hosts in group : Devrait s’exécuter sur les hosts du groupe
- Must not run on hosts in group : Ne doit pas s’exécuter sur les hosts du groupe
- Should not run on hosts in group : Ne devrait pas s’exécuter sur les hosts du groupe
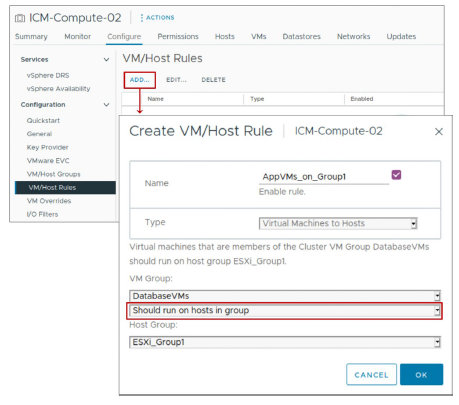
Une règle d’affinité ou d’anti-affinité VM-Host spécifie si les membres d’un VM group sélectionné peuvent s’exécuter sur les membres d’un host group spécifique.
Contrairement à une règle d’affinité pour VMs, qui définit une affinité (ou une anti-affinité) entre des VMs individuelles, une règle d’affinité VM-Host définit une relation d’affinité entre un groupe de VMs et un groupe de hosts.
Comme les règles d’affinité VM-Host sont basées sur le cluster, les VMs et les hosts inclus dans une règle doivent tous résider dans le même cluster.
Si une VM est retirée du cluster, elle perd son appartenance à tous les VM groups, même si elle est réintégrée ultérieurement dans le cluster.
¶ Règles d’affinité VM-Host préférentielles
Une règle préférentielle est appliquée de manière souple (softly enforced) et peut être violée si nécessaire.
Exemple : Séparer les VMs sur différents systèmes blade afin d’améliorer les performances.
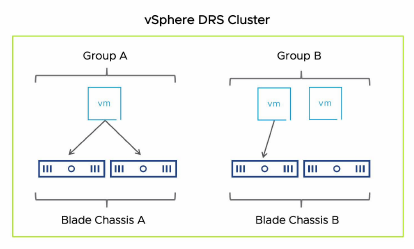
Les règles préférentielles peuvent être violées afin de permettre le bon fonctionnement de vSphere DRS, vSphere HA et VMware vSphere DPM.
Sur la diapositive, Group A et Group B sont des VM groups. Blade Chassis A et Blade Chassis B sont des host groups.
L’objectif est de forcer les VMs du Group A à s’exécuter sur les hosts du Blade Chassis A et de forcer les VMs du Group B à s’exécuter sur les hosts du Blade Chassis B.
Si les hosts tombent en panne, vSphere HA redémarre les VMs sur les autres hosts du cluster.
vSphere DRS déplace les VMs vers les autres hosts du cluster si les hosts sont placés en maintenance mode ou si des hosts supplémentaires sont nécessaires pour répondre aux besoins en ressources des VMs.
¶ Règles d’affinité VM-Host obligatoires
Une règle obligatoire (required rule) est appliquée de manière stricte et ne peut jamais être violée.
Exemple : Imposer une licence ISV basée sur le host.
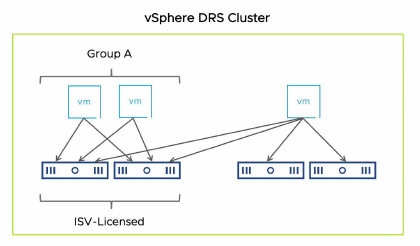
Une règle d’affinité VM-Host obligatoire (required rule) plutôt que préférentielle peut être utilisée lorsque le logiciel exécuté dans vos VMs est soumis à des restrictions de licence. Vous pouvez appliquer cette règle lorsque le logiciel exécuté dans vos VMs a des contraintes de licence.
Vous pouvez placer ces VMs dans un VM group. Ensuite, vous pouvez créer une règle qui exige que les VMs s’exécutent sur un host group contenant des hosts disposant des licences requises.
Lorsque vous créez une règle d’affinité VM-Host basée sur les exigences de licence ou de matériel du logiciel exécuté dans vos VMs, il est de votre responsabilité de vous assurer que les groupes sont correctement configurés.
La règle ne surveille pas le logiciel exécuté dans les VMs. Elle n’a pas non plus connaissance des licences tierces installées sur les ESXi hosts.
Sur la diapositive, Group A est un VM group. Vous pouvez forcer Group A à s’exécuter sur les hosts du groupe ISV-Licensed afin de garantir que les VMs de Group A s’exécutent sur des hosts disposant des licences requises.
Cependant, si les hosts du groupe ISV-Licensed tombent en panne, vSphere HA ne peut pas redémarrer les VMs de Group A sur des hosts qui ne font pas partie du groupe.
De même, si les hosts du groupe ISV-Licensed sont placés en maintenance mode ou deviennent surchargés, vSphere DRS ne peut pas déplacer les VMs de Group A vers des hosts en dehors du groupe.
¶ Visualisation de l’utilisation des ressources d’un cluster vSphere DRS
Depuis l’onglet Monitor du cluster, vous pouvez afficher l’utilisation du CPU, de la mémoire et du réseau par host.
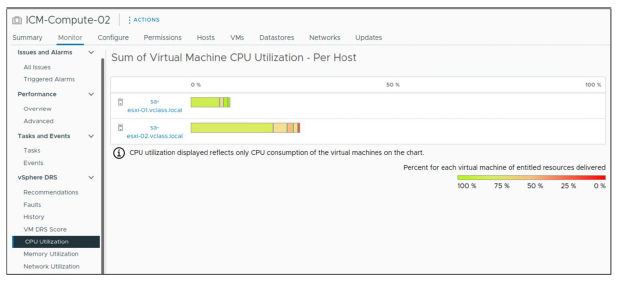
Le graphique CPU Utilization affiche tous les hosts du cluster ainsi que la façon dont leurs ressources CPU sont allouées à chaque VM.
Pour l’utilisation du CPU, une case colorée représente les informations de la VM. Si vous pointez sur la case colorée, les informations d’utilisation du CPU de la VM apparaissent.
Si la VM reçoit les ressources auxquelles elle a droit, la case est verte.
Le vert signifie que 100 % des ressources attribuées à la VM lui sont effectivement délivrées.
Si la case n’est pas verte (par exemple, si les ressources attribuées sont de 80 % ou moins) pendant une période prolongée, il peut être utile d’investiguer la cause de ce manque (par exemple, des recommandations non appliquées).
Le graphique Memory Utilization affiche tous les hosts du cluster ainsi que la façon dont leurs ressources mémoire sont allouées à chaque VM.
Pour l’utilisation de la mémoire, les cases des VMs ne sont pas codées par couleur, car la relation entre la mémoire consommée et l’allocation de ressources n’est pas toujours facilement catégorisable.
Le graphique Network Utilization affiche les données réseau, qui reflètent tout le trafic circulant à travers les interfaces réseau physiques du host.
¶ Visualisation des recommandations vSphere DRS
Sélectionnez Recommendations pour afficher les informations concernant les recommandations vSphere DRS faites pour le cluster.
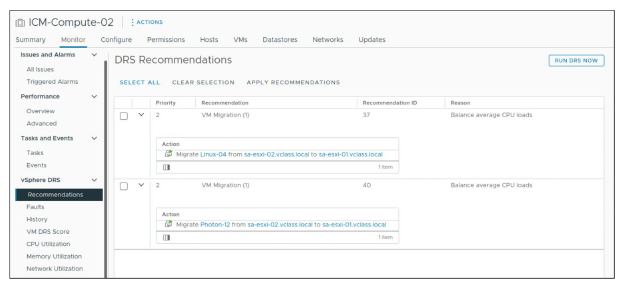
Dans le volet DRS Recommendations, vous pouvez voir l’ensemble actuel des recommandations générées pour optimiser l’utilisation des ressources dans le cluster, soit par des migrations, soit par la gestion de l’alimentation (power management).
Les recommandations apparaissent dans la liste si vSphere DRS est configuré en mode Manual ou Partially Automated.
Pour actualiser les recommandations, cliquez sur RUN DRS NOW.
Pour appliquer toutes les recommandations, cliquez sur SELECT ALL pour sélectionner toutes les recommandations, puis cliquez sur APPLY RECOMMENDATIONS.
Pour appliquer uniquement une partie des recommandations, cochez la case à côté de chaque recommandation souhaitée, puis cliquez sur APPLY RECOMMENDATIONS.
En plus du volet DRS Recommendations, vous pouvez sélectionner Faults pour afficher les erreurs survenues lors de l’application des recommandations.
Vous pouvez également sélectionner History pour afficher l’historique des actions vSphere DRS.
¶ Mode maintenance et mode veille (Standby Mode)
Maintenance mode :
- Doit être utilisé pour effectuer la maintenance d’un host dans un cluster
- Rend les ressources du host indisponibles à l’utilisation
Standby mode :
- Utilisé par vSphere DPM pour optimiser la consommation d’énergie
- Lorsqu’un host est placé en standby mode, il est éteint (powered off)
Un host entre ou sort du maintenance mode à la suite d’une demande de l’utilisateur.
En maintenance mode, le host n’autorise pas le déploiement ni l’allumage (power on) d’une VM.
Les VMs en cours d’exécution sur un host qui entre en maintenance mode doivent être arrêtées, suspendues ou migrées vers un autre host (manuellement par un utilisateur ou automatiquement par vSphere DRS).
Le host continue d’exécuter la tâche Enter Maintenance Mode tant que toutes les VMs ne sont pas éteintes ou déplacées.
Lorsque plus aucune VM ne s’exécute sur le host, l’icône du host indique qu’il est passé en maintenance mode. L’onglet Summary du host indique également ce nouvel état.
Placez un host en maintenance mode avant de le maintenir, par exemple pour installer de la mémoire supplémentaire ou retirer un host d’un cluster.
Vous pouvez placer un host en standby mode manuellement. Lorsqu’un host est placé en standby mode, il est éteint (powered off), à l’exception du Baseboard Management Controller (BMC).
Le BMC reste alimenté même lorsque le host lui-même est éteint.
Pour plus d’informations sur vSphere DPM, consultez vSphere Resource Management à l’adresse suivante : https://docs.vmware.com/en/VMware-vSphere/index.html.
Si vous placez un host en standby mode, lors de la prochaine exécution de vSphere DRS, il se peut que votre modification soit annulée ou qu’une recommandation vous invite à l’annuler.
Si vous souhaitez qu’un host reste éteint (powered off), placez-le en maintenance mode puis éteignez-le.
¶ Suppression d’un host d’un cluster vSphere DRS
Pour supprimer un host d’un cluster :
-
Placez le host en maintenance mode.
- Toutes les VMs en cours d’exécution sur le host doivent être migrées vers un autre host, arrêtées ou suspendues.
- Si DRS est en mode fully automated, les VMs allumées (powered-on) sont automatiquement migrées depuis un host placé en maintenance mode.
-
Faites glisser (drag) le host vers un autre emplacement d’inventaire, par exemple le data center ou un autre cluster.
Les ressources disponibles pour le cluster diminuent.
Lorsqu’un host est placé en maintenance mode, toutes ses VMs en cours d’exécution doivent être arrêtées, suspendues ou migrées vers d’autres hosts en utilisant vSphere vMotion.
Les VMs utilisant des disques sur du stockage local doivent être éteintes, suspendues ou migrées vers un autre host et un autre datastore.
Lorsque vous supprimez le host du cluster, les VMs actuellement associées à ce host sont également supprimées du cluster.
Si le cluster dispose encore de suffisamment de ressources pour satisfaire les réservations de toutes les VMs du cluster, il ajuste l’allocation des ressources afin de refléter la diminution de ressources disponibles.
¶ Lab 24 : Mise en œuvre des clusters vSphere DRS
Créez un vSphere DRS cluster, utilisez Cluster Quickstart pour effectuer la configuration de base, et vérifiez le bon fonctionnement de vSphere DRS :
- Créer un Cluster configuré pour vSphere DRS
- Vérifier la configuration vSphere vMotion sur les ESXi hosts
- Ajouter des ESXi hosts au Cluster
- Modifier les paramètres vSphere DRS
- Allumer (Power On) les VMs et examiner les recommandations vSphere DRS
- Examiner les recommandations vSphere DRS lorsque le Cluster est déséquilibré (imbalanced)
Retrouvez le lien du Lab en cliquant ici : Lab 24 : Mise en œuvre des clusters vSphere DRS
¶ Revue des objectifs d’apprentissage
- Décrire les fonctions d’un vSphere DRS cluster
- Expliquer comment vSphere DRS détermine le placement des VMs sur les hosts du cluster
- Identifier les cas d’utilisation des paramètres vSphere DRS
- Configurer vSphere DRS dans un cluster
- Surveiller un vSphere DRS cluster
¶ Leçon 3 : Introduction à vSphere High Availability (HA)
¶ Objectifs d’apprentissage
- Décrire comment vSphere HA réagit à différents types de pannes
- Décrire comment vSphere HA réagit à une isolation réseau (network isolation)
- Identifier les options de configuration de la redondance réseau dans un vSphere HA cluster
¶ Protection à tous les niveaux
Avec vSphere, vous pouvez réduire les interruptions planifiées (planned downtime), éviter les interruptions non planifiées (unplanned downtime) et récupérer rapidement après des pannes (outages).
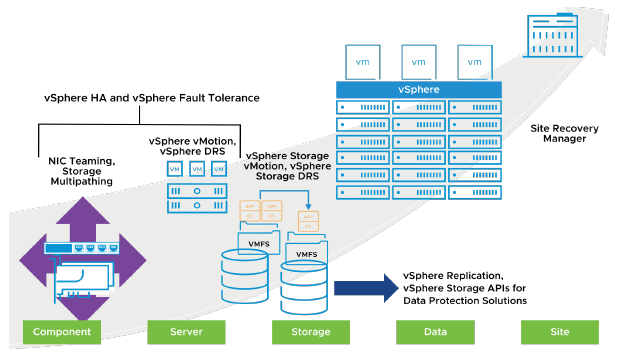
Qu’elles soient planifiées ou non, les interruptions de service (downtime) entraînent des coûts considérables. Cependant, les solutions permettant d’assurer des niveaux plus élevés de disponibilité sont traditionnellement coûteuses, difficiles à mettre en œuvre et complexes à gérer.
Le logiciel VMware simplifie et réduit le coût de la mise en place de niveaux de disponibilité plus élevés pour les applications importantes. Avec vSphere, les organisations peuvent facilement augmenter le niveau de disponibilité de base fourni pour toutes les applications et offrir des niveaux supérieurs de disponibilité de manière plus simple et plus économique.
Avec vSphere, vous pouvez :
- Fournir une disponibilité supérieure, indépendamment du matériel, du système d’exploitation et des applications.
- Réduire les interruptions planifiées (planned downtime) lors des opérations de maintenance courantes.
- Fournir une reprise automatique en cas de panne.
vSphere HA fournit un niveau de protection de base pour vos VMs en redémarrant les VMs si un host échoue.
vSphere Fault Tolerance (FT) fournit un niveau de disponibilité plus élevé, permettant aux utilisateurs de protéger n’importe quelle VM contre une panne de host, sans perte de données, de transactions ni de connexions.
vSphere Fault Tolerance assure une disponibilité continue en garantissant que l’état des VMs primaire et secondaire reste identique à tout moment pendant l’exécution des instructions de la VM.
vSphere vMotion et vSphere Storage vMotion maintiennent les VMs disponibles pendant une interruption planifiée (planned outage), par exemple lorsque des hosts ou du stockage doivent être mis hors ligne pour maintenance.
La récupération du système après des pannes de stockage imprévues est simple, rapide et fiable grâce à la propriété d’encapsulation des VMs.
Vous pouvez utiliser vSphere Storage vMotion pour gérer les interruptions planifiées de stockage résultant de mises à jour de baies de stockage vers un nouveau firmware ou une nouvelle technologie, ainsi que des mises à jour VMFS.
Avec vSphere Replication, une plateforme vSphere peut protéger les VMs nativement en copiant leurs fichiers disques vers un autre emplacement, où elles sont prêtes à être restaurées.
L’encapsulation des VMs est utilisée par des applications de sauvegarde tierces qui prennent en charge des sauvegardes au niveau fichier ou image, en utilisant les vSphere Storage APIs – Data Protection.
Les solutions de sauvegarde jouent un rôle essentiel dans la récupération de fichiers ou disques supprimés, ainsi que de systèmes d’exploitation invités ou de systèmes de fichiers corrompus ou infectés.
Avec Site Recovery Manager (SRM), vous pouvez restaurer rapidement l’infrastructure IT de votre organisation, réduisant ainsi la durée d’une interruption d’activité (business outage).
Site Recovery Manager automatise la configuration, le basculement (failover) et le test des plans de reprise après sinistre (disaster recovery plans).
Site Recovery Manager nécessite l’installation de vCenter sur le site protégé et sur le site de reprise.
Il nécessite également soit une réplication basée sur l’hôte via vSphere Replication, soit une réplication basée sur la baie (array-based replication) préconfigurée entre le site protégé et le site de reprise.
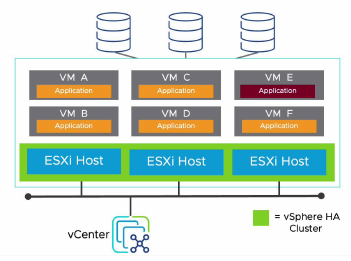
¶ À propos de vSphere High Availability (HA)
vSphere High Availability (HA) offre une récupération rapide après des interruptions (outages) et une haute disponibilité (high availability) rentable pour les applications s’exécutant dans des VMs.
vSphere HA protège la disponibilité des applications de plusieurs manières.
| Protège contre | Comment vSphere HA fournit la protection ? |
|---|---|
| Panne d’ESXi host | Redémarre les VMs sur d’autres hosts au sein du cluster |
| Panne de VM | Redémarre la VM lorsqu’aucun VMware Tools heartbeat n’est reçu dans le délai imparti |
| Panne d’application | Redémarre la VM lorsqu’aucun application heartbeat n’est reçu dans le délai imparti |
| Perte d’accessibilité à un datastore | Redémarre les VMs affectées sur d’autres hosts qui ont encore accès aux datastores |
| Isolation réseau (network isolation) | Redémarre les VMs si leur host devient isolé sur le heartbeat network (protection assurée même si le réseau est partitionné) |
Contrairement à d’autres solutions de clustering, vSphere HA protège toutes les charges de travail en utilisant directement l’infrastructure.
Après avoir configuré vSphere HA, aucune action n’est requise pour protéger les nouvelles VMs.
Toutes les charges de travail sont automatiquement protégées par vSphere HA.
¶ Scénario vSphere HA : Panne d’ESXi Host
Quand un host tombe en panne, vSphere HA redémarre les VMs impactées sur d’autres hosts du cluster.
vSphere HA peut déterminer si un ESXi host est isolé ou s’il est tombé en panne.
Si un ESXi host échoue, vSphere HA tente de redémarrer toutes les VMs qui s’exécutaient sur le host en panne en utilisant les hosts restants dans le cluster.
Dans chaque cluster, le temps de récupération dépend de la durée nécessaire au redémarrage de vos guest operating systems et applications lorsque la VM est reprise (failover).
¶ Scénario vSphere HA : Panne du Guest Operating System
Quand une VM cesse d’envoyer des heartbeats ou que le processus de la VM (vmx) échoue de manière inattendue, vSphere HA redémarre la VM sur le même host.
Si la surveillance de VM (VM monitoring) est configurée, l’agent vSphere HA sur chaque host surveille VMware Tools dans chaque VM s’exécutant sur le host.
Lorsqu’une VM cesse d’envoyer des heartbeats, la VM est redémarrée sur le même host.
¶ Scénario vSphere HA : Panne d’application
Quand une application cesse d’envoyer des heartbeats, vSphere HA redémarre la VM impactée sur le même host.
Pour activer Application Monitoring, vous devez obtenir le SDK approprié ou utiliser une application qui prend en charge VMware Application Monitoring.
Ensuite, utilisez cette application pour configurer des heartbeats personnalisés pour les applications que vous souhaitez surveiller.
Une fois cela fait, Application Monitoring fonctionne de la même manière que VM Monitoring.
L’agent sur chaque host peut surveiller les heartbeats des applications s’exécutant dans chaque VM.
Quand une application échoue (cesse d’envoyer des heartbeats), la VM sur laquelle l’application s’exécutait est redémarrée sur le même host.
¶ Scénario vSphere HA : Pannes d’accessibilité d’un datastore
vSphere HA peut détecter les pannes d’accessibilité d’un datastore et assurer une récupération automatique pour les VMs affectées.
Vous pouvez déterminer la réponse que vSphere HA doit apporter à une telle panne :
-
All paths down (APD) :
— Récupérable
— Représente une perte d’accessibilité transitoire ou inconnue
— Réponse possible : Issue events, Power off and restart VMs – Conservative restart policy, ou Power off and restart VMs – Aggressive restart policy -
Permanent device loss (PDL) :
— Perte d’accessibilité irrécupérable
— Se produit lorsqu’un périphérique de stockage signale que le datastore n’est plus accessible par le host
— Réponse possible : Issue events ou Power off and restart VMs
Vous pouvez déterminer la réponse que vSphere HA apporte à une telle panne, allant de la création d’event alarms jusqu’au redémarrage des VMs sur d’autres hosts.
Power off and restart VMs – Conservative restart policy :
vSphere HA n’essaie pas de redémarrer les VMs affectées tant qu’il n’a pas déterminé qu’un autre host peut les redémarrer.
Le host confronté à un all paths down (APD) communique avec le vSphere HA primary host pour vérifier si le cluster dispose d’une capacité suffisante pour rallumer les VMs concernées.
Si le primary host confirme que la capacité est suffisante, le host en APD arrête les VMs afin qu’elles puissent être redémarrées sur un host sain.
Si le host en APD ne peut pas communiquer avec le primary host, aucune action n’est entreprise.
Power off and restart VMs – Aggressive restart policy :
vSphere HA arrête les VMs affectées même s’il ne peut pas déterminer qu’un autre host pourra les redémarrer.
Le host confronté à un all paths down (APD) tente de communiquer avec le vSphere HA primary host afin de vérifier si le cluster dispose d’une capacité suffisante pour rallumer les VMs concernées.
Si le primary host est injoignable, la capacité réelle à redémarrer les VMs reste inconnue.
Dans ce scénario, le host prend le risque et arrête les VMs, afin qu’elles puissent être redémarrées sur les autres hosts sains.
Cependant, si la capacité est insuffisante, vSphere HA peut échouer à récupérer toutes les VMs affectées.
Ce résultat est fréquent lors d’un scénario de partition réseau, où un host ne peut pas communiquer avec le primary host pour obtenir une réponse définitive sur la probabilité d’une récupération réussie.
¶ Importance des Heartbeat Networks
Un heartbeat network est implémenté en utilisant un VMkernel port configuré pour le trafic de management ou de vSAN.
Les heartbeats ont les caractéristiques suivantes :
- Ils sont envoyés entre le primary host et les secondary hosts.
- Ils sont utilisés pour déterminer si un primary host ou un secondary host est tombé en panne.
- Ils sont transmis via un heartbeat network.
Quand vSAN et vSphere HA sont activés sur le cluster, vSphere HA utilise le vSAN network comme heartbeat network au lieu du management network.
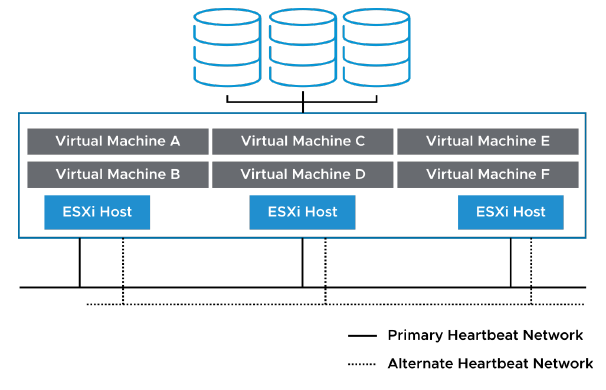
Le heartbeat networking redondant permet de détecter de manière fiable les pannes et empêche l’apparition de situations d’isolation ou de partition, car les heartbeats peuvent être envoyés sur plusieurs réseaux.
Le heartbeat networking redondant est la meilleure approche pour votre cluster vSphere HA.
Quand la connexion d’un primary host échoue, une deuxième connexion reste disponible pour envoyer les heartbeats aux autres hosts.
Si vous ne mettez pas en place de redondance, votre configuration de failover comporte un single point of failure.
¶ Scénario vSphere HA : Protection des VMs contre l’isolation réseau
vSphere HA redémarre les VMs si leur host est isolé sur le management network ou le vSAN network.
L’isolation réseau d’un host se produit lorsqu’un host est encore en fonctionnement, mais qu’il ne peut plus observer le trafic provenant des agents vSphere HA sur le heartbeat network.
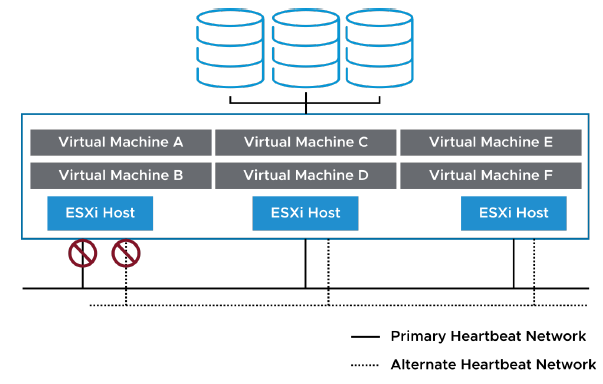
Si vous vérifiez que l’infrastructure réseau est suffisamment redondante et qu’au moins un chemin réseau est toujours disponible, l’isolation réseau d’un host peut ne pas se produire.
¶ Redondance du Heartbeat Network avec NIC Teaming
Les heartbeat networks redondants assurent une détection fiable des pannes et réduisent le risque de scénarios d’isolation de host.
Vous pouvez utiliser le NIC teaming pour créer un heartbeat network redondant sur les ESXi hosts.
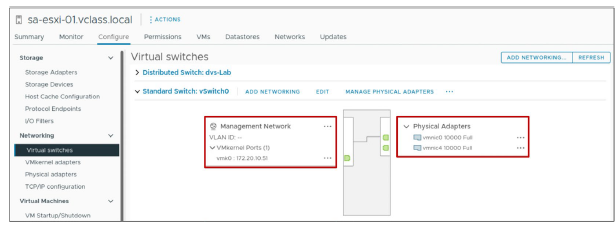
Dans cet exemple, vmnic0 et vmnic4 forment une NIC team dans le Management network.
Le port VMkernel vmk0 a le service Management activé.
¶ Redondance du réseau de heartbeat à l’aide de réseaux supplémentaires
Vous pouvez créer de la redondance en configurant des réseaux de heartbeat supplémentaires.
Par exemple, créez un deuxième port VMkernel dans un groupe de ports sur un commutateur virtuel distinct avec son propre adaptateur physique.
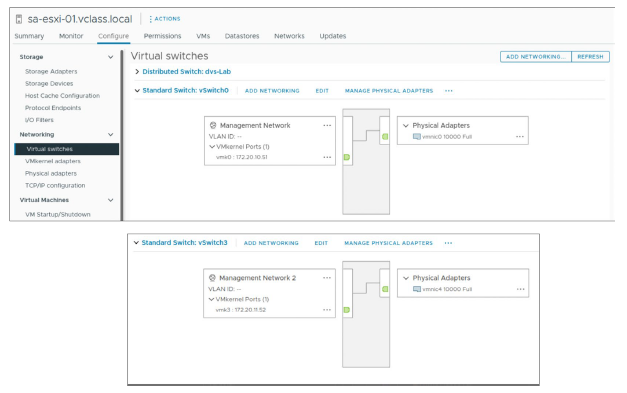
Dans la plupart des implémentations, le NIC teaming fournit une redondance suffisante pour le réseau de heartbeat.
Comme alternative, vous pouvez créer un deuxième port VMkernel attaché à un commutateur virtuel distinct. Les deux ports VMkernel peuvent également être placés sur le même commutateur virtuel, mais dans des groupes de ports différents, chaque groupe de ports utilisant un adaptateur physique distinct.
Dans cet exemple, le réseau de gestion est utilisé comme réseau de heartbeat. La connexion réseau de gestion d’origine est utilisée pour le réseau et les fonctions de gestion. Lorsqu’une deuxième connexion réseau de gestion est créée, l’hôte principal envoie des heartbeats sur les deux connexions réseau de gestion. Si un chemin échoue, l’hôte principal continue à envoyer et recevoir des heartbeats via l’autre chemin.
¶ Revue des objectifs d’apprentissage
- Décrire comment vSphere HA réagit face aux différents types de pannes
- Décrire comment vSphere HA réagit à l’isolation réseau
- Identifier les options pour configurer la redondance réseau dans un cluster vSphere HA
¶ Leçon 4 : Architecture de vSphere HA
¶ Revue des objectifs d’apprentissage
- Identifier les mécanismes de heartbeat utilisés par vSphere HA
- Décrire les scénarios de panne
- Reconnaître les considérations de conception de vSphere HA
¶ Architecture vSphere HA : Communication des agents
Lorsque vSphere HA est configuré dans un cluster, le service Fault Domain Manager (FDM) est chargé sur chaque hôte du cluster et démarré.
Le service FDM est également appelé agent vSphere HA.
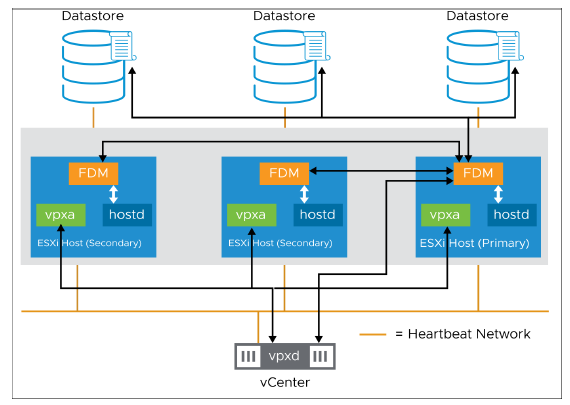
Le cluster vSphere HA est géré par un hôte principal (primary host).
Tous les autres hôtes sont appelés hôtes secondaires (secondary hosts).
Les services Fault Domain Manager (FDM) sur les hôtes secondaires communiquent tous avec le FDM de l’hôte principal.
Les hôtes ne peuvent pas participer à un cluster vSphere HA s’ils sont en mode maintenance, en mode veille (standby), ou déconnectés de vCenter.
Pour déterminer quel hôte devient l’hôte principal, un processus d’élection a lieu.
L’hôte ayant accès au plus grand nombre de datastores est élu hôte principal.
Si plusieurs hôtes voient le même nombre de datastores, le processus d’élection utilise l’identifiant géré (MOID – Managed Object ID) attribué par vCenter pour départager.
Le processus d’élection d’un nouvel hôte principal se termine en environ 15 secondes et se produit dans les circonstances suivantes :
- Lorsque vSphere HA est configuré.
- Lorsque l’hôte principal rencontre une panne système en raison de l’un des facteurs suivants :
— L’hôte principal est placé en mode maintenance.
— L’hôte principal est placé en mode veille (standby).
— vSphere HA est reconfiguré. - Lorsque les hôtes secondaires ne peuvent plus communiquer avec l’hôte principal à cause d’un problème réseau.
Pendant le processus d’élection, les agents candidats vSphere HA communiquent entre eux sur le réseau de heartbeat (réseau vSAN ou réseau de gestion) en utilisant le protocole User Datagram Protocol (UDP). Toutes les connexions réseau sont point-à-point.
Après que l’hôte principal est déterminé, l’hôte principal et les hôtes secondaires communiquent en utilisant le protocole TCP sécurisé.
Quand vSphere HA est démarré, vCenter contacte l’hôte principal et envoie une liste des hôtes membres du cluster ainsi que la configuration du cluster. Ces informations sont sauvegardées sur le stockage local de l’hôte principal puis transmises aux hôtes secondaires dans le cluster.
Si des hôtes supplémentaires sont ajoutés au cluster pendant le fonctionnement normal, l’hôte principal envoie une mise à jour à tous les hôtes du cluster.
L’hôte principal fournit une interface permettant à vCenter d’interroger l’état et de rendre compte de la santé du domaine de défaillance et de la disponibilité des VM. vCenter indique à l’agent vSphere HA quelles VM protéger avec leur liste de compatibilité VM-hôte. L’agent apprend les changements d’état via hostd et vCenter apprend via vpxa. L’hôte principal surveille la santé des hôtes secondaires et prend la responsabilité des VM qui s’exécutaient sur un hôte secondaire ayant échoué.
Un hôte secondaire surveille la santé des VM s’exécutant localement et envoie les changements d’état à l’hôte principal. Un hôte secondaire surveille également la santé de l’hôte principal.
vSphere HA est configuré, géré et surveillé via vCenter. Le processus vpxd, qui s’exécute sur le système vCenter, conserve les données de configuration du cluster. Le processus vpxd signale les changements de configuration du cluster à l’hôte principal. L’hôte principal diffuse une nouvelle copie des informations de configuration du cluster, et chaque hôte secondaire récupère une copie mise à jour. Chaque hôte secondaire écrit les informations de configuration mises à jour sur le stockage local. Une liste des VM protégées est stockée sur chaque datastore. La liste des VM est mise à jour après chaque opération d’allumage (protégée) ou d’arrêt (non protégée) initiée par l’utilisateur. La liste des VM est mise à jour après que vCenter a observé ces opérations.
Une VM devient protégée lorsqu’une opération entraîne son allumage. Revenir à un snapshot avec état mémoire provoque l’allumage de la VM et sa mise en protection. De même, une action utilisateur qui entraîne l’arrêt de la VM, par exemple revenir à un snapshot sans état mémoire ou une opération de mise en veille effectuée dans l’invité, provoque la mise hors protection de la VM.
¶ Architecture vSphere HA : Heartbeats réseau
L’hôte principal envoie des heartbeats périodiques aux hôtes secondaires.
De cette manière, les hôtes secondaires savent que l’hôte principal est actif, et l’hôte principal sait que les hôtes secondaires sont actifs.
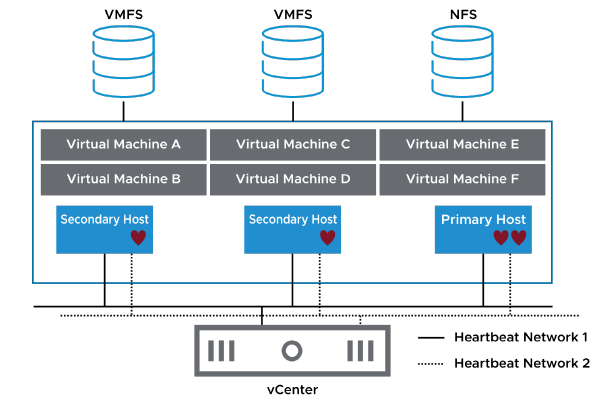
Les heartbeats sont envoyés à chaque hôte secondaire depuis l’hôte principal via tous les réseaux de heartbeat configurés. Cependant, les hôtes secondaires utilisent seulement un réseau de heartbeat pour communiquer avec l’hôte principal. Si le réseau de heartbeat utilisé pour communiquer avec l’hôte principal échoue, l’hôte secondaire bascule vers un autre réseau de heartbeat pour communiquer avec l’hôte principal.
Si l’hôte secondaire ne répond pas dans le délai d’attente prédéfini, l’hôte principal déclare l’hôte secondaire comme agent injoignable. Lorsqu’un hôte secondaire ne répond pas, l’hôte principal tente de déterminer la cause de l’incapacité de l’hôte secondaire à répondre. L’hôte principal doit déterminer si l’hôte secondaire a planté, s’il ne répond pas à cause d’une panne réseau, ou si l’agent vSphere HA est dans un état injoignable.
¶ Architecture vSphere HA : Heartbeats de datastore
Quand l’hôte principal ne peut pas communiquer avec un hôte secondaire via le réseau de heartbeat, l’hôte principal utilise le datastore heartbeating pour déterminer la cause :
- Panne de l’hôte secondaire
- Partition réseau
- Isolement réseau
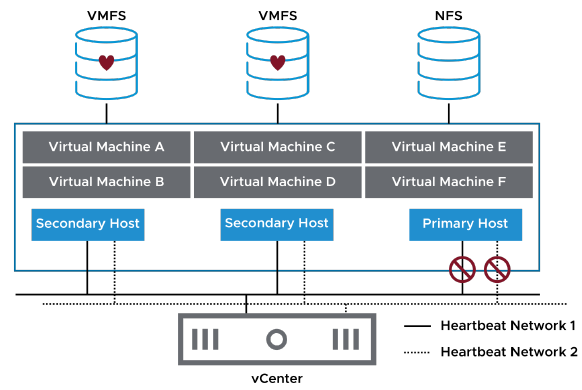
En utilisant le datastore heartbeating, l’hôte principal détermine si un hôte a échoué ou si un isolement réseau s’est produit.
Si le datastore heartbeating en provenance de l’hôte s’arrête, l’hôte est considéré comme en panne.
Dans ce cas, les VM de l’hôte en panne sont démarrées sur un autre hôte du cluster vSphere HA.
¶ Scénarios de défaillance vSphere HA
vSphere HA peut identifier et réagir à différents types de défaillances :
- Panne d’un hôte secondaire
- Panne de l’hôte principal
- Défaillance réseau (isolement d’hôte)
- Défaillances d’accessibilité du datastore :
— APD
— PDL
vSphere HA peut également déterminer si un hôte ESXi est isolé ou s’il a échoué.
L’isolement fait référence au cas où un hôte ESXi ne peut pas voir le trafic provenant des autres hôtes du cluster et ne peut pas répondre à un ping de son adresse d’isolement configurée.
Si un hôte ESXi échoue, vSphere HA tente de redémarrer les VM qui s’exécutaient sur l’hôte en panne sur les hôtes restants du cluster.
Si l’hôte ESXi est isolé parce qu’il ne peut pas répondre à un ping de son adresse d’isolement configurée et qu’il ne voit aucun trafic réseau de heartbeat, l’hôte exécute la Host Isolation Response.
¶ Hôtes secondaires en panne
Lorsqu’un hôte secondaire ne répond pas au network heartbeat émis par l’hôte principal, l’hôte principal tente d’identifier la cause.
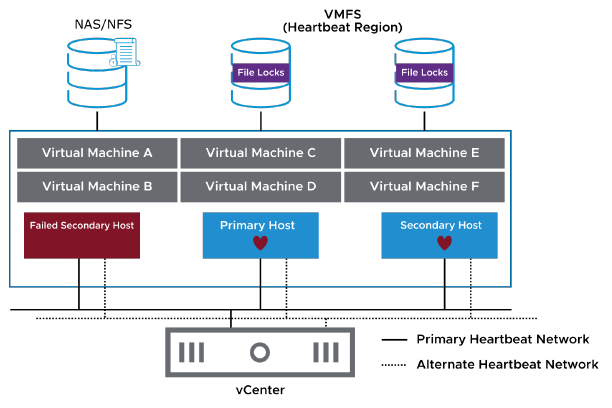
L’hôte principal doit déterminer si l’hôte secondaire est isolé ou s’il a échoué, par exemple en raison d’une règle de pare-feu mal configurée ou d’une panne de composant. Le type de défaillance dicte la manière dont vSphere HA réagit.
Lorsque l’hôte principal ne peut pas communiquer avec un hôte secondaire via le réseau de heartbeat, l’hôte principal utilise le datastore heartbeating pour déterminer si l’hôte secondaire a échoué, s’il est dans une partition réseau ou s’il est isolé du réseau. Si l’hôte secondaire arrête le datastore heartbeating, il est considéré comme ayant échoué et ses machines virtuelles sont redémarrées ailleurs.
Pour VMFS, une région de heartbeat sur le datastore est lue pour savoir si l’hôte envoie encore des heartbeats vers celui-ci.
Pour les datastores NFS, vSphere HA lit le fichier host--hb, qui est verrouillé par l’hôte ESXi accédant au datastore. Ce fichier garantit que le VMkernel envoie des heartbeats vers le datastore et met à jour périodiquement le fichier de verrouillage.
L’horodatage du fichier de verrouillage est utilisé par l’hôte principal pour déterminer si l’hôte secondaire est isolé ou s’il a échoué.
Dans les deux exemples de stockage, l’instance vCenter sélectionne un petit sous-ensemble de datastores vers lesquels les hôtes envoient des heartbeats.
Les datastores qui sont accessibles par le plus grand nombre d’hôtes sont sélectionnés comme candidats.
Mais deux datastores sont sélectionnés (par défaut) afin de maintenir la charge associée et le traitement au minimum.
¶ Hôtes principaux en panne
Lorsque l’hôte principal est placé en mode maintenance ou tombe en panne, les hôtes secondaires détectent que l’hôte principal n’émet plus de heartbeats.
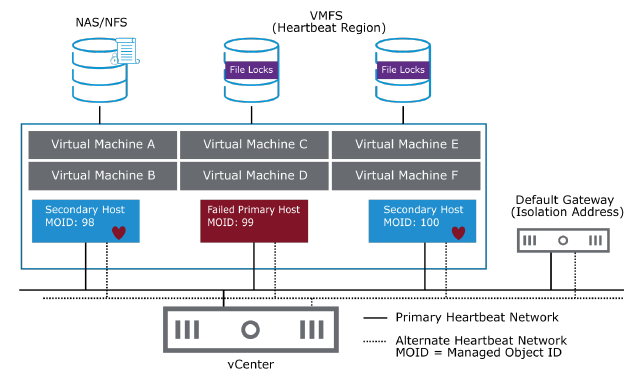
Pour déterminer quel hôte devient l’hôte principal, un processus d’élection a lieu.
L’hôte qui peut accéder au plus grand nombre de datastores est élu hôte principal.
Si plusieurs hôtes voient le même nombre de datastores, le processus d’élection détermine l’hôte principal en utilisant le Managed Object ID (MOID) attribué par vCenter.
Si l’hôte principal tombe en panne, est arrêté ou placé en mode maintenance, une nouvelle élection est déclenchée.
¶ Hôtes isolés
Un hôte est déclaré isolé lorsque les deux conditions suivantes se produisent :
- L’hôte ne reçoit plus de battements réseau (network heartbeats).
- L’hôte ne peut pas effectuer de ping vers ses adresses d’isolement (isolation addresses).
Lorsque qu’un hôte s’identifie comme isolé, il exécute la réponse à l’isolement du cluster (cluster’s isolation response).
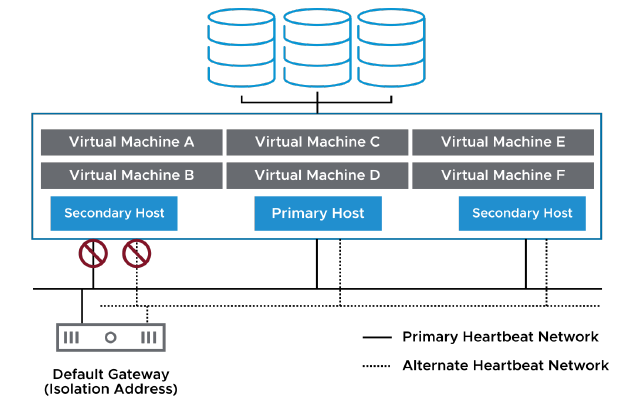
La diapositive illustre un scénario qui peut mener à l’isolement d’un hôte.
Si un hôte perd la connectivité à la fois vers le réseau de battement principal (primary heartbeat network) et vers le réseau de battement secondaire (alternate heartbeat network), il ne reçoit plus de battements réseau provenant des autres hôtes du cluster vSphere HA.
Le même hôte ne peut pas non plus effectuer de ping vers son adresse d’isolement (isolation address). Une adresse d’isolement est une adresse IP ou un FQDN qui peut être spécifié manuellement (par défaut, il s’agit de la passerelle par défaut de l’hôte).
Si un hôte est isolé, le primary host doit déterminer si cet hôte est actif mais simplement isolé, en vérifiant les battements sur les datastores (datastore heartbeats). Ces battements sont utilisés par vSphere HA uniquement lorsqu’un hôte est isolé ou partitionné.
La réponse à l’isolement de l’hôte (host isolation response) détermine ce qui se produit lorsqu’un hôte dans un cluster vSphere HA perd ses connexions au réseau de battement mais continue de fonctionner.
Vous pouvez utiliser cette réponse à l’isolement dans vSphere HA pour éteindre les machines virtuelles qui s’exécutent sur un hôte isolé et les redémarrer sur un hôte non isolé.
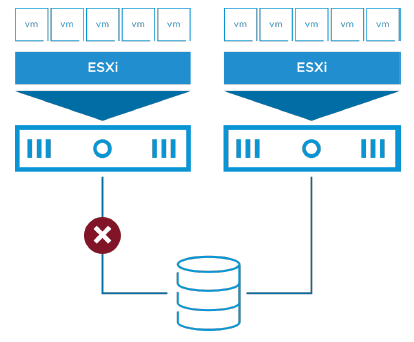
¶ Pannes de stockage des VM (VM Storage Failures)
Des problèmes de connectivité au stockage peuvent survenir en raison de :
• Une panne réseau ou de commutateur
• Une mauvaise configuration de la baie (array misconfiguration)
• Une coupure de courant
Les problèmes de connectivité au stockage affectent la disponibilité des machines virtuelles (VM) :
• Les VM sur les hôtes affectés deviennent difficiles à gérer.
• Les applications avec des disques attachés échouent.
¶ Protection contre les pannes de stockage avec VMCP
(Protecting Against Storage Failures with VMCP)
VM Component Protection (VMCP) protège contre les pannes de stockage sur une machine virtuelle.
Avec VMCP, vSphere HA peut détecter les échecs d’accessibilité aux datastores et assurer une récupération automatisée des VM affectées.
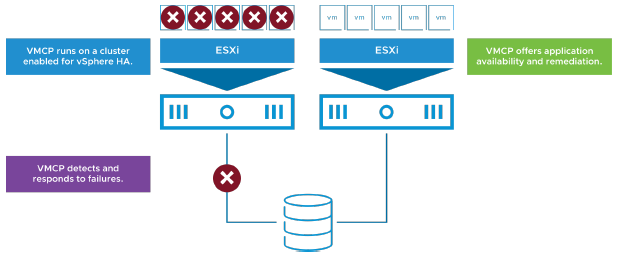
Lorsque survient une panne d’accessibilité à un datastore, l’hôte affecté ne peut plus accéder au chemin de stockage d’un datastore spécifique.
Vous pouvez déterminer la réponse que vSphere HA apporte à une telle panne, qui peut aller de la création d’alarmes d’événement jusqu’au redémarrage des VM sur d’autres hôtes.
Pour plus d’informations sur VM Component Protection, consultez : https://blogs.vmware.com/vsphere/
¶ Considérations de conception pour vSphere HA
Lors de la conception de votre cluster vSphere HA, prenez en compte les directives suivantes :
-
Implémentez des réseaux de heartbeat redondants et des adresses d’isolation redondantes :
— La redondance réduit les événements d’isolation de host. -
Séparez physiquement les réseaux VM des réseaux de heartbeat.
-
Implémentez des datastores de manière à ce qu’ils soient séparés du réseau de heartbeat en utilisant une ou les deux approches suivantes :
— Utilisez Fibre Channel over fiber optic pour vos datastores.
— Si vous utilisez du IP storage, séparez physiquement votre réseau de IP storage du réseau de heartbeat.
Si un datastore est basé sur Fibre Channel, une panne du réseau Ethernet n’interrompt pas l’accès au datastore. Lors de l’utilisation de datastores basés sur IP storage (par exemple, NFS, iSCSI, ou Fibre Channel over Ethernet), vous devez séparer physiquement le réseau IP storage et le réseau de heartbeat.
¶ Revue des objectifs d’apprentissage
- Identifier les mécanismes de heartbeat utilisés par vSphere HA
- Décrire les scénarios de panne
- Reconnaître les considérations de conception pour vSphere HA
¶ Leçon 5 : Configuration de vSphere HA
¶ Objectifs d’apprentissage
- Reconnaître les prérequis pour la création et l’utilisation d’un cluster vSphere HA
- Reconnaître les cas d’usage de différents paramètres vSphere HA
- Reconnaître quand utiliser vSphere Fault Tolerance
- Configurer un cluster vSphere HA
¶ Prérequis pour vSphere HA
Pour créer un cluster vSphere HA, vous devez respecter plusieurs exigences :
- Tous les hosts doivent être configurés avec des adresses IP statiques. Si vous utilisez DHCP, l’adresse doit persister après les redémarrages du host.
- Tous les hosts doivent avoir au moins un réseau de heartbeat en commun.
- Pour que la surveillance des VM fonctionne, VMware Tools doit être installé dans chaque VM.
- Vous ne devez pas dépasser le nombre maximum de hosts autorisés dans un cluster.
Consultez VMware Configuration Maximums à l’adresse : https://configmax.vmware.com.
Pour déterminer le nombre maximum de hosts par cluster, voir VMware Configuration Maximums à https://configmax.vmware.com.
¶ Configuration des paramètres vSphere HA
Lorsque vous créez ou configurez un cluster vSphere HA, vous devez définir des paramètres qui déterminent le fonctionnement de la fonctionnalité.
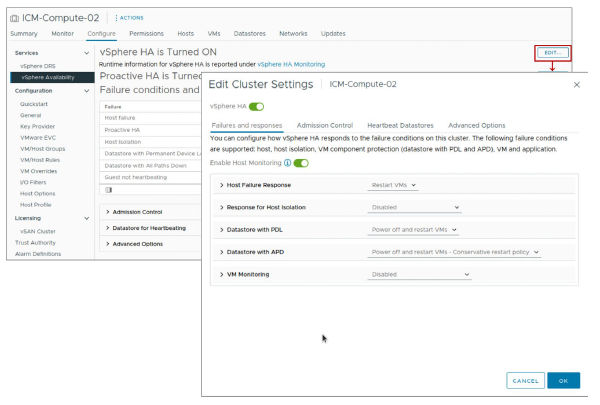
Dans le vSphere Client, vous pouvez configurer les paramètres vSphere HA suivants :
- Conditions de panne de disponibilité et réponses : Fournir des paramètres pour les réponses aux pannes de host, l’isolation de host, la surveillance des VM, et VMCP.
- Admission control : Activer ou désactiver l’admission control pour le cluster vSphere HA et sélectionner une politique de mise en application.
- Heartbeat datastores : Spécifier les préférences pour les datastores que vSphere HA utilise pour le datastore heartbeating.
- Options avancées : Personnaliser le comportement de vSphere HA en définissant des options avancées.
¶ Paramètres vSphere HA : Pannes et réponses
Vous utilisez le volet Failures and responses pour configurer la réponse d’un cluster en cas de panne.
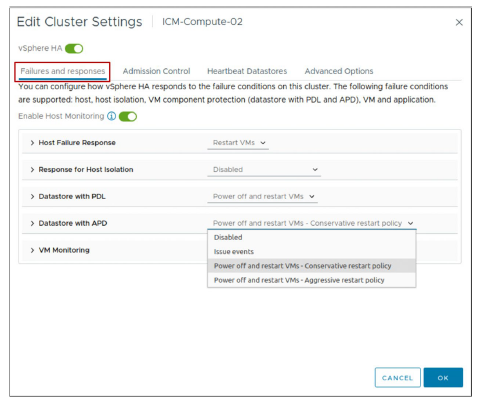
En utilisant le volet Failures and Responses, vous pouvez configurer le fonctionnement de votre cluster lorsque des problèmes surviennent. Vous pouvez spécifier la réponse du cluster vSphere HA aux pannes et à l’isolation de host. Vous pouvez configurer les actions VMCP lorsqu’une situation de Permanent Device Loss ou de All Paths Down se produit, et activer la surveillance des VM.
Les réponses suivantes aux pannes de host sont disponibles :
- Disabled : La surveillance des hosts est désactivée et les VM ne sont pas redémarrées.
- Restart VMs : Les VM sont reprises en fonction de leur priorité de redémarrage.
Les réponses suivantes à l’isolation de host sont disponibles :
- Disabled
- Power off and restart VMs
- Shut down and restart VMs
Les réponses suivantes à une condition datastore PDL sont disponibles :
- Disabled
- Issue events : Aucune action n’est effectuée sur les VM affectées. L’administrateur est notifié lorsqu’un événement PDL se produit.
- Power off and restart VMs
Les réponses suivantes à une condition datastore APD sont disponibles :
-
Disabled
-
Issue events : Aucune action n’est effectuée sur les VM affectées. L’administrateur est notifié lorsqu’un événement APD se produit.
-
Power off and restart VMs – Conservative restart policy : vSphere HA n’essaie pas de redémarrer les VM affectées à moins que vSphere HA détermine qu’un autre host peut redémarrer les VM.
L’host subissant l’APD communique avec l’host primaire afin de déterminer si une capacité suffisante existe dans le cluster pour mettre sous tension les VM affectées. Si l’host primaire détermine qu’une capacité suffisante existe, l’host subissant l’APD arrête les VM afin qu’elles puissent être redémarrées sur un host sain. Si l’host subissant l’APD ne peut pas communiquer avec l’host primaire, la VM n’est pas arrêtée. -
Power off and restart VMs – Aggressive restart policy : vSphere HA arrête les VM affectées même s’il ne peut pas déterminer qu’un autre host peut redémarrer les VM.
L’host subissant l’APD tente de communiquer avec l’host primaire pour savoir si une capacité suffisante existe dans le cluster afin de mettre sous tension les VM affectées. Si l’host primaire n’est pas joignable, la capacité suffisante pour redémarrer les VM est inconnue. Dans ce scénario, l’host prend le risque et arrête les VM afin qu’elles puissent être redémarrées sur les hosts sains restants.
Cependant, si une capacité suffisante n’est pas disponible, vSphere HA pourrait ne pas être capable de récupérer toutes les VM affectées. Ce résultat est fréquent dans un scénario de partition réseau où un host ne peut pas communiquer avec l’host primaire.
Les options suivantes de surveillance des VM sont disponibles :
- VM monitoring only
- VM and application monitoring
¶ Paramètre vSphere HA : Priorité de redémarrage par défaut des VM
La priorité de redémarrage des VM détermine l’ordre dans lequel vSphere HA redémarre les VM sur un host en fonctionnement.
Les VM se voient attribuer par défaut la priorité de redémarrage Medium, sauf si la priorité de redémarrage est explicitement définie en utilisant des VM overrides.
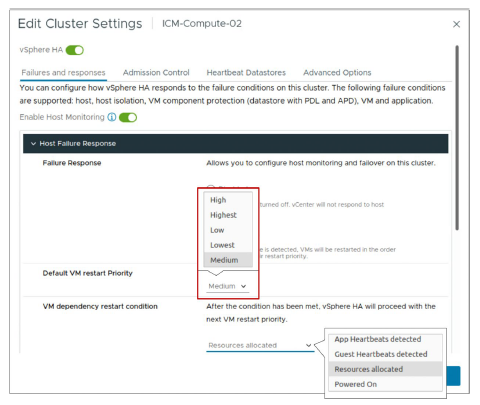
Après une panne de host, les VM sont affectées à d’autres hosts disposant de capacité non réservée, en plaçant en priorité les VM ayant la priorité la plus élevée. Le processus se poursuit avec les VM de priorité plus faible jusqu’à ce que toutes aient été placées, ou qu’aucune capacité supplémentaire du cluster ne soit disponible pour satisfaire les réservations ou la surcharge mémoire des VM. Un host redémarre ensuite les VM qui lui sont attribuées, dans l’ordre de priorité.
Si les ressources disponibles sont insuffisantes, vSphere HA attend que plus de capacité non réservée soit disponible (par exemple, lorsqu’un host revient en ligne), puis réessaie le placement de ces VM. Pour réduire le risque que cette situation se produise, configurez l’admission control vSphere HA afin de réserver davantage de ressources pour les pannes. Avec l’admission control, vous pouvez contrôler la quantité de capacité du cluster réservée par les VM, qui n’est alors pas disponible pour répondre aux réservations et à la surcharge mémoire d’autres VM en cas de panne.
En option, vous pouvez configurer un délai lorsqu’une certaine condition de redémarrage est remplie.
Les conditions suivantes doivent être remplies avant qu’une VM soit considérée comme prête :
- La VM dispose de ressources allouées
- La VM est mise sous tension (powered on)
- Un VMware Tools heartbeat est détecté
- Un VMware Tools application heartbeat est détecté
¶ Paramètres vSphere HA : Priorité de redémarrage au niveau VM
Vous pouvez personnaliser la priorité de redémarrage pour des VM individuelles dans un cluster afin de remplacer le niveau par défaut défini pour l’ensemble du cluster.
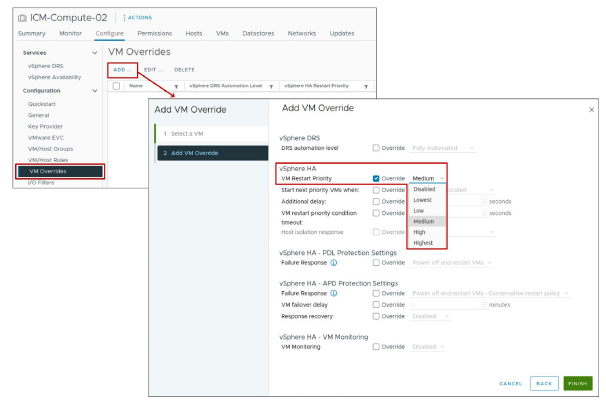
¶ À propos du redémarrage orchestré vSphere HA
Le redémarrage orchestré est une alternative à l’utilisation des paramètres de priorité de redémarrage des VM pour vSphere HA.
Avec le redémarrage orchestré, vous définissez l’ordre dans lequel les VM redémarrent, ce qui est utile lorsque des services doivent être démarrés dans un ordre particulier.
Un cas d’usage courant est le redémarrage d’une application à trois niveaux (three-tier application).
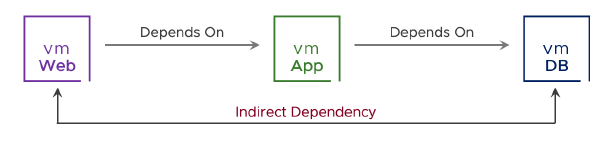
Seules les dépendances directes sont prises en charge. La création de dépendances cycliques entraîne l’échec du redémarrage d’une VM.
¶ Redémarrage orchestré en action
vSphere HA redémarre uniquement les VM provenant d’un host en panne. Configurez des affinity rules pour maintenir les VM sur le même host si nécessaire.
Une animation est disponible : https://vmware.bravais.com/s/FPFepiQhbhlhdTfJwW4N
¶ Configuration du redémarrage orchestré
Pour configurer un redémarrage orchestré :
- Créez des VM groups pour chacune des VM ou catégories de VM.
- Créez des VM rules (de type Virtual Machines to Virtual Machines) afin de définir les dépendances de redémarrage des VM.
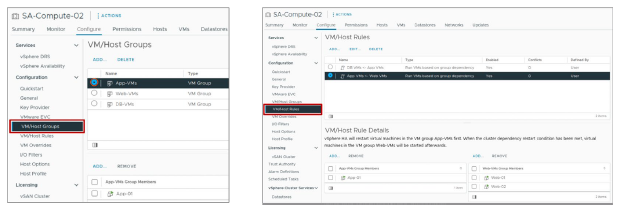
Dans l’exemple de redémarrage orchestré, les VM du serveur de base de données redémarrent avant les VM du serveur d’applications, et les VM du serveur d’applications redémarrent avant les VM du serveur Web.
Les VM groups suivants sont créés :
- App-VMs : contient la VM App-01
- Web-VMs : contient les VM Web-01 et Web-02
- DB-VMs : contient la VM DB-01
Les VM rules suivantes, de type Virtual Machines to Virtual Machines, sont créées :
- DB VMs <- App VMs : vérifie que les VM du groupe DB-VMs redémarrent avant les VM du groupe App-VMs
- App VMs <- Web VMs : vérifie que les VM du groupe App-VMs redémarrent avant les VM du groupe Web-VMs
Pour créer la règle DB VMs <- App VMs :
- Dans l’onglet Configure du cluster, sélectionnez VM/Host Rules puis cliquez sur ADD.
- Dans la zone de texte Name, entrez DB VMs <- App VMs.
- Dans le menu déroulant Type, sélectionnez Virtual Machines to Virtual Machines.
- Dans le premier menu déroulant, sélectionnez DB-VMs.
- Dans le second menu déroulant, sélectionnez App-VMs.
La règle doit apparaître ainsi : Lors du redémarrage du groupe de VM DB-VMs, la condition de redémarrage par dépendance de VM doit être remplie avant de continuer avec App-VMs.
Créez la règle App-VMs <- Web VMs de la même manière, en sélectionnant App-VMs dans le premier menu déroulant et Web-VMs dans le second menu déroulant.
La règle doit apparaître ainsi : Lors du redémarrage du groupe de VM App-VMs, la condition de redémarrage par dépendance de VM doit être remplie avant de continuer avec Web-VMs.
Les règles de redémarrage que vous créez imposent l’ordre de redémarrage pour chaque VM dans la chaîne de dépendances. La création de ces dépendances augmente la probabilité qu’une application impactée se rétablisse correctement lorsque vSphere HA redémarre les VM.
¶ Paramètres vSphere HA : Surveillance de VM
Vous utilisez les paramètres de VM Monitoring pour contrôler la surveillance des VM et des applications.
Par défaut, VM and Application Monitoring est défini sur Disabled.
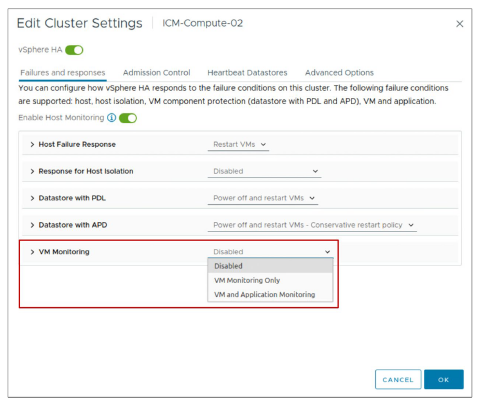
Le service de VM monitoring détermine qu’une VM a échoué si l’un des événements suivants se produit :
- Les VMware Tools heartbeats ne sont pas reçus.
- Le système d’exploitation invité (guest operating system) n’a pas émis d’entrées/sorties (I/O) durant les 2 dernières minutes (par défaut).
Si la VM a échoué, le service de VM monitoring réinitialise la VM afin de restaurer les services.
Vous pouvez configurer le niveau de sensibilité de la surveillance. Une surveillance très sensible (highly sensitive monitoring) conclut plus rapidement qu’une panne est survenue. Bien que peu probable, une surveillance très sensible peut mener à l’identification erronée d’échecs lorsque la VM ou l’application fonctionne encore, mais que les heartbeats n’ont pas été reçus en raison de contraintes de ressources.
Une surveillance peu sensible (low-sensitivity monitoring) entraîne des interruptions de service plus longues entre les défaillances réelles et la réinitialisation des VM.
Sélectionnez une option qui constitue un compromis efficace selon vos besoins.
Vous pouvez sélectionner VM and Application Monitoring pour activer la surveillance des applications.
La surveillance des applications redémarre une VM si les heartbeats d’une application qu’elle exécute ne sont pas reçus.
¶ Paramètres vSphere HA : Admission Control
vCenter utilise admission control pour garantir les points suivants :
- Des ressources suffisantes sont disponibles dans un cluster pour assurer la protection contre les pannes (failover protection).
- Les réservations de ressources des VM sont respectées.
Paramètres d’admission control :
- Disabled
- Slot Policy
- Cluster Resource Percentage (par défaut)
- Dedicated Failover Hosts
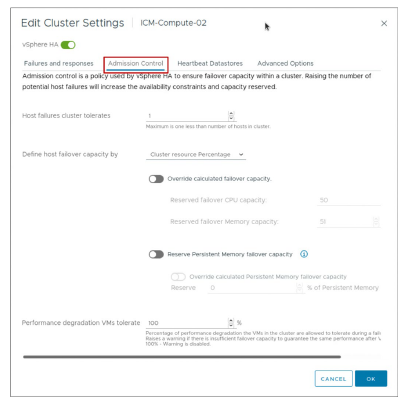
Après avoir créé un cluster, vous pouvez utiliser admission control pour spécifier si les VM peuvent être démarrées lorsqu’elles violent les contraintes de disponibilité (availability constraints).
Le cluster réserve des ressources afin de permettre le failover de toutes les VM en cours d’exécution pour un nombre spécifié de pannes d’hôtes.
Les paramètres d’admission control incluent :
-
Disabled : Cette option désactive l’admission control, permettant aux VM qui violent les contraintes de disponibilité de s’allumer (power on). (Non recommandé).
-
Slot Policy : Un slot est une représentation logique des ressources mémoire et CPU. Avec l’option slot policy, vSphere HA calcule la taille du slot, détermine combien de slots chaque hôte du cluster peut contenir et déduit ainsi la capacité actuelle de failover du cluster.
-
Cluster Resource Percentage (par défaut) : Cette valeur spécifie un pourcentage des ressources CPU et mémoire du cluster à réserver comme capacité de secours pour supporter les failovers.
-
Dedicated Failover Hosts : Cette option sélectionne des hôtes dédiés à l’exécution des actions de failover. Si un hôte de failover par défaut n’a pas assez de ressources, les failovers peuvent quand même être effectués sur d’autres hôtes du cluster.
¶ Exemple : Admission Control utilisant Cluster Resources Percentage
Exemple de calcul de la capacité totale de failover en utilisant les pourcentages de ressources du cluster :
-
Capacité totale du cluster :
— CPU : 18 GHz
— Memory : 24 GB -
Réservations totales des VM :
— CPU : 7 GHz
— Memory : 6 GB -
Capacité actuelle de failover CPU = 61 % :
— ((18 GHz - 7 GHz) / 18 GHz = 61 %) -
Capacité actuelle de failover Memory = 75 % :
— ((24 GB - 6 GB) / 24 GB = 75 %)
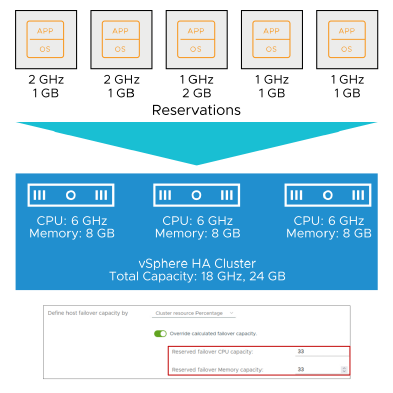
La politique Cluster Resource Percentage est la politique d’admission control par défaut.
Les recalculs se produisent automatiquement lorsque les ressources du cluster changent, par exemple lorsqu’un hôte est ajouté ou supprimé du cluster.
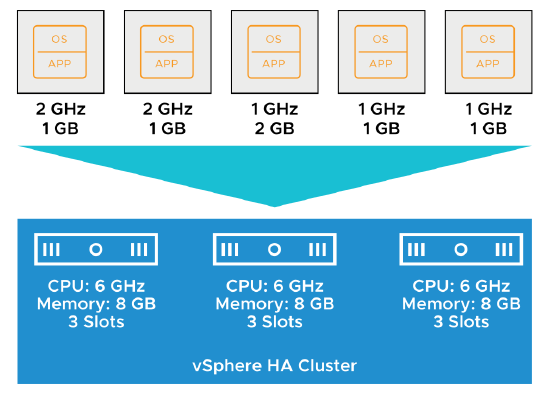
¶ Exemple : Admission Control utilisant les Slots
Un slot est calculé en combinant la plus grande réservation mémoire et la plus grande réservation CPU de n’importe quelle VM en cours d’exécution dans le cluster.
vSphere HA effectue l’admission control en calculant les valeurs suivantes :
-
Slot size :
— Dans cet exemple, la taille du slot est de 2 GHz CPU et 2 GB memory. -
Nombre de slots que chaque hôte du cluster peut contenir :
— Trois
— Le cluster a un total de neuf slots (3 + 3 + 3).
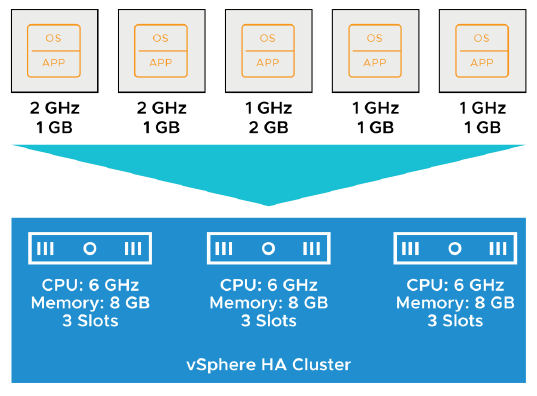
vSphere HA calcule également la capacité de failover actuelle.
Dans cet exemple, la capacité de failover est d’un hôte :
- Si le premier hôte échoue, six slots restent dans le cluster, ce qui est suffisant pour toutes les cinq VM sous tension (powered-on VMs).
- Si le premier et le deuxième hôte échouent, seuls trois slots restent, ce qui est insuffisant pour toutes les cinq VM.
- Si la capacité de failover actuelle est inférieure à la capacité de failover configurée, vSphere HA n’autorise pas d’autres VM à être mises sous tension (power on).
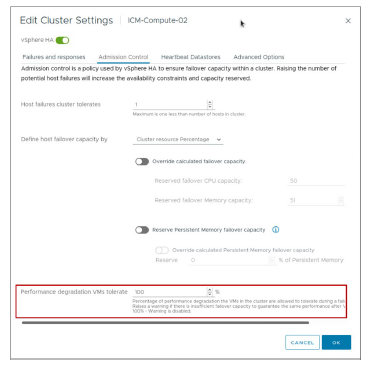
¶ Paramètres vSphere HA : Seuil de dégradation des performances toléré par les VMs
Le seuil Performance degradation VMs tolerate spécifie le pourcentage de dégradation des performances que les VM du cluster sont autorisées à tolérer lors d’une panne.
L’admission control peut également être configuré pour générer des avertissements lorsque l’utilisation réelle dépasse le pourcentage de capacité de failover. Le calcul de la réduction des ressources prend en compte la mémoire réservée d’une VM et la surcharge mémoire (memory overhead).
En définissant le seuil Performance degradation VMs tolerate, vous pouvez spécifier quand un problème de configuration doit générer un avertissement ou une notification. Par exemple :
- La valeur par défaut est 100 percent, et ne génère aucun avertissement.
- Si vous réduisez le seuil à 0 percent, un avertissement est généré lorsque l’utilisation du cluster dépasse la capacité disponible.
- Si vous réduisez le seuil à 20 percent, la réduction de performance pouvant être tolérée est calculée comme suit :
performance reduction = current use × 20 percent.
Lorsque l’utilisation actuelle, moins la réduction de performance, dépasse la capacité disponible, une notification de configuration est émise.
Le seuil Performance degradation VMs tolerate n’est pas disponible à moins que vSphere DRS soit configuré.
¶ Paramètres vSphere HA : Heartbeat Datastores
Un fichier de heartbeat est créé sur les datastores sélectionnés et est utilisé si le heartbeat network échoue.
Heartbeat datastores :
- VMFS
- NFS
- vSphere Virtual Volumes
Un vSAN datastore ne peut pas être utilisé pour le datastore heartbeating.
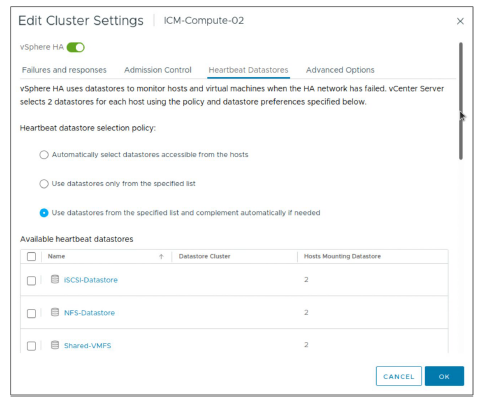
vSphere HA pousse la vérification de l’état de santé d’un hôte plus loin en contrôlant non seulement le heartbeat network, mais également d’autres indicateurs pour déterminer l’état de santé d’un hôte.
Vous pouvez sélectionner les datastores à utiliser pour le datastore heartbeating, ou laisser vSphere HA décider. Vous pouvez également combiner les deux méthodes.
¶ Paramètres vSphere HA : Options avancées
Vous pouvez définir des options avancées de vSphere HA afin de personnaliser le comportement de vSphere HA.
| Description | Option | Valeur |
|---|---|---|
| Forcer un cluster à ne pas utiliser l’adresse d’isolation par défaut (default gateway). | das.usedefaultisolationaddress |
false |
| Forcer un cluster à effectuer un ping vers des adresses d’isolation alternatives. | das.isolationaddressX |
Adresse IP ou FQDN |
| Forcer un cluster à attendre au-delà de la fenêtre d’action d’isolation par défaut de 30 secondes. | das.config.fdm.isolationPolicyDelaySec |
>= 30 seconds |
| Forcer une limite maximale sur la taille mémoire d’un slot. | das.slotmeminmb |
100 |
| Forcer une limite maximale sur la taille CPU d’un slot. | das.slotcpuinmhz |
32 |
Vous pouvez définir des options avancées qui affectent le comportement de votre cluster vSphere HA.
Pour plus de détails, consultez la documentation vSphere Availability à l’adresse suivante : https://docs.vmware.com/en/VMware-vSphere/index.html
¶ Configuration et maintenance du réseau
Désactivez le host monitoring avant de modifier les composants de réseau virtuel qui impliquent les VMkernel ports configurés pour la gestion (management) ou le trafic vSAN.
Cette pratique empêche les tentatives non souhaitées de failover des VM.
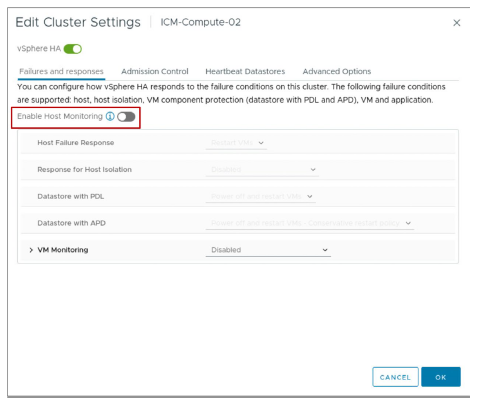
Les suggestions suivantes pour la maintenance du réseau peuvent vous aider à éviter la détection erronée de panne d’hôte et l’isolation réseau à cause de vSphere HA heartbeats perdus :
-
La modification de votre matériel réseau ou des paramètres réseau peut interrompre les heartbeats utilisés par vSphere HA pour détecter les pannes d’hôtes, et peut entraîner des tentatives non souhaitées de failover des VM. Lors de la modification des réseaux de management ou vSAN des hôtes d’un cluster configuré avec vSphere HA, suspendez le host monitoring et placez l’hôte en maintenance mode.
-
La désactivation du host monitoring est requise uniquement lors de la modification des composants et propriétés de réseau virtuel impliquant les VMkernel ports configurés pour le Management ou le trafic vSAN, utilisés par le service vSphere HA networking heartbeat.
-
Pour résumer les points précédents, vous devez reconfigurer vSphere HA sur tous les hôtes du cluster si vous :
— Changez la configuration réseau sur des hôtes ESXi
— Ajoutez des port groups
— Supprimez des virtual switches
— Suspendez le host monitoring
Cette reconfiguration entraîne une réinspection des informations réseau. Ensuite, vous devez réactiver le host monitoring.
¶ Surveillance de l’état du cluster vSphere HA
Vous pouvez surveiller l’état d’un cluster vSphere HA sur la page Summary de l’onglet Monitor.
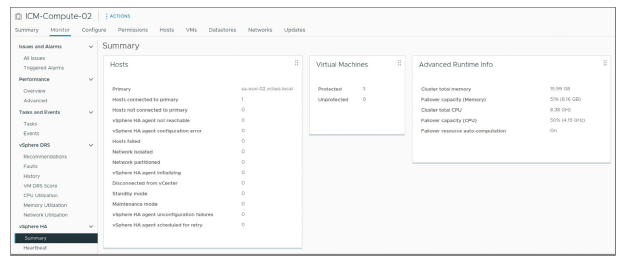
Votre cluster ou ses hôtes peuvent rencontrer des problèmes de configuration et d’autres erreurs qui affectent négativement le bon fonctionnement de vSphere HA.
¶ Utilisation de vSphere HA avec vSphere DRS
vSphere HA est étroitement intégré avec vSphere DRS :
- Lorsqu’un failover se produit, vSphere HA vérifie si des ressources sont disponibles sur chaque hôte pour le failover.
- Si les ressources ne sont pas disponibles, vSphere HA demande à vSphere DRS de réaffecter les ressources pour les VM lorsque c’est possible.
vSphere HA peut ne pas être en mesure de réaliser un failover des VM pour les raisons suivantes :
- Le contrôle d’admission (admission control) de vSphere HA est désactivé et les ressources sont insuffisantes sur les hôtes restants pour mettre sous tension (power on) toutes les VM en échec.
Lorsque vSphere HA effectue un failover et redémarre les VM sur différents hôtes, sa première priorité est la disponibilité immédiate de toutes les VM.
Après que les VM ont été redémarrées, les hôtes sur lesquels elles ont été relancées sont généralement très chargés, tandis que d’autres hôtes sont relativement peu sollicités.
vSphere DRS aide à équilibrer la charge en migrant les VM entre les hôtes du cluster.
¶ À propos de vSphere Fault Tolerance
vSphere Fault Tolerance (FT) protège les applications critiques et à haute performance, quel que soit le système d’exploitation utilisé.
vSphere Fault Tolerance fournit un basculement instantané et une disponibilité continue :
- Zéro temps d’arrêt
- Zéro perte de données
- Aucune perte de connectivité réseau de la VM
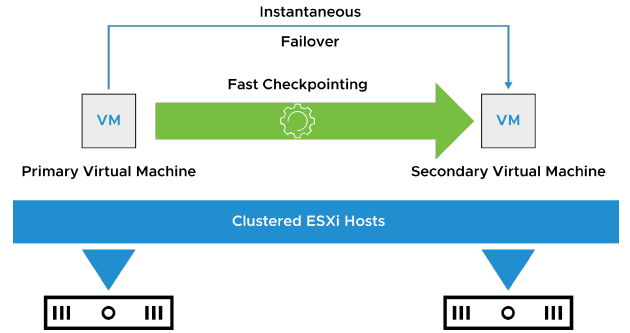
Vous pouvez utiliser vSphere Fault Tolerance pour la plupart des VMs critiques pour l’entreprise. vSphere Fault Tolerance est basé sur la plateforme ESXi host.
La VM protégée est appelée la primary VM. La VM dupliquée est appelée la secondary VM. La secondary VM est créée et s’exécute sur un host différent de la primary VM. L’exécution de la secondary VM est identique à celle de la primary VM. La secondary VM peut prendre le relais à tout moment sans interruption et fournir une protection tolérante aux pannes.
La primary VM et la secondary VM surveillent en continu l’état l’une de l’autre afin de garantir que la fault tolerance est maintenue. Un failover transparent se produit si le host exécutant la primary VM tombe en panne, auquel cas la secondary VM est immédiatement activée pour remplacer la primary VM. Une nouvelle secondary VM est créée et démarrée, et la redondance de la fault tolerance est automatiquement rétablie.
Si le host exécutant la secondary VM tombe en panne, la secondary VM est immédiatement remplacée. Dans les deux cas, les utilisateurs ne subissent aucune interruption de service et aucune perte de données.
¶ vSphere Fault Tolerance Checkpointing
Les changements sur la primary VM ne sont pas traités sur la secondary VM. La mémoire est mise à jour sur la secondary VM.
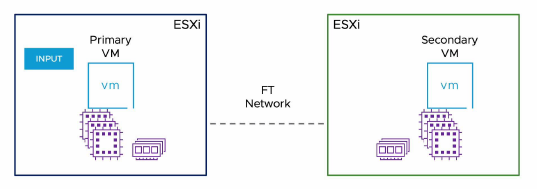
Une annimation est disponible à cette adresse : https://vmware.bravais.com/s/CAQIyfAA4o5uRM54k6oU
¶ vSphere Fault Tolerance avec vSphere HA et vSphere DRS
vSphere HA et vSphere DRS sont compatibles avec vSphere Fault Tolerance :
• vSphere HA est requis pour vSphere Fault Tolerance.
• vSphere DRS :
— Sélectionne quels hosts exécutent la primary VM et la secondary VM, lorsqu’une VM est mise sous tension.
— Ne migre pas automatiquement les VMs tolérantes aux pannes.
Une annimation est disponible à cette adresse : https://vmware.bravais.com/s/uZwjd73t46eXD69ZqXdW
Une VM tolérante aux pannes et sa copie secondary ne sont pas autorisées à s’exécuter sur le même host. Cette restriction garantit qu’une panne d’host ne puisse pas entraîner la perte des deux VMs.
De plus, vSphere vMotion ne peut pas être utilisé pour migrer les VMs vers le même host.
¶ vSphere Fault Tolerance Features
vSphere Fault Tolerance :
• Prend en charge les VMs configurées avec jusqu’à 8 vCPUs et 128 GB de mémoire
• Prend en charge jusqu’à quatre VMs tolérantes aux pannes par host avec un maximum de huit vCPUs au total
• Prend en charge la migration vSphere vMotion pour les primary et secondary VMs
• Crée une copie secondaire de tous les fichiers et disques de la VM
• Prend en charge plusieurs formats de disques VM :
— Thin provision
— Thick provision lazy-zeroed
— Thick provision eager-zeroed
• Prend en charge l’interopérabilité avec vSAN
• Fournit une copie rapide des checkpoints pour maintenir la synchronisation entre la primary VM et la secondary VM
Pour plus de détails sur vSphere Fault Tolerance, consultez vSphere Availability à l’adresse :
https://docs.vmware.com/en/VMware-vSphere/index.html
¶ Configuration de vSphere Fault Tolerance sur une VM
Vous pouvez activer vSphere Fault Tolerance pour une VM en utilisant le vSphere Client.
Après avoir effectué les étapes nécessaires pour configurer vSphere Fault Tolerance sur votre cluster, vous pouvez utiliser cette fonctionnalité en l’activant pour des VMs individuelles.
Avant que vSphere Fault Tolerance puisse être activé, des vérifications de validation sont effectuées sur une VM.
Lorsque vSphere Fault Tolerance est activé, vCenter réinitialise la limite de mémoire de la VM à la valeur par défaut (mémoire illimitée) et définit la réservation mémoire à la taille mémoire de la VM.
Lorsque vSphere Fault Tolerance est activé, vous ne pouvez pas modifier la réservation mémoire, la taille mémoire, la limite, le nombre de virtual CPUs, ou les shares.
Vous ne pouvez pas non plus ajouter ou supprimer des disques pour la VM.
Lorsque vSphere Fault Tolerance est désactivé, les paramètres qui avaient été modifiés ne reviennent pas à leurs valeurs d’origine.
En plus d’activer vSphere Fault Tolerance pour une VM, des options supplémentaires sont disponibles :
- Turn Off Fault Tolerance : Supprime la secondary VM, sa configuration et tout l’historique.
- Suspend Fault Tolerance : Suspend la protection vSphere Fault Tolerance, mais conserve la secondary VM, sa configuration et tout l’historique. Utilisez cette option si, à un moment ultérieur, vous souhaitez reprendre la protection vSphere Fault Tolerance sur la VM.
- Migrate Secondary : Migre la secondary VM vers le host spécifié.
- Test Failover : Provoque une situation de failover pour la primary VM sélectionnée afin de tester votre protection vSphere Fault Tolerance. Cette option est indisponible si la VM est éteinte.
- Test Restart Secondary : Provoque l’échec d’une secondary VM afin de tester la protection vSphere Fault Tolerance fournie pour la primary VM sélectionnée. Cette option est indisponible si la VM est éteinte.
¶ Lab 25: Configuration de vSphere HA
Configurez vSphere HA et testez sa fonctionnalité :
- Configurer vSphere HA dans un Cluster
- Afficher les informations sur le Cluster vSphere HA
- Configurer la redondance du Network Management
- Tester la fonctionnalité vSphere HA
- Afficher l’utilisation des ressources du Cluster vSphere HA
- Configurer le pourcentage de dégradation des ressources à tolérer
Retrouvez le lien du Lab en cliquant ici : Lab 25: Configuration de vSphere HA
¶ Revue des objectifs d’apprentissage
- Identifier les prérequis pour la création et l’utilisation d’un Cluster vSphere HA
- Reconnaître les cas d’usage des différents paramètres vSphere HA
- Reconnaître quand utiliser vSphere Fault Tolerance
- Configurer un Cluster vSphere HA
¶ Points clés
- Lorsque vous créez un Cluster, vous pouvez configurer vSphere DRS, vSphere HA, vSAN, ainsi que la gestion des mises à jour d’image sur l’ensemble des hosts collectivement.
- Les Clusters vSphere DRS fournissent une gestion automatisée des ressources pour garantir que les besoins en ressources des VMs soient satisfaits.
- vSphere DRS fonctionne de manière optimale lorsque les VMs respectent les prérequis de migration vSphere vMotion.
- vSphere HA protège contre différents types de défaillances : host, système d’exploitation invité (guest OS), application, accessibilité des datastores, et isolement réseau.
- Vous implémentez des heartbeat networks redondants soit avec du NIC teaming, soit en créant des heartbeat networks supplémentaires.
- vSphere Fault Tolerance fournit un zero downtime pour les applications qui doivent toujours être disponibles.
Chapitre précédent : 8 - Gestion des machines virtuelles (VMs) - Chapitre suivant : 10 - Gestion du cycle de vie vSphere