¶ Importance
Bien que le VMkernel fonctionne de manière proactive pour éviter la contention des ressources, l’optimisation des performances nécessite à la fois une analyse et une surveillance continue de votre environnement vSphere.
¶ Leçons du module
- Outils de surveillance des ressources
- Surveillance de l’utilisation des ressources
- Surveillance de vCenter et des performances
- Utilisation des alarmes
- Gestion proactive avec VMware Skyline
¶ Leçon 1 : Outils de surveillance des ressources
¶ Objectifs d’apprentissage
- Décrire la méthodologie d’optimisation des performances
- Identifier les outils de surveillance des ressources
- Utiliser les graphiques de performance de vCenter pour visualiser les performances
¶ Méthodologie d’optimisation des performances
Vous pouvez ajuster les performances de votre environnement vSphere :
- Évaluer les performances :
— Utiliser les outils de surveillance appropriés.
— Enregistrer une mesure de référence avant les modifications. - Identifier la ressource limitante.
- Rendre davantage de ressources disponibles :
— Allouer plus de ressources.
— Réduire la concurrence.
— Consigner vos modifications. - Faire un nouveau test de performance.
Ne faites pas de modifications non planifiées sur les systèmes de production.
La meilleure pratique pour l’optimisation des performances consiste à adopter une approche logique et progressive :
- Pour avoir une vue complète de la situation de performance d’une machine virtuelle (VM), utilisez les outils de surveillance du système d’exploitation invité et de vCenter.
- Identifiez la ressource sur laquelle la VM s’appuie le plus. Cette ressource est probablement celle qui affectera les performances de la VM si elle est limitée.
- Donnez plus de ressources à une VM ou diminuez celles attribuées à d’autres VMs.
- Après avoir rendu plus de ressources limitantes disponibles pour la VM, effectuez un nouveau test de performance et consignez les changements.
Soyez prudent lors de la modification des systèmes de production, car un changement peut affecter négativement les performances des machines virtuelles.
¶ Outils de surveillance des ressources
De nombreux outils de surveillance et d’analyse des performances sont disponibles pour une utilisation avec vSphere.

Les outils présents dans le système d’exploitation invité proviennent de sources externes à VMware et sont utilisés dans diverses applications VMware.
De nombreux outils utilisés à l’extérieur du système d’exploitation invité sont fournis par VMware pour être utilisés avec vSphere et d’autres applications.
Une liste partielle de ces outils de surveillance des ressources est présentée sur l'image ci-dessus.
¶ Outils de surveillance du système d’exploitation invité
Pour surveiller les performances dans le système d’exploitation invité, utilisez des outils que vous connaissez déjà, tels que le Gestionnaire des tâches de Windows.
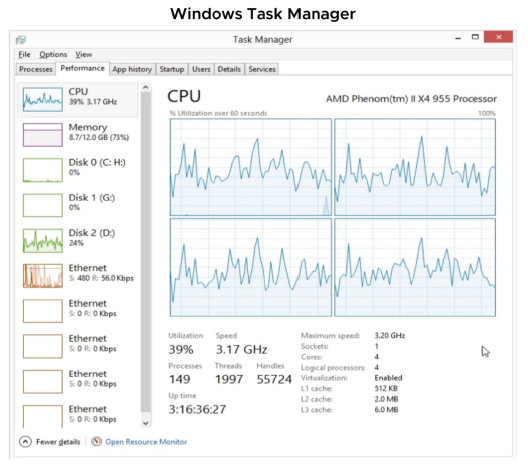
Le Gestionnaire des tâches de Windows vous aide à mesurer l’utilisation du processeur (CPU) et de la mémoire dans le système d’exploitation invité.
Les mesures que vous effectuez avec des outils dans le système d’exploitation invité reflètent l’utilisation des ressources de ce système d’exploitation invité, et non nécessairement celle de la machine virtuelle (VM) elle-même.
¶ Utilisation de Perfmon pour surveiller les ressources de la machine virtuelle
La DLL Perfmon des VMware Tools fournit des objets processeur et mémoire de machine virtuelle permettant d’accéder aux statistiques de l’hôte depuis une machine virtuelle.
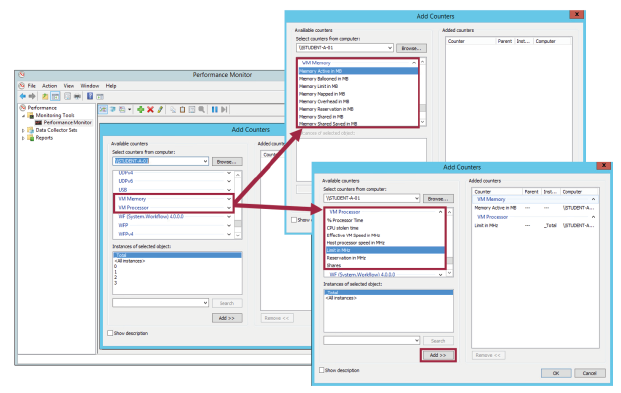
VMware Tools inclut une bibliothèque de fonctions appelée Perfmon DLL.
Avec Perfmon, vous pouvez accéder aux principales statistiques de l’hôte dans une machine virtuelle invitée.
En utilisant les objets de performance Perfmon (VM Processor et VM Memory), vous pouvez visualiser l’utilisation réelle du processeur et de la mémoire, ainsi que l’utilisation observée du processeur et de la mémoire du système d’exploitation invité.
Par exemple, vous pouvez utiliser l’objet VM Processor pour afficher le compteur % Processor Time, qui surveille la charge actuelle du processeur virtuel de la machine virtuelle.
De même, vous pouvez utiliser l’objet Processor et afficher le compteur % Processor Time (non illustré), qui surveille l’utilisation totale du processeur par tous les processus en cours d’exécution.
¶ Utilisation de esxtop pour surveiller les ressources des machines virtuelles
L’utilitaire esxtop est l’outil principal de surveillance des performances en temps réel pour vSphere :
- Peut être exécuté depuis le vSphere ESXi Shell local de l’hôte sous le nom
esxtop - Peut être exécuté à distance en utilisant r
esxtop - Fonctionne comme l’utilitaire de performance
topsous les systèmes d’exploitation Linux
Dans cet exemple, vous saisissez la lettre c en minuscule et V en majuscule pour afficher les métriques CPU des machines virtuelles.

Vous pouvez exécuter l’utilitaire esxtop en utilisant le vSphere ESXi Shell pour communiquer avec l’interface de gestion de l’hôte ESXi. Vous devez disposer des privilèges root.
C’est un utilitaire ou outil en ligne de commande qui s’exécute sous Linux et fournit une vue détaillée de la manière dont ESXi utilise les ressources en temps réel.
¶ Surveillance des objets d’inventaire avec les graphiques de performance
Le sous-système de statistiques de vSphere collecte des données sur l’utilisation des ressources des objets d’inventaire, notamment :
- Clusters
- Hôtes
- Datastores
- Réseaux
- Machines virtuelles
Les données sur un large éventail de métriques sont collectées à intervalles fréquents, traitées et archivées dans la base de données vCenter.
Vous pouvez accéder aux informations statistiques via des outils de surveillance en ligne de commande ou en consultant les graphiques de performance dans le vSphere Client.
¶ Travailler avec les graphiques de performance d’ensemble
Les graphiques de performance d’ensemble affichent les métriques les plus courantes pour un objet de l’inventaire.
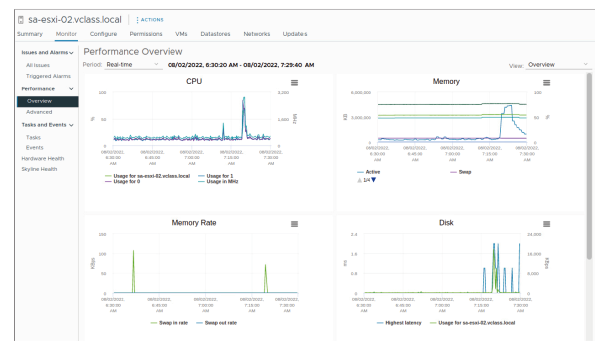
Vous pouvez accéder aux graphiques de performance d’ensemble et avancés dans le vSphere Client.
Les graphiques de performance d’ensemble montrent les statistiques de performance que VMware considère comme les plus utiles pour surveiller les performances et diagnostiquer les problèmes.
Selon l’objet que vous sélectionnez dans l’inventaire, les graphiques de performance fournissent une représentation visuelle rapide des performances de votre hôte ou de votre machine virtuelle.
¶ Travailler avec les graphiques de performance avancés
Les graphiques avancés prennent en charge des compteurs de données qui ne sont pas nécessairement disponibles dans d’autres graphiques de performance.
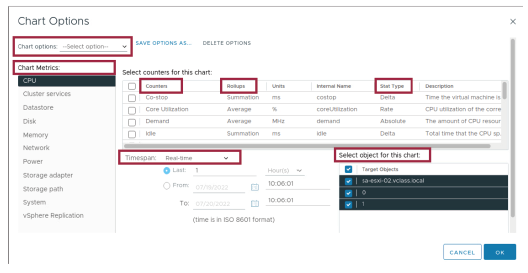
Dans le vSphere Client, vous pouvez personnaliser l’apparence des graphiques de performance avancés.
Les graphiques avancés offrent les fonctionnalités suivantes :
- Plus d’informations que les graphiques d’ensemble : pointez sur un point de données dans un graphique pour afficher des détails sur ce point spécifique.
- Graphiques personnalisables : modifiez les paramètres du graphique. Enregistrez des paramètres personnalisés pour créer vos propres graphiques.
- Enregistrez les données dans un fichier image ou une feuille de calcul.
Pour personnaliser les graphiques de performance avancés, sélectionnez Advanced sous Performance. Cliquez sur le lien Chart Options dans le volet Advanced Performance.
Les graphiques de performance avancés sont disponibles sur la page Performance > Advanced d’un objet et sont hautement configurables dans Chart Options.
¶ Options de graphiques : en temps réel et historiques
vCenter stocke les statistiques à différents niveaux de spécificité.
| Intervalle de temps | Fréquence des données | Nombre d’échantillons | Stocké dans |
|---|---|---|---|
| Temps réel (dernière heure) | 20 secondes | 180 | Mémoire vCenter |
| Dernier jour | 5 minutes | 288 | Base de données vCenter |
| Dernière semaine | 30 minutes | 336 | Base de données vCenter |
| Dernier mois | 2 heures | 360 | Base de données vCenter |
| Dernière année | 1 jour | 365 | Base de données vCenter |
Les informations en temps réel sont générées pour la dernière heure à des intervalles de 20 secondes.
Les informations historiques sont générées pour le dernier jour, la dernière semaine, le dernier mois ou la dernière année, avec différents niveaux de précision.
Par défaut, vCenter dispose de quatre intervalles d’archivage : jour, semaine, mois et année.
Chaque intervalle définit la durée pendant laquelle les statistiques sont archivées dans la base de données vCenter.
Vous pouvez configurer les intervalles utilisés et pour quelle période de temps.
Vous pouvez également définir le nombre de compteurs de données utilisés pendant un intervalle de collecte en ajustant le niveau de collecte.
Ensemble, l’intervalle de collecte et le niveau de collecte déterminent la quantité de données statistiques collectées et stockées dans la base de données vCenter.
Par exemple, selon le tableau, les statistiques du dernier jour affichent un point de données toutes les 5 minutes, pour un total de 288 échantillons.
Les statistiques de la dernière année affichent 1 point de données par jour, soit 365 échantillons.
Les statistiques en temps réel ne sont pas stockées dans la base de données.
Elles sont conservées dans un fichier plat sur les hôtes ESXi et en mémoire sur les instances vCenter.
Les hôtes ESXi collectent les statistiques en temps réel uniquement pour l’hôte ou les machines virtuelles (VM) disponibles sur cet hôte.
Les statistiques en temps réel sont collectées directement sur un hôte ESXi toutes les 20 secondes.
Si vous interrogez des statistiques en temps réel, vCenter interroge directement chaque hôte pour obtenir les données.
vCenter ne traite pas les données à ce stade — il les transmet simplement au vSphere Client.
Sur les hôtes ESXi, les statistiques sont conservées pendant 30 minutes, après quoi 90 points de données sont collectés.
Ces points sont agrégés, traités et renvoyés à vCenter.
vCenter archive ensuite les données dans la base de données sous forme de point de données pour l’intervalle de collecte quotidien.
Afin de garantir que les performances ne soient pas affectées pendant la collecte et l’écriture des données dans la base, des requêtes cycliques sont utilisées pour collecter les statistiques des compteurs de données.
Ces requêtes ont lieu pour chaque intervalle de collecte spécifié.
À la fin de chaque intervalle, le calcul des données est effectué.
¶ Types de graphiques : en barres et en secteurs
Selon le type de métrique et l’objet, les métriques de performance sont affichées dans différents types de graphiques, tels que les graphiques en barres et les graphiques en secteurs.
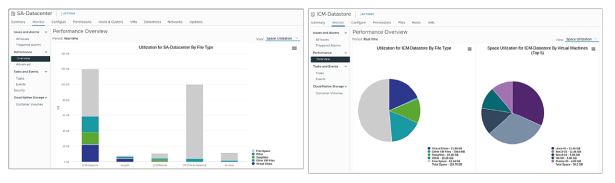
Les graphiques en barres affichent les métriques de stockage pour les datastores d’un centre de données sélectionné.
Chaque datastore est représenté par une barre dans le graphique.
Chaque barre affiche les métriques selon le type de fichier : disques virtuels, autres fichiers de VM, snapshots, fichiers d’échange (swap files) et autres fichiers.
Les graphiques en secteurs affichent les métriques de stockage pour un seul objet, selon les types de fichiers ou les machines virtuelles.
Par exemple, un graphique en secteurs pour un datastore peut afficher la quantité d’espace de stockage occupée par les VM utilisant le plus d’espace.
¶ Types de graphiques : en courbes
Un graphique en courbes peut afficher plusieurs métriques pour un seul objet d’inventaire, par exemple, les métriques de chaque processeur (CPU) sur un hôte ESXi.
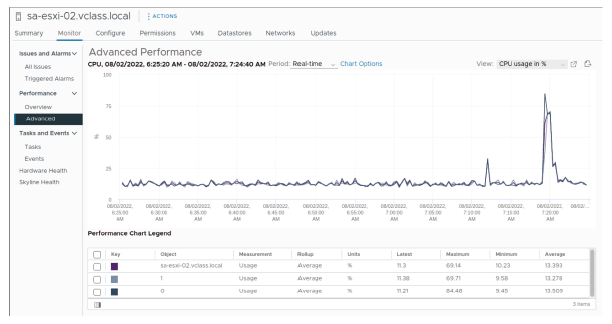
Dans un graphique en courbes, les données de chaque compteur de performance sont tracées sur une ligne distincte du graphique.
Par exemple, un graphique de processeur pour un hôte peut contenir une ligne pour chacun des processeurs de cet hôte. Chaque ligne représente l’utilisation du processeur au fil du temps.
¶ Types de graphiques : empilés
Les graphiques empilés sont utiles pour comparer l’allocation et l’utilisation des ressources entre plusieurs hôtes, machines virtuelles (VM) ou objets multiples.
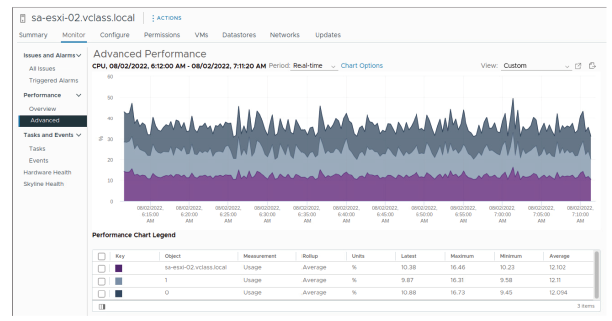
Les graphiques empilés ne permettent d’afficher qu’une seule métrique, contrairement aux graphiques en courbes qui peuvent en afficher plusieurs.
Les graphiques en courbes permettent généralement de montrer plus d’informations, mais les graphiques empilés sont en général plus faciles à lire.
¶ Types de graphiques : empilés par machine virtuelle
Les graphiques empilés par machine virtuelle (VM) sont disponibles uniquement pour les hôtes.
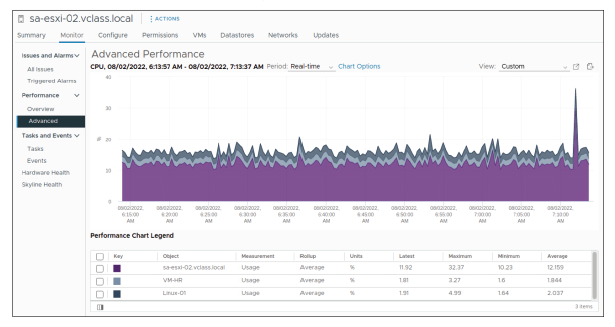
Les graphiques empilés affichent les métriques des objets enfants ayant les valeurs statistiques les plus élevées.
Tous les autres objets sont agrégés, et la valeur totale est affichée sous le terme Other (Autres).
Par exemple, un graphique empilé de l’utilisation du CPU d’un hôte affiche les métriques d’utilisation du CPU pour les cinq VM de l’hôte qui consomment le plus de ressources CPU.
La catégorie Other contient l’utilisation totale du CPU des VM restantes.
Les métriques de l’hôte lui-même sont affichées sous forme de graphiques en lignes distincts.
Par défaut, les 10 objets enfants ayant les valeurs de compteur de données les plus élevées apparaissent.
¶ Enregistrement des graphiques
Cliquez sur l’icône Save Chart (Enregistrer le graphique) située au-dessus du graphique pour enregistrer les informations de performance.
Vous pouvez enregistrer les informations aux formats PNG, JPEG, SVG et CSV.
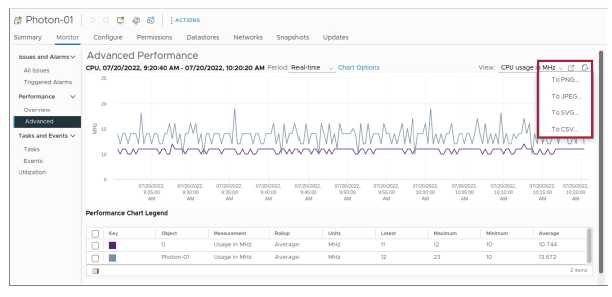
Dans le client vSphere, vous pouvez enregistrer les données issues des graphiques de performance avancée dans un fichier, soit sous divers formats d’image, soit au format CSV.
Lorsque vous enregistrez un graphique, vous sélectionnez le type de fichier et l’emplacement où le sauvegarder.
¶ À propos des objets et des compteurs
Les graphiques de performance affichent de manière graphique les métriques de CPU, mémoire, disque, réseau et stockage pour les dispositifs et entités gérés par vCenter.
Les objets sont des instances ou des agrégations de dispositifs :
- Exemples :
– vCPU moyen pour la machine virtuelle (VM)
– vmhba1
– Agrégation sur toutes les cartes réseau (NIC)
Les compteurs identifient quelles statistiques doivent être collectées :
- Exemples :
– CPU : Temps utilisé, temps prêt, utilisation (%)
– NIC : Paquets réseau reçus
– Mémoire : Mémoire échangée
Dans vCenter, vous pouvez déterminer la quantité d’informations affichées concernant un type de dispositif spécifique. Vous pouvez contrôler la quantité d’informations qu’un graphique affiche en sélectionnant un ou plusieurs objets et compteurs.
Un objet fait référence à une instance pour laquelle une statistique est collectée.
Par exemple, vous pouvez collecter des statistiques pour un CPU individuel, pour l’ensemble des CPU, pour un hôte ou pour un dispositif réseau spécifique.
Un compteur représente la statistique réelle que vous collectez.
Par exemple, la quantité de CPU utilisée ou le nombre de paquets réseau par seconde pour un dispositif donné.
¶ À propos des types de statistiques
Le type de statistique correspond à l’unité de mesure utilisée pendant l’intervalle statistique.
| Type de statistique | Description | Exemple |
|---|---|---|
| Rate (Taux) | Valeur sur l’intervalle courant | Utilisation du CPU (MHz) |
| Delta | Changement par rapport à l’intervalle précédent | Temps de préparation du CPU |
| Absolute (Absolue) | Valeur absolue, indépendante de l’intervalle | Mémoire active |
Le type de statistique fait référence à la mesure utilisée pendant l’intervalle statistique et est lié à l’unité de mesure.
Le type de statistique peut être l’un des suivants :
- Rate (Taux) : Valeur sur l’intervalle statistique actuel
- Delta : Variation par rapport à l’intervalle statistique précédent
- Absolute (Absolue) : Valeur absolue (indépendante de l’intervalle statistique)
Par exemple l’utilisation du CPU est un taux, le temps de préparation du CPU est un delta, la mémoire active est une valeur absolue.
¶ À propos du Rollup
Le Rollup est la fonction de conversion entre les intervalles statistiques.
- Les statistiques en temps réel (20 s) sont regroupées pour créer un point de données toutes les 5 minutes.
→ Résultat : 12 points de données par heure et 288 points de données par jour. - Après 30 minutes, les six points de données collectés sont agrégés et regroupés en un point de données pour la période de 1 semaine.
- Les statistiques quotidiennes (1 jour) sont regroupées pour créer un point de données toutes les 30 minutes.
→ Résultat : 48 points de données par jour et 336 points de données par semaine. - Toutes les 2 heures, les 12 points de données collectés sont agrégés et regroupés en un point de données pour la période de 1 mois.
¶ Types de Rollup
Le type de rollup détermine le type de valeurs statistiques renvoyées pour le compteur :
| Type de rollup | Fonction de conversion | Statistique d’échantillon |
|---|---|---|
| Average (Moyenne) | Moyenne des points de données | Utilisation du CPU (moyenne) |
| Summation (Somme) | Somme des points de données | Temps de préparation du CPU (millisecondes) |
| Latest (Dernier) | Dernier point de données | Temps de fonctionnement (jours) |
| Minimum (Minimum) | Point de données minimum actuel ou moyen | Disponible pour tous les compteurs lorsque la collecte des statistiques de vCenter est réglée sur le niveau 4 |
| Maximum (Maximum) | Point de données maximum actuel ou moyen | Disponible pour tous les compteurs lorsque la collecte des statistiques de vCenter est réglée sur le niveau 4 |
Les données sont affichées à différents niveaux de précision selon l’intervalle historique.
Les statistiques de la dernière heure sont affichées avec une précision de 20 secondes, tandis que les statistiques du jour précédent sont affichées avec une précision de 5 minutes.
La moyenne utilisée pour convertir les données d’un intervalle à un autre est appelée rollup.
Les valeurs minimales et maximales sont collectées et affichées uniquement au niveau de collecte 4. Les types de rollup minimum et maximum servent à capturer les pics dans les données pendant l’intervalle.
Pour les données en temps réel, la valeur correspond au minimum ou maximum actuel.
Pour les données historiques, la valeur correspond à la moyenne du minimum ou du maximum.
par exemple, les informations suivantes pour le graphique d’utilisation du CPU montrent que la moyenne est collectée au niveau de collecte 1, les valeurs minimales et maximales sont collectées au niveau de collecte 4.
- Compteur : Usage
- Unité : Pourcentage (%)
- Type de rollup : Average (Minimum/Maximum)
- Niveau de collecte : 1 (4)
Les niveaux statistiques incluent :
- Summation (Somme) : Les données collectées sont additionnées.
La mesure affichée dans le graphique de performance représente la somme des données collectées pendant l’intervalle. - Latest (Dernier) : Les données collectées pendant l’intervalle représentent une valeur instantanée.
La valeur affichée dans le graphique de performance correspond à la valeur actuelle.
Par exemple, si vous examinez le compteur CPU Used dans un graphique de performance CPU, le type de rollup est summation (somme).
Ainsi, pour un intervalle de 5 minutes, la somme de tous les échantillons de 20 secondes pendant cet intervalle est représentée.
¶ Revue des objectifs d’apprentissage
- Décrire la méthodologie d’optimisation des performances
- Identifier les outils de surveillance des ressources
- Utiliser les graphiques de performance de vCenter pour visualiser les performances
¶ Leçon 2 : Surveillance de l’utilisation des ressources
¶ Objectifs d’apprentissage
- Surveiller les principaux facteurs pouvant affecter les performances d’une machine virtuelle
- Utiliser les graphiques de performance pour visualiser et améliorer les performances
¶ Interprétation des données provenant des outils
Les outils de surveillance de vCenter et les outils de surveillance du système d’exploitation invité offrent des points de vue différents.
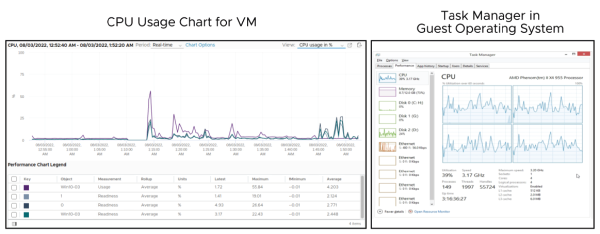
L’élément clé pour interpréter les données de performance consiste à observer l’ensemble des données depuis les perspectives du système d’exploitation invité, de la machine virtuelle et de l’hôte.
Par exemple, les statistiques d’utilisation du processeur dans le Gestionnaire des tâches ne donnent pas une vue complète de la situation. Consultez l’utilisation du processeur pour la machine virtuelle (VM) ainsi que pour l’hôte sur lequel elle est exécutée.
Utilisez les graphiques de performance dans le vSphere Client pour visualiser ces données.
¶ Machines virtuelles limitées par le processeur
Si l’utilisation du processeur (CPU) est continuellement élevée, la machine virtuelle (VM) est limitée par le CPU. Cependant, l’hôte peut encore disposer de suffisamment de ressources CPU pour exécuter d’autres machines virtuelles.
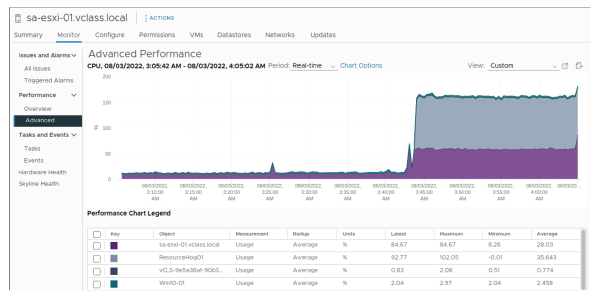
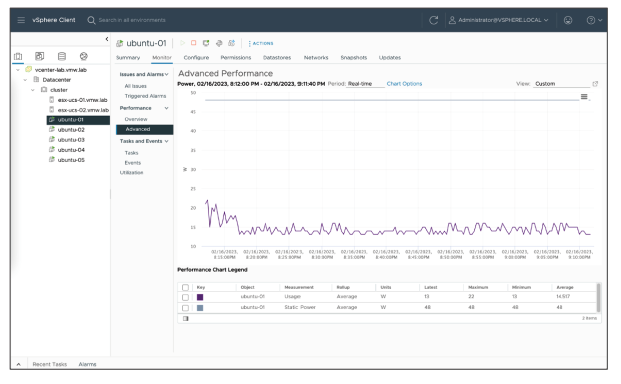
Si l’utilisation du CPU est élevée, vérifiez les statistiques d’utilisation CPU de la VM. Utilisez soit les graphiques de vue d’ensemble, soit les graphiques avancés pour consulter l’utilisation CPU. Cette diapositive montre un graphique avancé qui suit l’utilisation CPU d’une VM.
Si l’utilisation CPU d’une VM reste élevée sur une longue période, la VM est contrainte par le processeur. D’autres VMs sur le même hôte peuvent disposer de ressources CPU suffisantes pour répondre à leurs besoins.
Si plusieurs VMs sont limitées par le CPU, l’indicateur clé est le temps de préparation CPU (CPU ready time). Le temps de préparation correspond à la période pendant laquelle une VM est prête à exécuter des instructions, mais ne peut pas être planifiée sur un CPU. Plusieurs facteurs influencent la durée du temps de préparation :
- Utilisation globale du CPU : il est plus probable d’observer un temps de préparation lorsque l’utilisation CPU est élevée, car le CPU est plus souvent occupé lorsqu’une autre VM souhaite s’exécuter.
- Nombre de consommateurs de ressources (dans ce cas, les systèmes d’exploitation invités) : lorsqu’un hôte exécute un grand nombre de VMs, le planificateur est plus susceptible de mettre une VM en file d’attente derrière d’autres VMs déjà en cours d’exécution ou en attente.
La valeur optimale du temps de préparation varie selon la charge de travail.
Pour déterminer une bonne valeur de temps de préparation pour votre charge de travail, collectez les données de ready time sur une période pour chaque VM.
Une fois ces données recueillies, estimez dans quelle mesure les retards observés dans les temps de réponse sont dus à ce ready time.
Si les problèmes de performance des applications semblent principalement causés par un temps de préparation trop long, prenez des mesures pour réduire ce temps excessif.
Plusieurs machines virtuelles (VM) sont limitées par le CPU lorsque les conditions suivantes sont présentes :
- Utilisation élevée du processeur virtuel (vCPU) des machines virtuelles
- Valeurs de disponibilité du vCPU relativement élevées pour les VMs
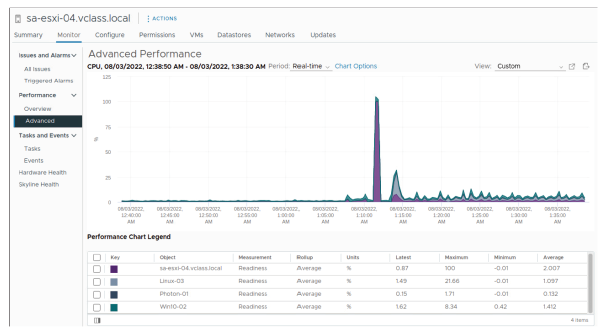
Pour déterminer si une VM est limitée par les ressources CPU, examinez l’utilisation du CPU dans le système d’exploitation invité, par exemple à l’aide du Gestionnaire des tâches ou des graphiques de performance.
Si plusieurs VMs sont limitées par le CPU, l’indicateur clé est la disponibilité CPU (CPU readiness). La disponibilité CPU correspond au pourcentage de temps pendant lequel une VM ne peut pas s’exécuter, car elle est en attente d’accès aux processeurs physiques.
Il est plus probable d’observer des valeurs élevées de disponibilité lorsque l’utilisation CPU est importante, car le processeur est plus souvent occupé lorsqu’une autre VM devient prête à s’exécuter.
Une bonne valeur de disponibilité varie selon la charge de travail.
¶ Machines virtuelles limitées par la mémoire
Comparez la mémoire consommée et la mémoire attribuée d’une machine virtuelle (VM) afin de déterminer si elle est limitée par la mémoire.
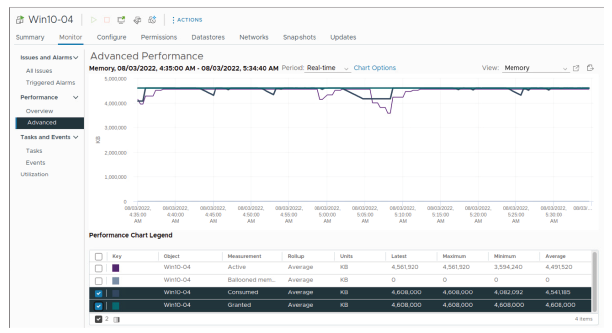
La mémoire consommée correspond à la quantité totale de mémoire utilisée sur l’hôte ESXi.
Cela inclut la mémoire utilisée par le VMKernel, les autres services vSphere et les agents de gestion, ainsi que la mémoire totale consommée par toutes les machines virtuelles en cours d’exécution.
La mémoire attribuée (granted memory) est la quantité totale de mémoire disponible pour la machine virtuelle.
Formule :
Mémoire consommée = Mémoire attribuée – Mémoire économisée grâce au partage de pages
Si une machine virtuelle utilise activement la totalité de la mémoire qui lui est attribuée, elle peut être considérée comme limitée par la mémoire.
Dans ce cas, il est recommandé d’augmenter la taille de la mémoire allouée à la machine virtuelle.
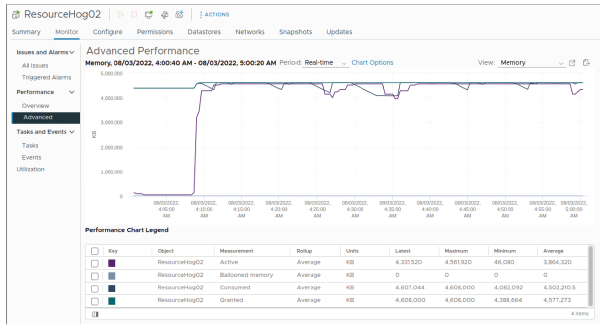
¶ Hôtes limités par la mémoire
Toute preuve de ballooning ou de swapping est un signe que votre hôte pourrait être limité par la mémoire.
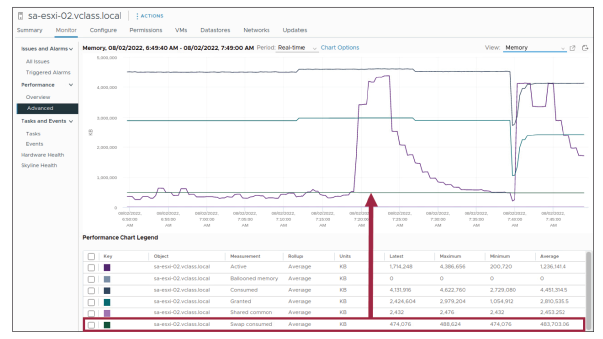
Vous pourriez observer des machines virtuelles présentant une activité élevée de ballooning et des VMs échangées (swappées) par le VMkernel.
Cette situation sérieuse indique que la mémoire de l’hôte est suroccupée (overcommitted) au point de provoquer une contention et qu’il est nécessaire d’augmenter la mémoire de l’hôte.
À ce stade, aucune VM n’utilise le ballooning, mais certaines subissent le swapping.
¶ Machines virtuelles limitées par le disque
Les applications intensives en accès disque peuvent saturer le stockage ou le chemin d’accès.
Si vous soupçonnez qu’une machine virtuelle est limitée par l’accès au disque, effectuez les actions suivantes :
- Mesurez le débit et la latence entre la machine virtuelle et le stockage.
- Utilisez les graphiques de performance avancés pour surveiller le débit et la latence :
- Taux de lecture et taux d’écriture
- Latence de lecture et latence d’écriture
Les problèmes de performance liés au disque sont souvent causés par la saturation du matériel de stockage physique sous-jacent.
Vous pouvez utiliser les graphiques de performance avancés de vCenter pour mesurer la performance du stockage à différents niveaux.
Ces graphiques fournissent des informations sur les performances d’une machine virtuelle et permettent de surveiller tout, du datastore de la VM jusqu’à un chemin de stockage spécifique.
Si vous sélectionnez un objet hôte, vous pouvez afficher le débit et la latence pour un datastore, un adaptateur de stockage ou un chemin de stockage.
Les graphiques d’adaptateurs de stockage sont disponibles uniquement pour les stockages Fibre Channel et iSCSI, mais pas pour NFS.
Si vous sélectionnez un objet de machine virtuelle, vous pouvez afficher le débit et la latence pour le datastore de la VM ou pour un disque virtuel spécifique.
Pour surveiller le débit, consultez les compteurs taux de lecture et taux d’écriture.
Pour surveiller la latence, consultez les compteurs latence de lecture et latence d’écriture.
¶ Surveillance de la latence disque
Pour identifier les problèmes de performance liés aux disques, surveillez deux compteurs de données de latence disque :
- Latence des commandes du noyau (Kernel command latency) :
- Ce compteur indique le temps moyen passé dans le VMkernel par commande SCSI.
- Des valeurs élevées (supérieures à 2 ms ou 3 ms) indiquent un ensemble de stockage ou un hôte surchargé.
- Latence des commandes du périphérique physique (Physical device command latency) :
- Ce compteur indique le temps moyen nécessaire pour qu’un périphérique physique exécute une commande SCSI, NVMe ou NVMe-of.
- Des valeurs élevées indiquent un ensemble de stockage lent ou surchargé, par exemple :
- Pour les disques mécaniques (HDD) : plus de 15 ms ou 20 ms.
- Pour les SSD : plus de 3 ms ou 4 ms.
Pour déterminer si votre environnement vSphere rencontre des problèmes de latence disque, surveillez ces compteurs de latence à l’aide des graphiques de performance avancés. En particulier, contrôlez les compteurs suivants :
- Latence des commandes du noyau : Ce compteur mesure le temps moyen, en millisecondes, que le VMkernel consacre au traitement de chaque commande SCSI. Pour des performances optimales, la valeur doit être comprise entre 0 et 1 ms. Si la valeur dépasse 4 ms, cela signifie que les VMs sur l’hôte ESXi tentent d’envoyer plus de débit vers le système de stockage que la configuration ne le permet.
- Latence des commandes du périphérique physique : Ce compteur mesure le temps moyen, en millisecondes, que le périphérique physique met pour exécuter une commande SCSI ou NVMe.
Stockage local vs stockage basé sur SAN :
- Le stockage local a des chemins plus courts et une bande passante plus élevée, ce qui se traduit par une latence plus faible.
- Les SAN couvrent de plus longues distances et peuvent donc présenter une latence plus élevée.
¶ Machines virtuelles limitées par le réseau
Les applications à forte utilisation réseau rencontrent souvent des goulots d’étranglement sur des segments de chemin situés en dehors de l’hôte ESXi.
- Exemple : liens WAN entre le serveur et le client.
Si vous suspectez qu’une machine virtuelle (VM) est limitée par le réseau, effectuez les actions suivantes :
- Vérifiez que VMware Tools est installé et que VMXNET3 est l’adaptateur réseau virtuel utilisé.
- Mesurez la bande passante effective entre la VM et son système pair.
- Vérifiez la présence de paquets reçus ou transmis perdus.
- Identifiez où les paquets sont perdus et dans quelle direction.
Comme pour les problèmes de performance disque, les problèmes de performance réseau sont souvent causés par la saturation d’un lien réseau entre le client et le serveur.
Utilisez un outil tel que Iometer ou un transfert de fichier volumineux pour mesurer la bande passante effective.
Les performances réseau dépendent de la charge de travail des applications et de la configuration du réseau.
Les paquets réseau perdus indiquent un goulot d’étranglement.
Pour déterminer si des paquets sont perdus, utilisez les graphiques de performance avancés afin d’examiner les compteurs droppedTx (paquets transmis perdus) et droppedRx (paquets reçus perdus) d’une VM.
En général, plus la taille des paquets réseau est grande, plus la vitesse du réseau est élevée.
Lorsque la taille des paquets est importante, moins de paquets sont transférés, ce qui réduit la charge CPU nécessaire pour traiter les données.
Dans certains cas, toutefois, de gros paquets peuvent provoquer une latence réseau élevée.
Inversement, lorsque les paquets sont petits, un plus grand nombre est transféré, mais la vitesse du réseau est plus faible, car le CPU doit traiter davantage de paquets.
¶ Lab 16 : Surveillance des performances des machines virtuelles
Utilisez les outils de surveillance du système pour examiner la charge de travail du processeur (CPU) :
- Créez une charge de travail CPU
- Utilisez les graphiques de performance pour surveiller l’utilisation du CPU
Retrouvez le lien du Lab en cliquant ici : Lab 16 : Accéder à l'environnement de lab
¶ Revue des objectifs d’apprentissage
- Surveillez les principaux facteurs pouvant affecter les performances d’une machine virtuelle.
- Utilisez les graphiques de performance pour visualiser et améliorer les performances.
¶ Leçon 3 : Surveillance de vCenter et des performances
¶ Objectifs d’apprentissage
- Passer en revue les composants et services de vCenter
- Décrire les facteurs qui influencent les performances de vCenter
- Utiliser les outils de vCenter pour surveiller l’utilisation des ressources de vCenter
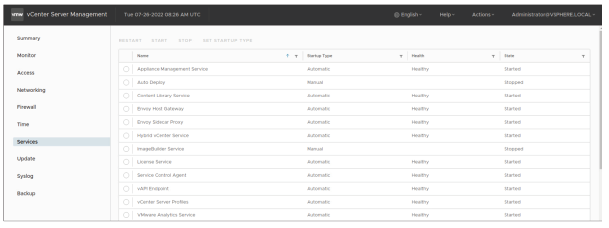
¶ Surveillance des services vCenter
Vous pouvez utiliser l’interface de gestion de vCenter (vCenter Management Interface) pour surveiller la santé et l’état des services de vCenter.
À partir de cette interface, vous pouvez redémarrer, démarrer ou arrêter les services.
¶ Mises à jour mensuelles des correctifs pour vCenter
VMware fournit des correctifs de sécurité mensuels pour vCenter :
- Les correctifs pour les vulnérabilités critiques sont publiés sur un cycle de mise à jour mensuel.
- Les vulnérabilités importantes et mineures sont corrigées avec le prochain correctif ou la prochaine mise à jour disponible de vCenter.
Vous pouvez configurer vCenter pour effectuer automatiquement une vérification des correctifs disponibles dans l’URL du référentiel configuré, à intervalles réguliers.
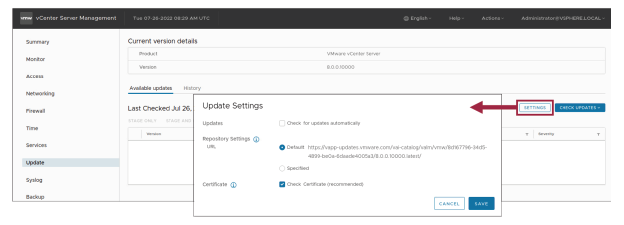
Si un correctif ou une mise à jour de vCenter est publié pendant la même période que le correctif de sécurité mensuel, ce dernier est intégré à la mise à jour ou au correctif de vCenter.
La vérification des mises à jour de vCenter peut être automatisée en activant l’option « Check for updates automatically ».
Sinon, vous devrez lancer ce processus manuellement.
¶ Considérations sur les performances de vCenter
Tenez compte des facteurs suivants lors de la surveillance et du maintien de niveaux de performance acceptables pour vCenter et ses services :
- Performances du processeur (CPU) et de la mémoire
- Performances du réseau
- Performances de la base de données
- Performances de l’interface utilisateur
¶ Performances du processeur (CPU) de vCenter
Pour des performances CPU optimales, vCenter ne doit pas dépasser 70 % d’utilisation du processeur.
Si l’utilisation du processeur par vCenter dépasse régulièrement 70 %, effectuez les étapes suivantes :
- Identifier les processus qui consomment le plus de CPU :
- Si le processus vpxd consomme la majeure partie du CPU, envisagez les solutions suivantes :
- Ajouter davantage de processeurs à la machine virtuelle vCenter.
- Ajouter une autre instance de vCenter et équilibrer la charge entre les instances.
- Si un service consomme la majeure partie du CPU, vous devrez peut-être augmenter la taille de la mémoire heap pour ce service.
- Si le processus vpxd consomme la majeure partie du CPU, envisagez les solutions suivantes :
- Examiner les plug-ins, extensions ou le code API personnalisé qui communique avec vCenter :
- Il peut être nécessaire d’augmenter les ressources pour permettre à ces extensions de fonctionner de manière optimale.
Une utilisation élevée et constante du CPU peut entraîner de faibles performances.
Vérifiez quels processus — tels que vpxd et vsphere-ui — consomment le plus de CPU.
Une utilisation du CPU supérieure à 70 % peut amener un processus vCenter à exécuter davantage de requêtes que nécessaire.
Les actions suivantes peuvent nécessiter une augmentation des ressources utilisées par l’instance vCenter, au-delà des recommandations fournies dans la documentation VMware :
- Ajout d’extensions à vCenter
- Ajout de code au vSphere Client
- Ajout d’un autre point d’extension pour collecter des données
- Exécution de davantage de services, ce qui peut nécessiter plus de CPU et de mémoire
Par exemple, avec NSX, l’exécution du service vSphere ESX Agent Manager (EAM) est connue pour augmenter la demande en ressources.
L’activation des paramètres CPU and Memory Hot Add sur la machine virtuelle vCenter permet d’ajouter du CPU et/ou de la mémoire sans interruption.
¶ Performances de la mémoire de vCenter
Surveillez à la fois l’utilisation du processeur (CPU) et de la mémoire dans vCenter afin de garantir que tous les services disposent de ressources suffisantes :
-
Si l’utilisation de la mémoire par vCenter dépasse régulièrement 70 %, effectuez les étapes suivantes :
— Vérifiez si vCenter effectue du swapping (échange mémoire-disque).
— Vérifiez quels services présentent une forte utilisation du CPU. Une forte utilisation du CPU peut indiquer un swapping excessif, car le processeur est utilisé pour effectuer les opérations d’échange mémoire. -
Il peut être nécessaire d’ajouter plus de mémoire si l’utilisation élevée est constante.
-
Si la mémoire est surengagée dans votre cluster, envisagez d’attribuer des réservations de mémoire pour vCenter.
vCenter constitue un composant essentiel de votre centre de données défini par logiciel (SDDC).
Pour des performances et une disponibilité maximales, assurez-vous que vCenter dispose de ressources suffisantes pour maintenir le bon fonctionnement de vos systèmes.
¶ Surveillance de l’utilisation du CPU et de la mémoire avec le VAMI
Utilisez l’interface de gestion de l’appliance virtuelle (VAMI) pour surveiller l’utilisation du processeur (CPU) et de la mémoire.
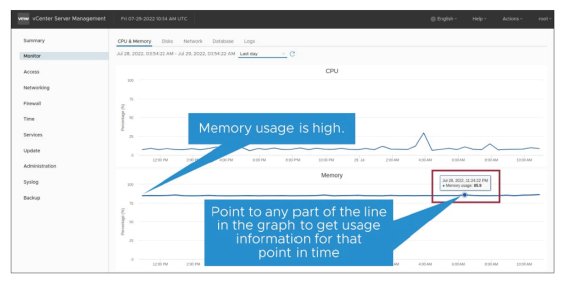
Pour accéder à l’interface de gestion de l’appliance virtuelle (VAMI), ouvrez un navigateur web et accédez à : https://<Nom_du_serveur_vCenter>:5480
Cliquez sur Monitor dans le panneau de gauche.
L’onglet CPU & Memory s’affiche par défaut.
¶ Utilisation de vimtop pour surveiller les ressources de l’appliance vCenter
vimtop est un outil en mode texte qui offre un moyen simple de surveiller l’utilisation des ressources de l’appliance vCenter.
L’outil vimtop présente les caractéristiques suivantes :
- Similaire à la commande esxtop
- Affiche des informations globales sur les ressources de l’appliance vCenter Server
- Affiche les services individuels et leur utilisation des ressources
Pour démarrer vimtop, vous devez d’abord lancer le shell Bash depuis une connexion en SSH sur l’appliance vCenter.
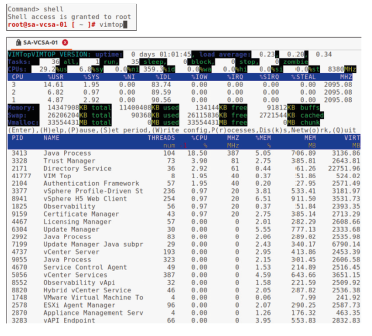
Pour accéder à vimtop, entrez la commande : vimtop
Pour afficher le menu d’aide de vimtop, entrez : h
Pour quitter vimtop, entrez : q
¶ Commandes et colonnes de vimtop
Par défaut, vimtop affiche la fenêtre Processes (Processus).
Vous pouvez ajouter des statistiques supplémentaires à l’affichage en entrant c et en sélectionnant les compteurs souhaités.
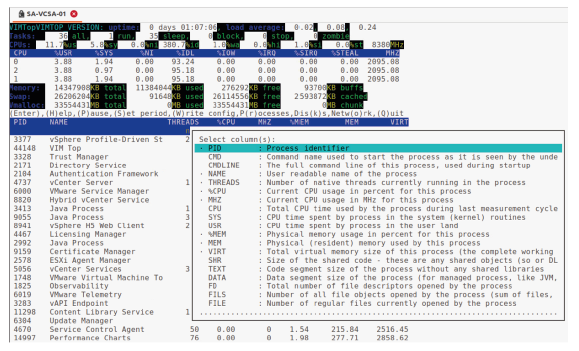
Pour ajouter une métrique (ou une colonne) à l’affichage de vimtop, procédez comme suit :
- Entrez
cpour afficher le panneau de sélection des colonnes. - Utilisez les flèches haut et bas pour mettre en surbrillance une métrique dans le panneau de sélection.
- Appuyez sur la barre d’espace pour sélectionner la métrique.
- Un tilde (
~) apparaît à gauche du nom de la métrique.
- Un tilde (
- Appuyez sur la touche Échap (Esc) pour quitter le panneau de sélection des colonnes.
¶ Surveillance de l’utilisation du processeur avec vimtop
La fenêtre Processes (Processus) affiche les métriques globales du processeur ainsi que celles des processus individuels.
Pour revenir à cette fenêtre, entrez r.
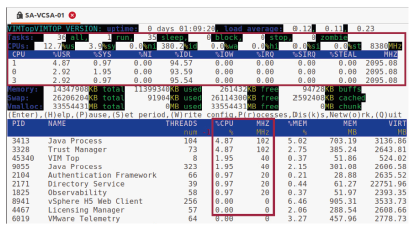
Vous pouvez surveiller l’utilisation globale du processeur à partir du panneau de vue d’ensemble ou examiner l’utilisation du processeur de chaque processus individuel dans le panneau des tâches.
Certaines colonnes affichées incluent :
- Name : nom convivial du processus (service).
- %CPU : utilisation actuelle du processeur (en pourcentage) pour ce processus. Si la valeur est de 100 %, cela signifie que le processus utilise un cœur complet.
- MHZ : utilisation actuelle du processeur (en mégahertz) pour ce processus.
¶ QCM : Utilisation du processeur et de la mémoire
En règle générale, vous devez maintenir l’utilisation du processeur et de la mémoire d’une instance vCenter en dessous de quel pourcentage ?
☐ 60 %
☐ 70 %
☐ 80 %
☐ 90 %
¶ Réponses : Utilisation du processeur et de la mémoire
En règle générale, vous devez maintenir l’utilisation du processeur et de la mémoire d’une instance vCenter en dessous de quel pourcentage ?
☐ 60 %
✓ 70 %
☐ 80 %
☐ 90 %
¶ Surveillance de l’utilisation de la mémoire avec vimtop
La fenêtre Processes affiche également les métriques globales de la mémoire et de la mémoire d’échange (swap).
Cette fenêtre montre aussi l’utilisation de la mémoire par les différents services du serveur vCenter.
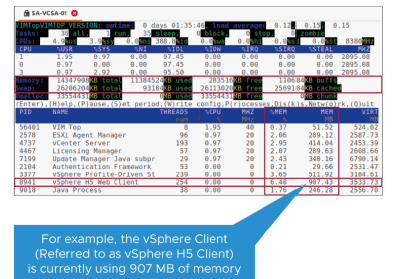
Par exemple, le client vSphere (appelé vSphere H5 Client) utilise actuellement 907 Mo de mémoire.
Certaines colonnes affichées incluent :
- %MEM : utilisation de la mémoire physique (en pourcentage) pour ce processus.
- MEM : mémoire physique ou résidente (en Mo) utilisée par ce processus.
- VIRT : taille totale de la mémoire virtuelle (en Mo). Cette valeur représente l’ensemble de la mémoire de travail, incluant la mémoire résidente et la mémoire d’échange (swapped memory).
¶ Visualisation de l’allocation mémoire des services avec cloudvm-ram-size
La commande cloudvm-ram-size affiche la quantité de mémoire allouée aux services du serveur vCenter.
La commande cloudvm-ram-size -l affiche la mémoire allouée (en Mo) pour chaque service.
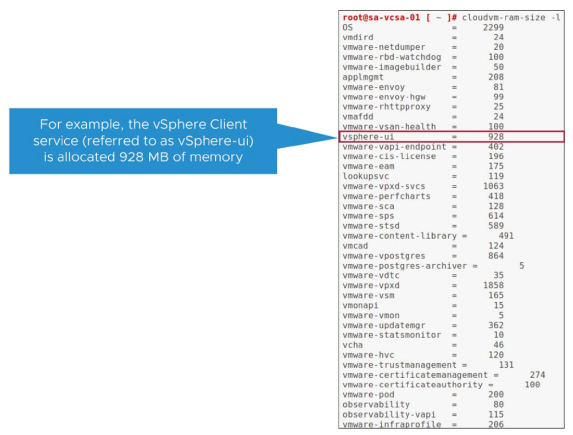
Par exemple, le service vSphere Client (référencé comme vSphere-ui) dispose d’une allocation de 928 Mo de mémoire.
¶ Visualisation de la taille du tas (Heap) d’un service
vCenter Server se compose de plusieurs services Java, tels que le service vSphere Client (vSphere-ui).
Un service Java utilise un heap, une zone de mémoire pré-réservée, pour stocker des objets de données.
Une taille de heap appropriée est essentielle pour que les services Java fonctionnent de manière optimale.
Par exemple, le service vSphere Client peut nécessiter davantage de mémoire de Heap dans les cas suivants :
- Plusieurs instances de vCenter Server en mode lié amélioré (enhanced linked mode)
- De nombreuses extensions et plug-ins
- Des inventaires volumineux
La commande suivante affiche la taille du Heap pour un service spécifique : cloudvm-ram-size -J service_name
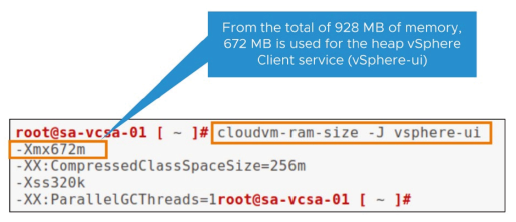
Sur un total de 928 Mo de mémoire, 672 Mo sont utilisés pour le Heap du service vSphere Client (vSphere-ui).
¶ Modification de la taille du tas (Heap) d’un service
Vous pouvez augmenter la taille du Heap d’un service vCenter Server afin de résoudre des problèmes de performance.
Pour modifier la taille du Heap, utilisez l’une des options suivantes :
- Redimensionner la mémoire de l’instance vCenter Server et redémarrer.
Les Heap sont automatiquement redimensionnés pour tous les services. - Redimensionner un service individuel et redémarrer ce service.
Aucun redémarrage global n’est nécessaire.
Pour redimensionner un service individuel, utilisez la commande suivante :cloudvm-ram-size -C <heap_size> <service_name>
Par exemple, la commande suivante modifie la taille du Heap du service vSphere Web Client à 700 Mo :cloudvm-ram-size -C 700 vsphere-ui
Si vous ne souhaitez pas le temps d’arrêt associé au redémarrage de vCenter Server après avoir ajouté de la mémoire, augmentez la taille du Heap de chaque service individuellement, puis redémarrez ce service.
Le Heap est automatiquement redimensionné.
¶ Performances réseau de vCenter
De nombreuses opérations de vCenter impliquent une communication entre vCenter et les hôtes ESXi, mais lorsque plusieurs vCenter sont configurés dans un domaine Single Sign-On en mode lié amélioré (Enhanced Linked Mode), les opérations de recherche nécessitent une communication entre les vCenter eux-mêmes :
- La bande passante réseau entre vCenter est généralement plus critique que la bande passante entre vCenter et les hôtes.
- Dans la plupart des cas, la latence des opérations est limitée par la latence des hôtes.
¶ Surveillance de l’activité réseau avec le VAMI
Utilisez le VAMI (Virtual Appliance Management Interface) pour surveiller l’activité réseau, qui inclut le débit en octets, les paquets perdus, les erreurs détectées et le taux de paquets.
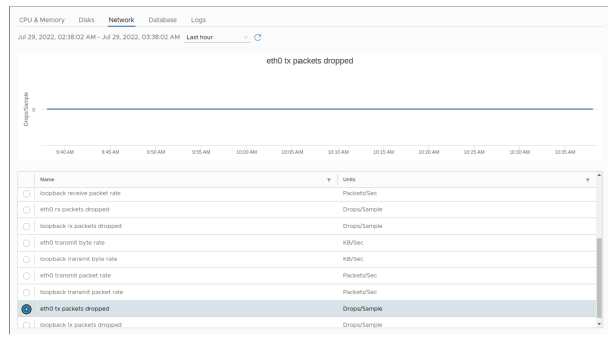
¶ Surveillance de l’activité réseau avec vimtop
Dans la fenêtre vimtop, entrez o pour afficher les métriques réseau.
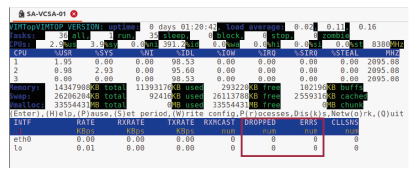
Vous pouvez surveiller les colonnes suivantes relatives à l’activité réseau :
- DROPPED : nombre de paquets perdus sur cette interface réseau, car le système a manqué de tampons (buffers) durant le dernier cycle de mesure.
- ERRS : nombre total d’erreurs de transmission et de réception sur cette interface.
¶ Performances de la base de données vCenter
Plusieurs facteurs doivent être pris en compte pour les performances de la base de données :
- En utilisation normale de vCenter, les ressources de la base de données (CPU, mémoire, disque et réseau) ne doivent pas être saturées.
- Une utilisation CPU élevée mais temporaire (par exemple, pendant un rollup) n’est pas un problème.
- Une utilisation CPU constamment élevée n’est pas normale.
Symptômes d’une utilisation CPU élevée :
- Les opérations de rollup ou les calculs Top-N sur un inventaire volumineux sont lents.
- Les requêtes historiques sur un large inventaire sont lentes.
Une utilisation CPU à 100 % pendant une longue période est anormale.
Lorsque vous observez une telle situation, vérifiez qu’aucun composant essentiel ne dysfonctionne.
Si votre inventaire est important, vous aurez de nombreuses statistiques à traiter.
Sans un sous-système disque rapide, assez de mémoire, ou une puissance CPU suffisante, les opérations de rollup ou les calculs Top-N peuvent devenir lents.
Un grand inventaire ne signifie pas seulement un grand nombre d’hôtes et de VM, mais aussi de nombreux datastores, réseaux ou périphériques par VM.
Certaines requêtes nécessitent plusieurs jointures ou des analyses complètes de tables — ce qui est rare, mais possible.
Dans ces cas, les statistiques de la base de données peuvent devoir être recalculées ou réindexées afin d’améliorer l’efficacité du moteur de requêtes.
Si vous constatez des requêtes historiques lentes et une utilisation CPU élevée et constante de la base de données :
- Vérifiez la base de données vPostgres :
— Recalculez les statistiques des tables de la base de données.
— Purgez les tables, réduisez la période de rétention ou abaissez le niveau de statistiques.
— Vérifiez les journaux vpxd, les journaux de la base de données, la taille des partitions et les tables SEAT.
Si vous utilisez un outil tiers (qui exploite le SDK VMware vSphere Web Services) pour obtenir des données historiques :
- Vérifiez les requêtes.
- Examinez les tables des événements, des tâches et des statistiques.
Si vous rencontrez des calculs de rollup ou Top-N lents :
- Ajoutez des processeurs (CPU).
- Vérifiez l’utilisation de la mémoire.
- Vérifiez l’état des rollups.
- Vérifiez les alarmes.
Vous pouvez consulter le journal vpxd pour diagnostiquer les problèmes.
Vous pourriez y voir apparaître des entrées telles que : [VdbStatement] Execution elapsed time: et / ou SQL execution took too long.
Il est normal d’en voir quelques-unes (souvent liées aux calculs Top-N, statistiques ou événements).
Chacune dure généralement entre 3 et 4 secondes.
Cependant, si ces événements sont très fréquents et durent 10 secondes ou plus, cela indique souvent un problème dans la base de données.
Dans ce cas, vérifiez les ressources (I/O, CPU et mémoire) et assurez-vous que la base de données est correctement dimensionnée.
¶ Effets de la modification du niveau de statistiques sur le trafic de la base de données
vCenter utilise un niveau de collecte, ou niveau de statistiques, pour déterminer la quantité de données collectées et stockées dans la base de données.
Lorsque vous augmentez le niveau de statistiques, les besoins en stockage et les exigences système changent.
La configuration des machines virtuelles (VM) et des hôtes, ainsi que le nombre de datastores, influencent directement le nombre de statistiques générées.
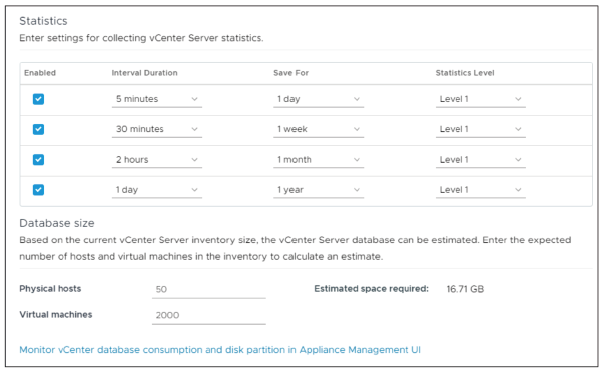
Lorsque vous passez du niveau 1 au niveau 2, le nombre de compteurs de stockage et de réseau augmente considérablement.
| Matériel | VM 1 | VM 2 | Hôte ESXi |
|---|---|---|---|
| Processeurs (CPU) | 2 | 2 | 48 (logiques) |
| Disques virtuels | 11 | 1 | 13 |
| Datastores | 1 | 1 | 9 |
| Cartes réseau (NIC) | 1 | 1 | 3 |
| Niveau de statistiques | VM 1 | VM 2 | Hôte ESXi |
|---|---|---|---|
| 1 | 67 | 34 | 223 |
| 2 | 231 | 148 | 858 |
| 3 | 263 | 184 | 1 779 |
| 4 | 348 | 196 | 1 967 |
Les tableaux montrent ce qui se passe lorsque différents niveaux de statistiques sont utilisés.
Le premier tableau illustre la configuration de deux machines virtuelles (VM) et d’un hôte ESXi.
La configuration de vos VMs et de vos hôtes est essentielle pour déterminer le nombre de statistiques générées.
Dans cet exemple, les configurations des VMs sont identiques, à l’exception du nombre de disques virtuels.
Le deuxième tableau montre les effets de l’augmentation du niveau de statistiques.
Parmi les quatre niveaux disponibles, le niveau 1 est le moins détaillé et le niveau 4 le plus détaillé.
Les chiffres exacts ne sont pas aussi importants que la forte augmentation observée entre le niveau 1 et le niveau 2.
Le niveau 1 rend compte de statistiques agrégées (CPU, latence des disques, etc.).
Le niveau 2 fournit des statistiques plus détaillées, comme celles par carte réseau (NIC) ou par datastore.
Dans le second tableau, on observe que VM1 possède bien plus de statistiques que VM2, car elle comporte davantage de disques virtuels.
Des compteurs supplémentaires liés au stockage et au réseau (par exemple : nombre de requêtes de lecture/écriture par seconde ou de paquets envoyés/reçus) sont introduits à partir du niveau 2.
Ainsi, plus votre configuration contient de disques et de réseaux, plus le nombre de statistiques générées augmente.
Dans votre environnement, veillez à dimensionner correctement l’infrastructure et la base de données pour accommoder la charge générée par le niveau de statistiques choisi.
¶ Utilisation des disques par vCenter
La base de données vCenter est le principal consommateur de bande passante disque et elle effectue un grand nombre d’opérations d’écriture.
Les partitions en surbrillance doivent être stockées sur un support de stockage à haute vitesse.
| Disque (VMDK) | Taille minimale | Point de montage | Utilisation |
|---|---|---|---|
| VMDK1 | 12 Go | / (10 Go), /boot (123 Mo), SWAP (1 Go) | Images du noyau et configurations du chargeur d’amorçage |
| VMDK2 | 1,8 Go | /tmp | Fichiers temporaires |
| VMDK3 | 25 Go | SWAP | Utilisé lorsque le système manque de mémoire et doit échanger sur le disque |
| VMDK4 | 25 Go | /storage/core | Vidages mémoire du processus vpxd |
| VMDK5 | 10 Go | /storage/log | Journaux de vCenter |
| VMDK6 | 10 Go | /storage/db | Emplacement de stockage de la base de données VMware Postgres |
| VMDK7 | 15 Go | /storage/dblog | Emplacement des journaux de la base de données VMware Postgres |
| VMDK8 | 10 Go | /storage/seat | Statistiques, événements, alarmes et tâches pour VMware Postgres |
La principale source d’activité disque (I/O) provient de la base de données.
Les partitions qui consomment le plus de bande passante disque sont :
/storage/db: emplacement de la base de données vCenter/storage/dblog: journaux de la base de données/storage/seat: statistiques, événements et alarmes
Assurez-vous que ces partitions se trouvent sur un stockage rapide et disposent de suffisamment d’espace.
| Disque (VMDK) | Taille minimale | Point de montage | Utilisation |
|---|---|---|---|
| VMDK9 | 1 Go | /storage/netdump | Dépôt du collecteur vSphere Netdump pour les vidages ESXi |
| VMDK10 | 10 Go | /storage/autodeploy | Dépôt vSphere Auto Deploy |
| VMDK11 | 10 Go | /storage/imagebuilder | Dépôt vSphere ESXi Image Builder |
| VMDK12 | 100 Go | /storage/updatemgr | Dépôt vSphere Lifecycle Manager |
| VMDK13 | 50 Go | /storage/archive | Dépôt utilisé pour l’archivage de fichiers |
| VMDK14 | 10 Go | /storage/vtsdb | Dépôt du service VMware vTSDB qui stocke les statistiques |
| VMDK15 | 5 Go | /storage/vtsdblog | Dépôt du service VMware vTSDB qui stocke les journaux du service |
| VMDK16 | 100 Go | /storage/lifecycle | Répertoire de Workload Control Plane stockant les binaires d’installation, de mise à jour et de mise à niveau |
| VMDK17 | 24,5 Go | /storage/lvm_snapshot | Permet à vCenter d’être mis à niveau plus efficacement |
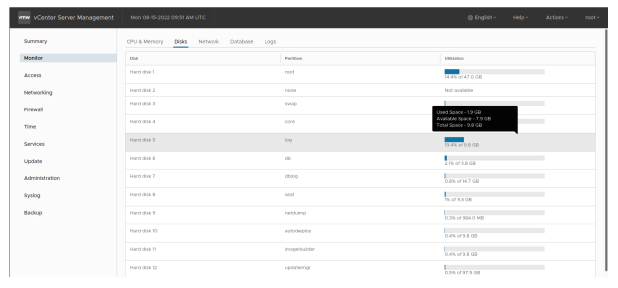
¶ Surveillance de l’utilisation du disque avec le VAMI
Utilisez le VAMI pour surveiller l’utilisation du disque par partition.
Pointez sur une partition pour afficher les informations concernant l’espace utilisé, l’espace disponible et l’espace total.
¶ Surveillance de l’utilisation du disque avec la commande df
Vous pouvez également surveiller l’utilisation du disque depuis la ligne de commande de vCenter Server Appliance en utilisant la commande : df -h
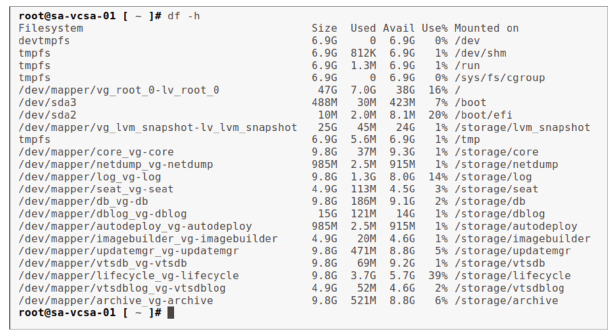
La commande df affiche des informations sur l’utilisation du système de fichiers, telles que la taille totale, l’espace utilisé et l’espace disponible.
L’option -h affiche les tailles dans des unités basées sur des puissances de 1024 — par exemple en mégaoctets, gigaoctets, etc.
¶ Surveillance de l’activité du disque avec vimtop
Dans la fenêtre vimtop, entrez k pour afficher les métriques du disque.
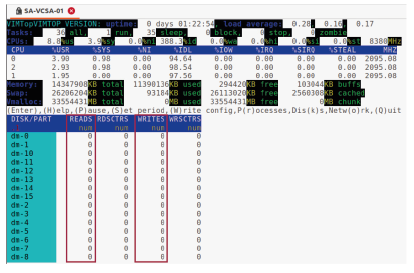
Les colonnes suivantes indiquent :
- READS : Nombre de lectures effectuées sur cette partition et terminées avec succès durant le dernier intervalle de mesure.
- WRITES : Nombre d’écritures effectuées sur cette partition et terminées avec succès durant le dernier intervalle de mesure.
¶ Surveillance de l’utilisation du disque avec Appliance Shell
En utilisant l’interface en ligne de commande de gestion de l’appliance (Appliance Management CLI), la commande suivante permet de surveiller l’utilisation du disque : com.vmware.appliance.version1.resources.storage.stats.list
Cette commande doit être exécutée depuis l’invite Command>.
Elle ne fonctionne pas si elle est saisie à l’intérieur de l’invite du shell.
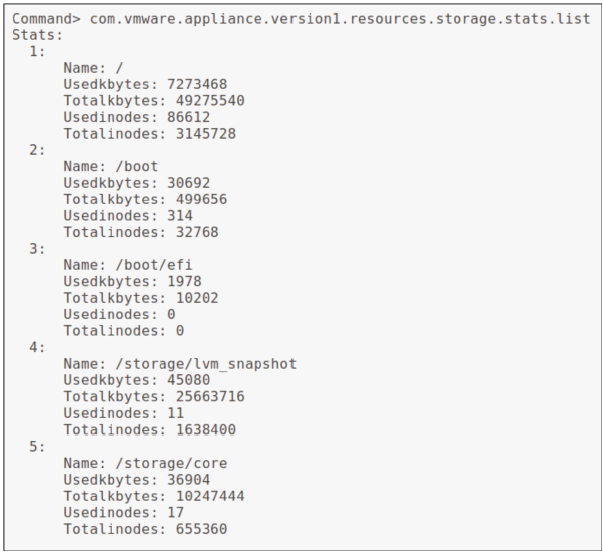
Consultez l’article de la base de connaissances VMware 2145603 à l’adresse suivante : http://kb.vmware.com/kb/2145603
¶ Augmenter l’espace disque pour vCenter
- Depuis ESXi Host Client, éteignez la machine virtuelle vCenter.
- Faites un clic droit sur la machine virtuelle.
- Cliquez sur Modifier les paramètres (Edit Settings).
- Sélectionnez Disque virtuel (Virtual Disk).
- Augmentez la taille du disque, en vous assurant qu’aucun instantané (snapshot) n’est attaché à la machine virtuelle.
- Démarrez la machine virtuelle.
- Utilisez ensuite le BASH Shell ou l’Appliance Shell pour étendre la ou les partitions logiques.
- Depuis le BASH Shell :
/usr/lib/applmgmt/support/scripts/autogrow.sh - Depuis l’Appliance Shell :
com.vmware.appliance.system.storage.resize
- Depuis le BASH Shell :
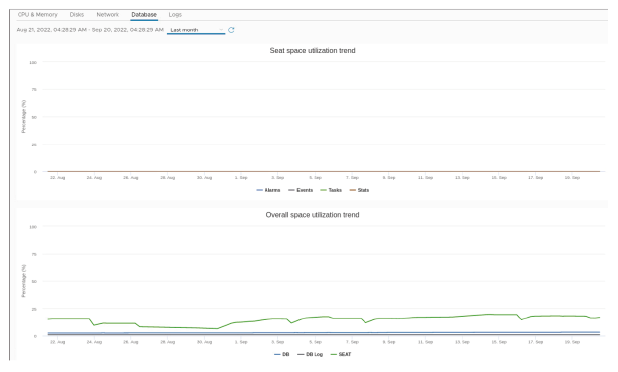
¶ Surveillance de l’activité de la base de données avec le VAMI
Utilisez le VAMI pour surveiller les tendances d’utilisation de l’espace pour SEAT (statistiques, événements, alertes et tâches), l’activité de la base de données, l’activité des journaux de la base de données et l’activité des données d’inventaire (core).
¶ Suivre vos progrès vers les objectifs de durabilité
Introduit dans vSphere 8.0, le vSphere Client permet aux administrateurs de suivre et de mesurer en temps réel la consommation d’énergie, les émissions de carbone et d’autres indicateurs liés à la durabilité environnementale.
Des métriques sont désormais disponibles pour mesurer la consommation électrique d’un hôte, y compris l’énergie utilisée par les charges de travail des machines virtuelles.
Les principales fonctionnalités comprennent :
- Amélioration de la durabilité
- Réduction des coûts
- Rapports améliorés
¶ NOUVEAUTÉ : Métriques écologiques améliorées de vSphere
Introduit dans vSphere 8.0 Update 1, les administrateurs peuvent désormais obtenir les métriques de consommation énergétique pour chacune des machines virtuelles (VM) et accéder à une vue agrégée de leurs données de consommation électrique.
¶ QCM : Performance du réseau
Lequel des facteurs suivants peut affecter les performances réseau dans votre environnement ?
☐ Bande passante et latence du réseau
☐ Nombre de cœurs CPU attribués à une machine virtuelle
☐ Durée de fonctionnement (uptime) de la machine virtuelle
☐ Quantité de mémoire RAM attribuée à une machine virtuelle
¶ Réponses : Performance du réseau
Lequel des facteurs suivants peut affecter les performances réseau dans votre environnement ?
✓ Bande passante et latence du réseau
☐ Nombre de cœurs CPU attribués à une machine virtuelle
☐ Durée de fonctionnement (uptime) de la machine virtuelle
☐ Quantité de mémoire RAM attribuée à une machine virtuelle
¶ QCM : Outils vCenter
Lequel des outils suivants pouvez-vous utiliser pour surveiller l’espace libre dans la base de données vCenter ?
(Sélectionnez toutes les réponses applicables.)
☐ df
☐ vCenter Advanced Performance Charts
☐ vSphere Client
☐ VAMI
¶ Réponses : Outils vCenter
Lequel des outils suivants pouvez-vous utiliser pour surveiller l’espace libre dans la base de données vCenter ?
(Sélectionnez toutes les réponses applicables.)
✓ df
☐ vCenter Advanced Performance Charts
☐ vSphere Client
✓ VAMI
¶ Revue des objectifs d’apprentissage
- Revoir les composants et services de vCenter
- Décrire les facteurs qui influencent les performances de vCenter
- Utiliser les outils vCenter pour surveiller l’utilisation des ressources de vCenter
¶ Leçon 4 : Utilisation des alarmes
¶ Objectifs d’apprentissage
- Utiliser les alarmes prédéfinies dans vCenter
- Visualiser et reconnaître les alarmes
- Créer des alarmes personnalisées
¶ À propos des alarmes
Une alarme est une notification envoyée en réponse à un événement ou à une condition qui se produit sur un objet dans l’inventaire.
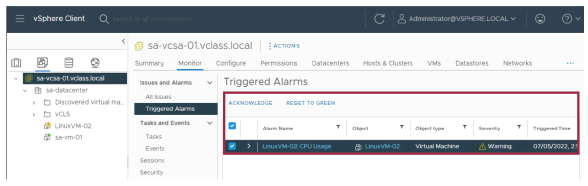
Vous pouvez reconnaître (acknowledge) une alarme pour informer les autres utilisateurs que vous prenez en charge le problème.
Par exemple, une machine virtuelle (VM) peut avoir une alarme configurée pour surveiller l’utilisation du processeur (CPU).
L’alarme est configurée pour envoyer un e-mail à un administrateur lorsqu’elle est déclenchée.
Si l’utilisation CPU de la VM augmente soudainement, l’alarme se déclenche et envoie un e-mail à l’administrateur.
L’administrateur reconnaît alors l’alarme afin d’informer les autres administrateurs que le problème est en cours de traitement.
Après avoir reconnu une alarme, les actions associées à cette alarme sont interrompues, mais l’alarme n’est pas effacée ou réinitialisée.
Vous pouvez réinitialiser manuellement l’alarme dans le vSphere Client pour la ramener à un état normal, ou bien elle reviendra automatiquement à l’état normal selon ses règles de réinitialisation.
¶ Alarmes prédéfinies
Vous pouvez accéder à de nombreuses alarmes prédéfinies pour différents objets de l’inventaire, tels que les hôtes, les machines virtuelles, les datastores, les réseaux, et ainsi de suite.
Vous pouvez modifier les alarmes prédéfinies, ou créer une copie d’une alarme existante afin d’ajuster ses paramètres selon vos besoins.
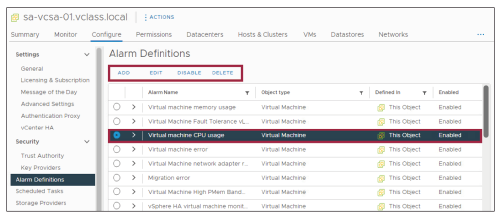
Pour faire une copie d’une alarme, sélectionnez l’objet concerné dans l’inventaire.
Ensuite, accédez à : Security > Alarm Definitions
Enfin, sélectionnez l’alarme souhaitée, cliquez sur ADD, puis poursuivez la procédure à l’aide de l’assistant.
¶ Création d’une alarme personnalisée
En plus d’utiliser des alarmes prédéfinies, vous pouvez créer des alarmes personnalisées dans le vSphere Client.
L’objet sélectionné dans l’inventaire détermine la portée de l’alarme.
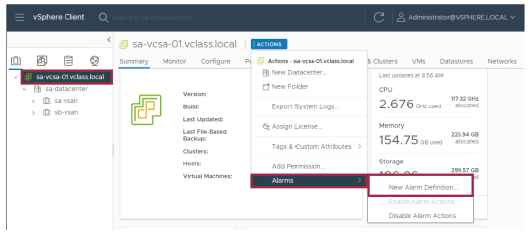
Si les alarmes prédéfinies ne couvrent pas l’événement, l’état ou la condition que vous souhaitez surveiller, créez une alarme personnalisée plutôt que de modifier une alarme prédéfinie.
¶ Définition du type de cible de l’alarme
Sur la page Name and Targets, vous devez nommer l’alarme, lui donner une description, et sélectionner le type d’objet d’inventaire que cette alarme doit surveiller.
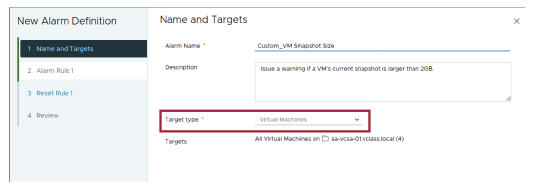
Selon l’objet sur lequel l’alarme est définie, vous pouvez créer des alarmes personnalisées pour les types de cibles suivants :
- Machines virtuelles
- Hôtes, clusters et centres de données
- Datastores et clusters de datastores
- Commutateurs distribués et groupes de ports distribués
- vCenter
¶ Définir la règle d’alarme : Déclencheur basé sur une condition
Une règle d’alarme doit contenir au moins un déclencheur.
Un déclencheur peut surveiller l’état ou la condition actuelle d’un objet, par exemple :
- L’instantané actuel d’une machine virtuelle dépasse 2 Go.
- Un hôte utilise 90 % de sa mémoire totale.
- Un datastore est déconnecté de tous les hôtes.
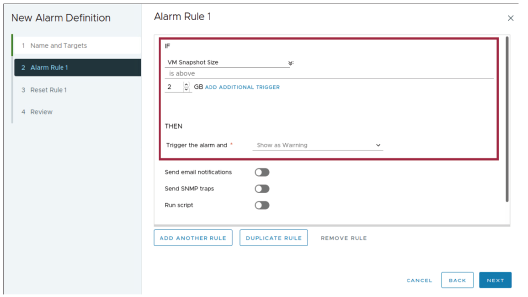
Vous configurez le déclencheur d’alarme pour qu’il s’affiche comme un avertissement ou un événement critique lorsque les critères spécifiés sont remplis.
- Vous pouvez surveiller l’état ou la condition actuelle des machines virtuelles, hôtes et datastores.
Les conditions ou états incluent les états d’alimentation, les états de connexion, ainsi que des mesures de performance comme l’utilisation du processeur (CPU) et du disque. - Vous pouvez également surveiller les événements qui se produisent en réponse à des opérations effectuées sur un objet géré dans l’inventaire ou dans vCenter lui-même.
Par exemple, un événement est enregistré chaque fois qu’une machine virtuelle (qui est un objet géré) est clonée, créée, supprimée, déployée ou migrée.
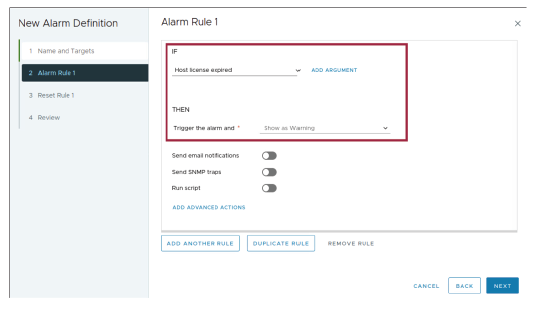
¶ Définir la règle d’alarme : Déclencheur basé sur un événement
Un déclencheur peut surveiller les événements qui se produisent en réponse à des opérations effectuées sur un objet géré, par exemple :
- L’état matériel d’un hôte change.
- Une licence arrive à expiration dans le centre de données.
- Un hôte quitte le commutateur distribué.
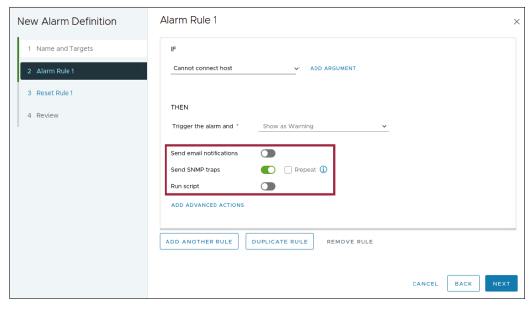
¶ Définir la règle d’alarme : Configuration de la notification
Vous configurez la méthode de notification à utiliser lorsque l’alarme est déclenchée.
Les méthodes possibles sont l’envoi d’un e-mail, l’envoi d’un piège SNMP (SNMP trap), l’exécution d’un script.
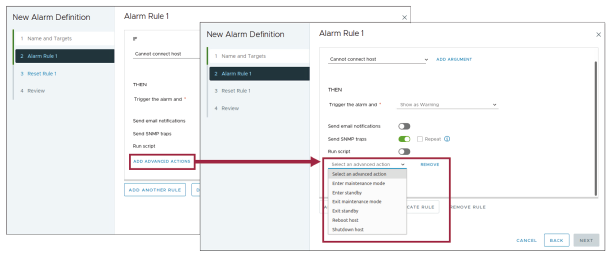
¶ Définir la règle d’alarme : Ajouter des options avancées
Vous pouvez définir des actions avancées pour les machines virtuelles et les hôtes.
Il existe différents ensembles d’actions avancées selon le type de cible — machine virtuelle ou hôte.
¶ Définir les règles de réinitialisation de l’alarme
Vous pouvez sélectionner et configurer les événements, états ou conditions permettant de réinitialiser l’alarme à son état normal.
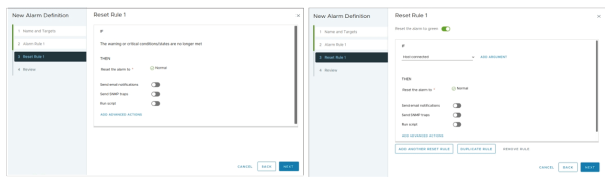
Parfois, comme dans l’exemple de gauche, vous n’avez accès qu’à une seule option pour réinitialiser l’alarme.
À droite, vous avez une alarme basée sur un événement, qui est plus configurable.
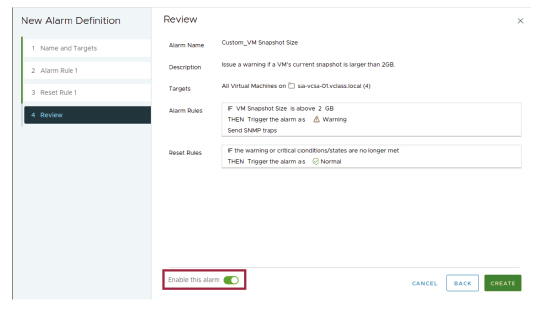
¶ Activation de l’alarme
Sur la page Review (Révision), la nouvelle définition d’alarme est activée par défaut.
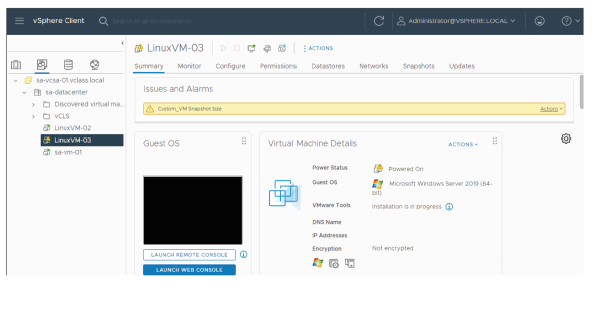
¶ Alarmes déclenchées
Lorsqu’elle est déclenchée, une alarme apparaît dans le vSphere Client.
¶ Configuration des notifications vCenter
Si vous utilisez le courrier électronique ou les trappes SNMP comme méthode de notification, vous devez configurer vCenter pour prendre en charge ces méthodes de notification.
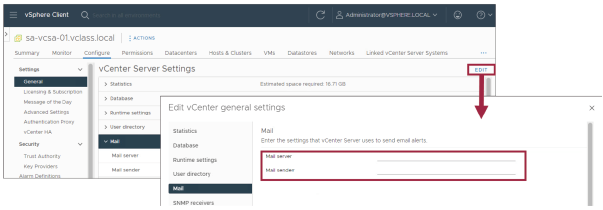
Pour configurer le courrier électronique, spécifiez le FQDN ou l’adresse IP du serveur de messagerie ainsi que l’adresse e-mail du compte de l’expéditeur.
Vous pouvez configurer jusqu’à quatre destinataires de trappes SNMP.
Ils doivent être configurés dans l’ordre numérique.
Chaque trappe SNMP nécessite un nom d’hôte, un port et une communauté correspondants.
¶ Lab 17 : Utilisation des alarmes
Créez des alarmes pour surveiller les événements et les conditions des machines virtuelles :
- Créer une alarme de machine virtuelle pour surveiller une condition
- Déclencher l’alarme de machine virtuelle
- Créer une alarme de machine virtuelle pour surveiller un événement
- Déclencher l’alarme de machine virtuelle
- Désactiver les alarmes de machine virtuelle
- Vérification des connaissances
Retrouvez le lien du Lab en cliquant ici : Lab 17 : Accéder à l'environnement de lab
¶ Revue des objectifs d’apprentissage
- Utiliser des alarmes prédéfinies dans vCenter
- Afficher et reconnaître les alarmes
- Créer des alarmes personnalisées
¶ Leçon 5 : Gestion proactive avec VMware Skyline
¶ Objectifs d’apprentissage
- Décrire les avantages et les fonctionnalités de VMware Skyline
- Expliquer le fonctionnement de VMware Skyline
- Identifier les types d’informations de santé fournis par Skyline Health
- Reconnaître les utilisations de Skyline Advisor Pro
¶ À propos de VMware Skyline
VMware Skyline est une technologie de support qui fournit des analyses prédictives et des recommandations proactives pour aider à éviter les problèmes. VMware Skyline offre les avantages suivants :
-
Prévention des problèmes :
— Identifie de manière proactive les problèmes potentiels en fonction de la configuration, des détails et de l’utilisation spécifiques à l’environnement.
— Résout les problèmes avant qu’ils ne surviennent, améliorant ainsi la fiabilité et la stabilité de l’environnement. -
Réduction du temps de résolution :
— Les analyses spécifiques à l’environnement et basées sur les données accélèrent la résolution des problèmes. -
Recommandations personnalisées :
— Les solutions sont adaptées à votre environnement. -
Aucun coût supplémentaire :
— Vous bénéficiez d’une valeur ajoutée avec votre abonnement de support actuel (Basic, Production ou Premier).
VMware Skyline réduit le temps nécessaire à la résolution d’un problème, vous permettant ainsi de reprendre rapidement vos activités.
Les ingénieurs du support technique VMware peuvent utiliser VMware Skyline pour visualiser la configuration de votre environnement et les analyses basées sur les données afin d’accélérer la résolution des problèmes.
¶ VMware Skyline Family
La famille VMware Skyline comprend Skyline Health et Skyline Advisor Pro.
¶ Skyline Health
Pour tous les clients VMware
Principales fonctionnalités :
- Analyse et constats pour vSphere et vSAN
- Disponible dans le client vSphere
- Compatible avec vSphere 6.7 et versions ultérieures
¶ Skyline Advisor Pro
Pour les clients disposant d’un support Production ou Premier
Principales fonctionnalités :
- Prend en charge vSphere, vSAN, NSX for vSphere, vRealize Operations Manager et VMware Horizon
- Compatible avec vSphere 5.5 et versions ultérieures
- Identification des déploiements VMware Validated Design, VxRail et VMware Cloud Foundation
- Automatise le transfert des journaux via Log Assist
- Utilise une identité et un accès basés sur le cloud
Pour les clients disposant d’un support Premier
Principales fonctionnalités :
- Analyses et rapports avancés
- Plans de correction personnalisés
Avec un support Basic, vous pouvez accéder aux résultats et recommandations Skyline pour vSphere et vSAN en utilisant Skyline Health dans le client vSphere (version 6.7 et ultérieure).
Avec un support Production ou Premier, vous pouvez utiliser Skyline Advisor Pro et profiter de toutes les fonctionnalités de Skyline (y compris Log Assist).
Avec le support Premier, vous bénéficiez de fonctionnalités Skyline supplémentaires qui ne sont pas disponibles avec le support Production, par exemple :
- Un ensemble avancé de résultats et de recommandations
- Des rapports opérationnels planifiés et personnalisés qui offrent une vue d’ensemble des résultats et recommandations proactives
- Tous les avantages supplémentaires du support Premier, notamment une équipe de support dédiée, un accès direct à des ingénieurs de support technique de niveau supérieur, une assistance pour le dépannage multi-fournisseurs et les services sur site, tels que Mission Critical Support (MCS), Healthcare Critical Support (HCS), Carrier Grade Support (CGS)
Skyline prend en charge vSphere, NSX for vSphere, vSAN, VMware Horizon et vRealize Operations Manager.
Un pack de gestion Skyline pour vRealize Operations Manager est également disponible.
Si vous installez ce pack, vous pouvez consulter les résultats et recommandations proactives Skyline directement dans le client vRealize Operations Manager.
L’identification et le marquage des déploiements VxRail et VMware Validated Design permettent à VMware Technical Support de mieux comprendre et prendre en charge les solutions multi-produits.
Skyline identifie tous les objets ESXi 5.5 au sein d’une instance vCenter et fournit des informations supplémentaires dans l’article de la base de connaissances VMware : https://kb.vmware.com/s/article/51491
Cet article décrit les détails de fin de support général pour vSphere 5.5.
Pour les versions de vSphere, vSAN, NSX for vSphere, VMware Horizon et vRealize Operations Manager prises en charge par Skyline, consultez les notes de version de Skyline Collector à l’adresse suivante : https://docs.vmware.com/en/VMware-Skyline/index.html
¶ Politique de confidentialité et de sécurité de Skyline
VMware s’engage à garder vos données privées et sécurisées :
-
L’appliance Skyline Collector est séparée de votre environnement :
— Votre infrastructure de production n’est pas exposée à Internet. -
Les données collectées sont transmises à VMware via un canal chiffré :
— Les données ne sont stockées que temporairement dans l’appliance Skyline Collector. -
Les données sont hébergées dans un système back-end sécurisé aux États-Unis et géré par VMware :
— L’accès à vos données est restreint uniquement aux utilisateurs autorisés. -
Les informations sont limitées à des données telles que les noms d’hôtes :
— Les données permettant d’identifier une personne ne sont pas collectées.
Skyline collecte les données de manière privée et sécurisée.
Votre infrastructure de production n’est pas exposée à Internet.
Toutes les données collectées sont marquées avec des informations clients légalement identifiables.
Aucune donnée client n’est stockée de manière permanente dans l’appliance Skyline Collector ni partagée avec des tiers.
¶ Skyline Health pour vSphere
Skyline Health fournit des résultats d’analyse pour votre environnement vSphere, en utilisant à la fois des vérifications internes horaires (in-house healthchecks) et des vérifications en ligne (online healthchecks).
- Les résultats sont basés sur les données de télémétrie collectées à partir de votre environnement vSphere.
- Les données sont analysées puis fournies dans le client vSphere.
- Les problèmes détectés peuvent être liés à la stabilité ou à des mauvaises configurations dans vSphere.
Dans les environnements vSphere 6.7 et ultérieurs, vous pouvez utiliser les services vSphere Health et vSAN Health pour surveiller la cohérence de configuration, vérifier la conformité aux meilleures pratiques, identifier les vulnérabilités et effectuer des analyses proactives.
Les services vSphere Health et vSAN Health font partie de VMware Skyline Health.
Vous accédez à Skyline Health à l’aide du client vSphere.
Pour que Skyline Health pour vCenter fonctionne correctement :
- Vous devez participer au programme d’amélioration de l’expérience client (CEIP).
- Votre instance vCenter doit disposer d’une connectivité Internet.
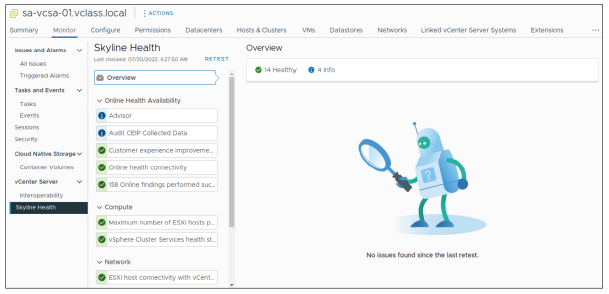
Pour afficher les informations relatives à la santé de vSphere, cliquez sur l’onglet Monitor d’une instance vCenter, puis sélectionnez Skyline Health.
Pour afficher les informations relatives à la santé de vSAN, cliquez sur l’onglet Monitor d’un cluster vSAN ou d’un hôte ESXi activé pour vSAN, puis sélectionnez Skyline Health.
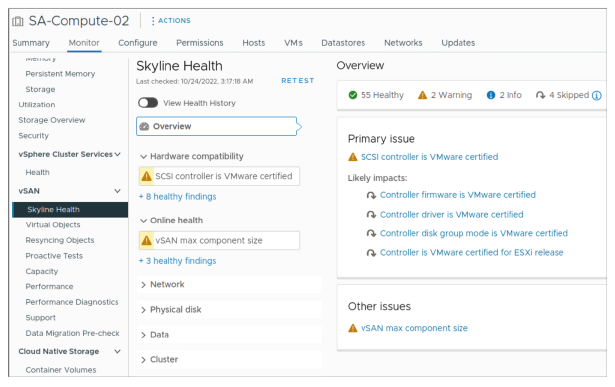
¶ Skyline Health pour vSAN
Pour les vérifications de santé en ligne de vSAN, les résultats de Skyline Health présentent les caractéristiques suivantes :
- Les résultats sont basés sur les données de milliers de déploiements vSAN.
- Les résultats s’appuient sur les articles de la base de connaissances VMware et sur les meilleures pratiques.
- Les problèmes détectés peuvent être liés à des erreurs de configuration ainsi qu’à la santé générale et au bon fonctionnement des hôtes d’un cluster vSAN.
vSAN Health inclut des vérifications de santé intégrées au produit qui ne nécessitent pas de participation au programme CEIP. Elles ne requièrent pas non plus de connectivité Internet.
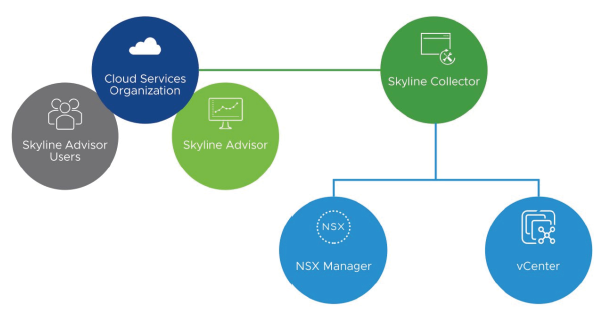
¶ Composants Skyline : Collector et Advisor
Skyline Advisor Pro et Skyline Collector travaillent ensemble pour fournir une assistance proactive :
-
Skyline Collector est une appliance virtuelle autonome qui collecte les données de diagnostic de vos environnements vSphere, NSX for vSphere, vSAN, VMware Horizon et vRealize Operations Manager.
-
Skyline Advisor Pro est un portail web vous permettant de visualiser les analyses proactives et les recommandations à la demande.
Vous pouvez accéder directement à Skyline Advisor Pro via le lien suivant : https://skyline.vmware.com/advisor
Vous pouvez également y accéder depuis la liste des services de la console de votre organisation Cloud Services.
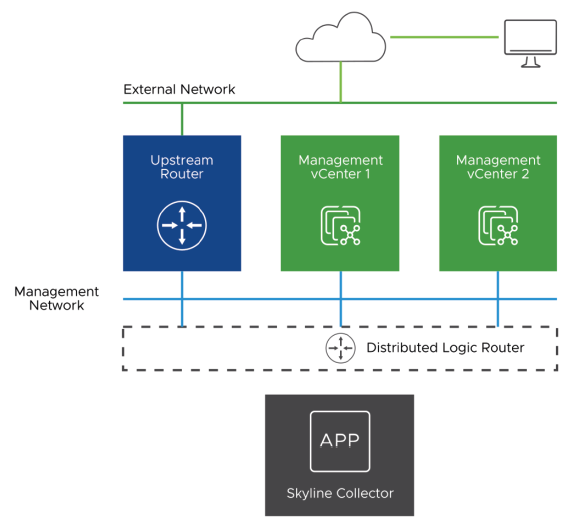
¶ Conception Réseau de VMware Skyline
Ce modèle de conception réseau présente les caractéristiques suivantes :
- L’instance Skyline Collector dispose d’un accès routé au réseau de gestion.
- Un routeur en amont fournit la connectivité externe.
- Un serveur proxy HTTP peut être utilisé pour la connectivité sortante.
¶ Fonctionnement de VMware Skyline
-
Installation et configuration :
- Vous installez l’appliance Skyline Collector dans votre environnement.
- Vous configurez Skyline Collector avec un ou plusieurs points de terminaison (pour vCenter, NSX Manager, Horizon View, vRealize Operations).
-
Collecte :
- Skyline Collector commence à collecter les données d’utilisation des produits et à capturer les modèles, événements, tendances, configurations, conformité de conception et informations inter-produits.
-
Analyse :
- VMware Skyline analyse les détails de l’environnement et l’utilisation des produits, puis compare ces données aux bonnes pratiques VMware et à la base de connaissances VMware.
-
Action :
- VMware Skyline fournit des analyses proactives et des recommandations via Skyline Advisor Pro, un portail web.
Skyline Collector est une appliance légère dont l’installation prend environ 15 à 30 minutes.
L’installation consiste à ajouter Skyline Collector à une nouvelle ou existante organisation Cloud Services, associer votre droit de support à l’organisation, télécharger l’appliance Skyline Collector depuis My VMware, déployer l’appliance à l’aide du vSphere Client à partir d’un modèle OVF.
Pour des instructions complètes sur l’installation et la configuration de Skyline Collector, consultez le guide utilisateur VMware Skyline Collector à l’adresse suivante : https://docs.vmware.com/en/VMware-Skyline-Collector/3.2/user-guide.pdf
Skyline Collector collecte et agrège des informations sur l’utilisation des produits telles que la configuration, les fonctionnalités et les performances, tout en surveillant les changements et événements dans l’environnement du client.
Ces informations sont chiffrées, puis envoyées à VMware pour analyse.
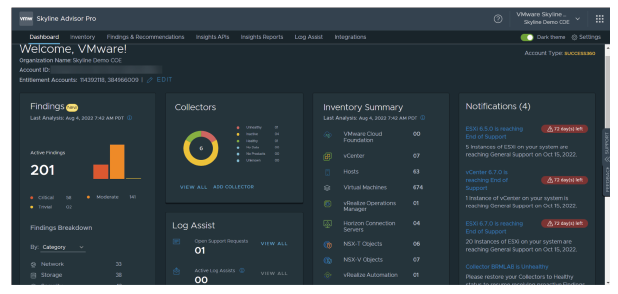
¶ Skyline Advisor Pro
Skyline Advisor Pro est une application web en libre-service qui vous permet de visualiser des analyses proactives et des recommandations à la demande, directement depuis un navigateur web.
Pour activer Skyline Advisor Pro, mettez à niveau vers Skyline Collector 3.0.
Les informations suivantes sont disponibles dans Skyline Advisor Pro :
- Détails du compte, incluant le nombre total de vCenters, d’hôtes ESXi et de machines virtuelles analysés pour détecter d’éventuels problèmes.
- Skyline Collectors déployés.
- Détails d’inventaire pour VMware vSphere, NSX-V, Horizon 7 et vRealize Operations Manager.
- Téléchargement des rapports récapitulatifs opérationnels (OSR — Operational Summary Reports) planifiés ou personnalisés (réservé aux clients bénéficiant du support Premier).
- Fonctionnalité simplifiée de téléchargement des journaux de support via Skyline Log Assist.
¶ Skyline Advisor Pro : Résultats Proactifs
Les résultats proactifs sont au cœur de VMware Skyline.
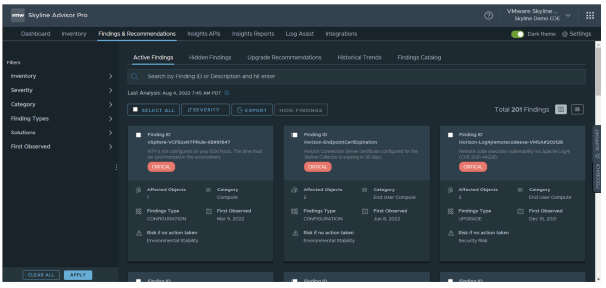
Dans l’onglet Findings & Recommendations, vous pouvez trouver tous les problèmes potentiels présents dans votre environnement. Ces problèmes doivent être corrigés afin de maintenir un environnement sécurisé, stable et productif.
Les résultats sont classés par niveau de gravité, et vous pouvez appliquer différents filtres pour affiner l’affichage selon plusieurs critères.
¶ Log Assist
Lorsque vous utilisez VMware Skyline Log Assist, vous n’avez pas besoin de télécharger manuellement vos fichiers journaux.
Les paquets de journaux de support peuvent être automatiquement transférés vers le support technique VMware.
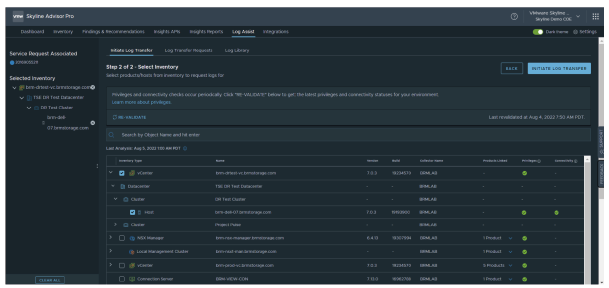
Log Assist permet de réduire le temps de résolution dès l’ouverture d’une demande de support.
Les ingénieurs du support technique VMware peuvent demander les paquets de journaux associés à votre demande de support.
Lorsque vous approuvez leur demande, les fichiers journaux sont automatiquement transférés à l’équipe de support technique, qui peut alors commencer immédiatement le diagnostic.
Vous pouvez également utiliser Log Assist pour initier vous-même le transfert automatique.
Log Assist élimine le processus long et fastidieux de transfert manuel des fichiers journaux via le protocole SSH File Transfer Protocol (SFTP) ou VMware Customer Connect.
¶ Comparaison des fonctionnalités Skyline selon le niveau de support
| Fonctionnalités | Support de base | Support de production | Support Premium |
|---|---|---|---|
| Skyline Health | ✓ | ✓ | ✓ |
| Constatations et recommandations de base | ✓ | ✓ | ✓ |
| Communauté Skyline modérée | ✓ | ✓ | ✓ |
| Skyline Advisor Pro | ✓ | ✓ | |
| Log Assist | ✓ | ✓ | |
| Support proactif pour tous les produits pris en charge | ✓ | ✓ | |
| Exportation des constatations, recommandations et objets affectés vers un fichier CSV | ✓ | ✓ | |
| Constatations et recommandations avancées | ✓ | ||
| Rapports opérationnels personnalisés | ✓ | ||
| Assistance guidée par VMware Global Support Services | ✓ |
¶ Plug-in intégré Skyline Health Diagnostics
Introduit dans vSphere 8 Update 1, le client vSphere peut être utilisé pour déployer facilement l’appliance Skyline Health Diagnostics et l’enregistrer auprès du vCenter.
¶ Avantages de l’utilisation de VMware Skyline Health Diagnostics
Skyline Health Diagnostics offre de nombreux avantages :
- En se basant sur les symptômes, l’outil fournit un article de la base de connaissances (Knowledge Base) ou des étapes de remédiation pour résoudre le problème.
- Le mode en libre-service améliore le délai d’obtention des recommandations pour résoudre les problèmes.
- Des recommandations et remédiations rapides permettent de restaurer l’infrastructure après une panne et d’assurer la continuité des activités avec un minimum de perturbations.
¶ Architecture de VMware Skyline Health Diagnostics
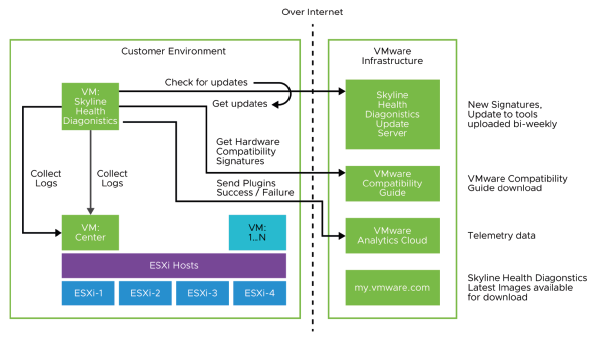
L’outil VMware Skyline Health Diagnostics est déployé sous forme d’appliance virtuelle.
Lorsque vous rencontrez un problème avec des produits VMware, vous pouvez collecter le bundle de journaux (log bundle) et exécuter l’analyse à l’aide de la plateforme Diagnostics.
La plateforme Diagnostics contient de nombreuses signatures pour détecter les problèmes.
Lorsqu’une signature correspond aux informations contenues dans les fichiers journaux, vous êtes notifié.
Référence : VMware Docs, VMware Skyline Health Diagnostics for vSphere Documentation – https://docs.vmware.com/en/VMware-Skyline-Health-Diagnostics/index.html
¶ Revue des objectifs d’apprentissage
- Décrire les avantages et les capacités de VMware Skyline
- Expliquer le fonctionnement de VMware Skyline
- Identifier les types d’informations de santé fournis par Skyline Health
- Reconnaître les cas d’utilisation de Skyline Advisor Pro
¶ Points clés
- La clé pour interpréter les données de performance consiste à observer l’ensemble des données depuis la perspective du système d’exploitation invité, de la machine virtuelle et de l’hôte.
- Vous utilisez des alarmes pour surveiller les objets d’inventaire du vCenter et envoyer des notifications lorsque certains événements ou conditions se produisent.
- VMware Skyline est une technologie de support proactive qui fournit des analyses prédictives et des recommandations afin de vous aider à éviter les problèmes.
Chapitre précédent : 6 - Opérations vCenter et ESXi - Chapitre suivant : 8 - Sécurité et contrôle d'accès vSphere