¶ Introduction
Dans cette documentation nous allons voir ensemble comment mettre en place une infrastructure de haute disponibilité basée sur un cluster Proxmox VE composé de deux nœuds utilisant un stockage local ZFS avec réplication entre les serveurs ainsi qu'un QDevice pour le Quorum.
Cette configuration nous permettra d'avoir une infrastructure résiliente tout en conservant la simplicité d’administration propre à Proxmox.
L'environnement Proxmox que j'utilise pour faire cette documentation est un environneent virtuel.
C'est à dire que les serveurs Proxmox que je vais utiliser sont des VMs cependant la procédure reste identique avec du matériel physique.
¶ Objectifs
L'objectif de cette documentation est de montrer les différentes étapes de la préparation des serveurs jusqu’à la mise en place de la réplication des machines virtuelles.
Nous verrons donc ensemble :
- Comment préparer correctement les deux serveurs Proxmox.
- Comment créer et optimiser un pool ZFS.
- Comment créer un cluster Proxmox à deux nœuds.
- Comment déployer et configurer un QDevice (QNetd) afin de maintenir le quorum en cas de panne.
- Comment mettre en place une réplication ZFS entre les deux nœuds.
- Comment vérifier le bon fonctionnement du cluster et de la réplication.
L'idée est d’obtenir une continuité de service, une réplication automatique des machines virtuelles et une capacité de bascule maîtrisée.
¶ Prérequis
- Deux serveurs Proxmox (physiques ou VMs)
- Même version de Proxmox VE sur les deux nœuds
- Avoir accès à l'interface graphique et au SSH de Proxmox.
- Une connectivité réseau stable entre les deux nœuds
- De préférence une latence faible (idéalement < 5 ms surtout pour de la prod)
- Débit recommandé : 1 Gbps minimum (10 Gbps idéal)
- Nom d’hôte correctement défini
- Résolution DNS ou /etc/hosts fonctionnelle (important)
- Avoir une machine Linux dédiée à l'installation du qdevice. Dans mon cas ce sera une Debian 13.
- Avoir accès en SSH à la machine du qdevice.
- Un compte ayant suffisament de droits pour effectuer les manipulations.
ATTENTION : Je ne montrerai pas comment faire l'installation des serveurs Proxmox. Je pars du principe que les deux serveurs sont déjà installés.
¶ Configuration du réseau
¶ Architecture réseau recommandée
Idéalement il faut à minima deux interfaces réseau sur les serveurs Proxmox :
- 1 interface pour le management
- 1 interface dédiée au cluster (Corosync)
Exemple :
| Usage | Interface | IP |
|---|---|---|
| Management | vmbr0 | 192.168.60.x |
| Cluster | vmbr1 | 192.168.70.x |
¶ Configuration des interfaces
Voici un exemple de la configuration réseau nécessaire pour créer le Cluster.
On y retrouvera nos deux cartes réseau ainsi que les subnets dédiés à chacune d'elles.
Cette configuration est à mettre dans /etc/network/interfaces et sera a faire sur les deux serveurs en prennant évidemment soin de ne pas utiliser les mêmes adresses sur les deux nœuds.
auto lo
iface lo inet loopback
iface ens192 inet manual
iface ens224 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.60.1/24
gateway 192.168.60.254
bridge-ports ens192
bridge-stp off
bridge-fd 0
auto vmbr1
iface vmbr1 inet static
address 192.168.70.1/24
bridge-ports ens224
bridge-stp off
bridge-fd 0
¶ Vérification des serveurs
Avant de commencer la configuration nous allons procéder à quelques vérifications sur nos deux serveurs Proxmox.
Il est impératif que les serveurs soient correctement configurés et qu'ils puissent communiquer ensemble sur le réseau.
Personnellement je vais le faire en SSH sur les serveurs mais il est tout à fait possible de le faire depuis le shell de l'interface graphique.
¶ Configuration des hostname
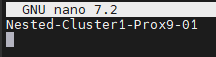
- Vérifier que le nom du serveur soit correctement configuré dans le fichier /etc/hostname.
Si ce n'est pas le cas modifier le fichier.
nano /etc/hostname

- Exemple de contenu
¶ Configuration du fichier hosts
- Vérifier que le fichier hosts soit correctement configuré.
Si ce n'est pas le cas modifier le fichier.
nano /etc/hosts

- Exemple de contenu

¶ Vérification réseau
Je vais utiliser deux réseaux pour avoir deux liens pour corosync.
Je vais donc vérifier que les deux serveurs puissent comminiquer sur ces deux réseaux.
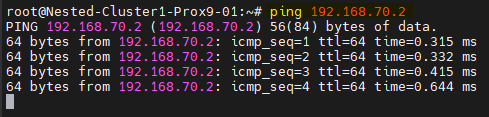
- Sur le premier serveur :
# Fichier hosts
ping Nested-Cluster1-Prox9-02

# Second réseau pour corosync
ping 192.168.70.2
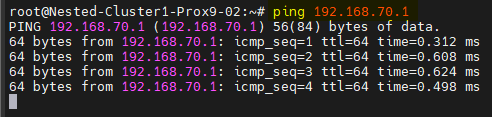
- Sur le second serveur :
# Fichier hosts
ping Nested-Cluster1-Prox9-01

# Second réseau pour corosync
ping 192.168.70.1
ATTENTION : Le cluster Corosync dépend fortement de la résolution DNS/hosts et de la stabilité du réseau.
¶ Mise à jour des systèmes
- Nous allons effectuer les mises à jour sur chacun des serveurs.
apt update && apt full-upgrade
- Faire un reboot des serveurs après les mises à jour
reboot
¶ Création du stockage ZFS
Il existe de nombreuses options et de nombreux types de pool de stockage ZFS.
Je ne les expliquerai pas ici cependant si cela vous intéresse, vous trouverez des informations dans la documentation Configurer un pool ZFS dans Proxmox
Pour les besoins de cette documentation j'ai ajouté sur chacun des deux nœuds 3 disques de 40Go et je vais mettre en place un pool ZFS de type "RAIDZ".
¶ En mode graphique
- Depuis l'interface graphique cliquer sur le serveur PVE puis sur "Disk" et sélectionner "ZFS"
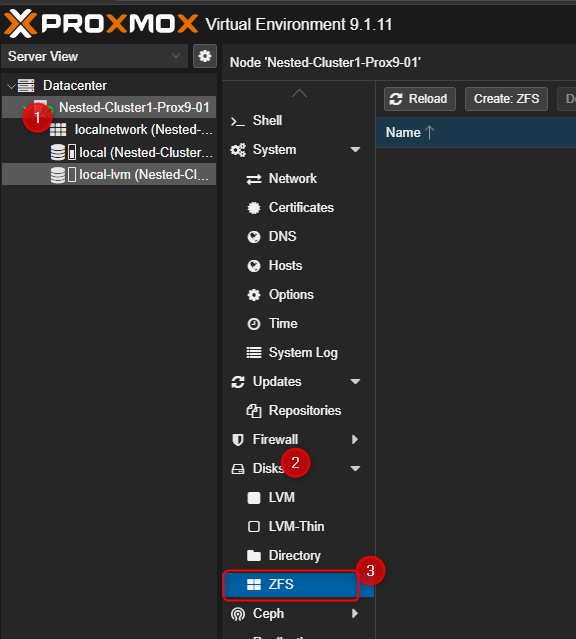
- Dans la partie de droite cliquer sur "Create ZFS"
- Sélectionner le type de RAID souhaité. Pour mon exemple, je vais sélectionner RAIDZ.
Entrer un nom pour le volume, sélectionner RAIDZ et sélectionner l'ensemble des disques qui seront utilisés pour la création du volume.
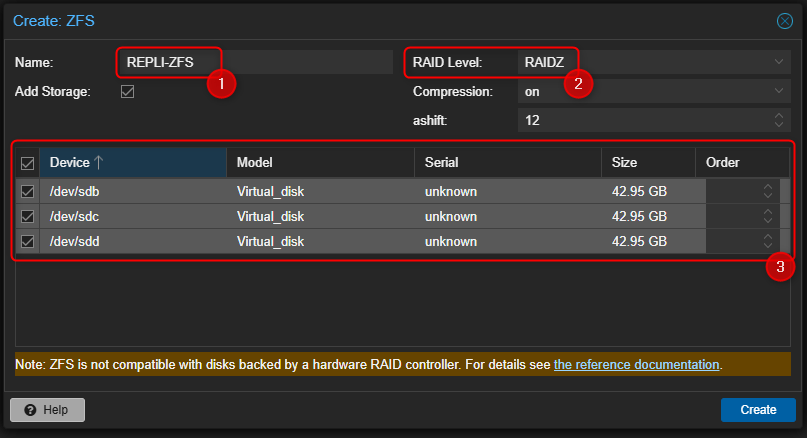
- Valider en cliquant sur "CREATE".
- Patienter pendant la création du volume.
- Après sa création le volume sera visible dans la liste des RAID ZFS.

- Il sera également disponible dans l'inventaire à gauche.
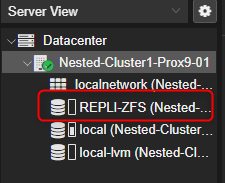
- Depuis l'inventaire, à gauche, cliquer sur le volume pour afficher ses détails dans la partie de droite de l'interface graphique.
On peut constater qu'il possède une capacité de stockage de 82Go du fait qu'un des 3 disques de 40Go est utilisé pour la parité. Permettant ainsi la tolérence de pannes.

¶ en ligne de commande (CLI)
¶ Création du Pool ZFS
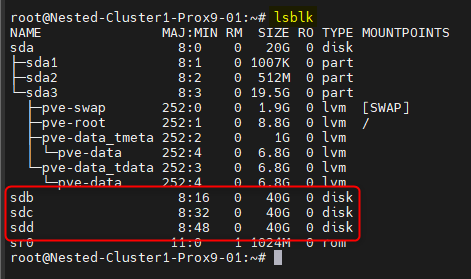
- Identifier les disques qui seront utilisés à l'aide de la commande
lsblk
lsblk
- Création du pool ZFS à l'aide de la commande suivante :
zpool create -f REPLI-ZFS raidz /dev/sdb /dev/sdc /dev/sdd

| Éléments | Descriptions |
|---|---|
zpool create |
Création d’un pool ZFS |
-f |
Force la création |
REPLI-ZFS |
Nom du pool |
raidz |
Type de RAID ZFS (un disque de parité) |
/dev/sdb /dev/sdc /dev/sdd |
Disques à utiliser |
- Vérification du pool
zpool status
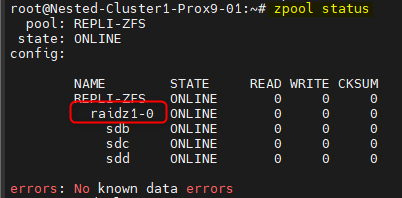
La ligne "raidz1-0" indique que le pool ZFS est correctement créé en "RAIDZ" et donc avec un disque de parité.
¶ Optimisations ZFS
- Activer la compression à l'aide de la commande suivante :
zfs set compression=lz4 REPLI-ZFS

- Désactivation de l’atime à l'aide de la commande suivante :
zfs set atime=off REPLI-ZFS

| Options | Bénéfices |
|---|---|
compression=lz4 |
Compression rapide et efficace |
atime=off |
Réduction des écritures disque |
¶ Ajout du stockage dans Proxmox
Attention, la création d'un pool ZFS avec la commande zpool create ne signifit pas pour autant qu’il sera visible automatiquement dans l’interface web du serveur PVE.
- Ajouter le pool ZFS dans le serveur PVE avec la commande suivante
pvesm add zfspool REPLI-ZFS --pool REPLI-ZFS

Le pool sera ainsi visible et disponible dans l'inventaire à gauche.
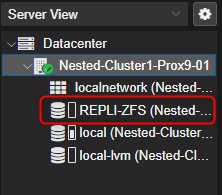
- A nouveau nous pouvons vérifier les détails du pool.
Depuis l'inventaire, à gauche, cliquer sur le volume pour afficher ses détails dans la partie de droite de l'interface graphique. Il fait également 82Go avec un disque utilisé pour la parité, permettant ainsi la tolérence de pannes.

¶ Création du cluster Proxmox
¶ En mode graphique
¶ Sur le premier serveur Proxmox.
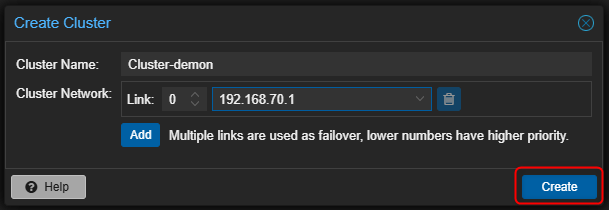
- Cliquer sur Dataceter puis cliquer sur Cluster.
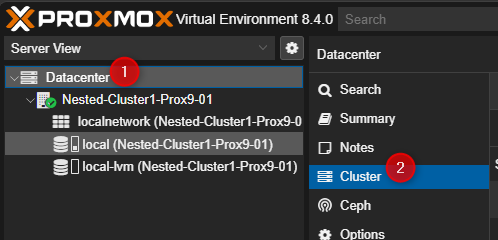
- Dans la partie de droite cliquer sur "Create Cluster".
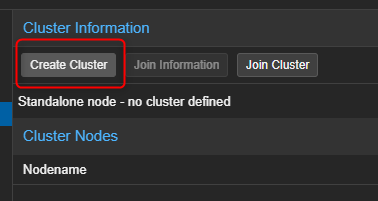
- Entrer un nom pour le Cluster et sélectionner l'interface qui sera utilisée pour les communications du Cluster.
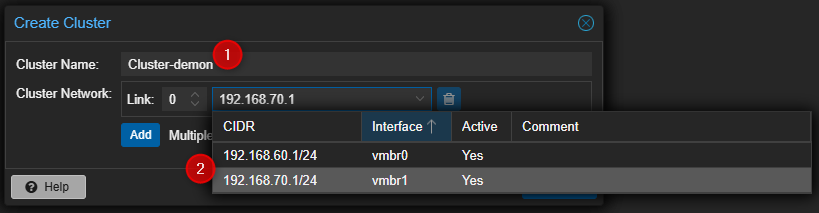
- Cliquer sur "Create" pour valider la création.
-
Attendre la fin de la tâche de création.
-
Le Cluster sera visible dans la partie de droite.
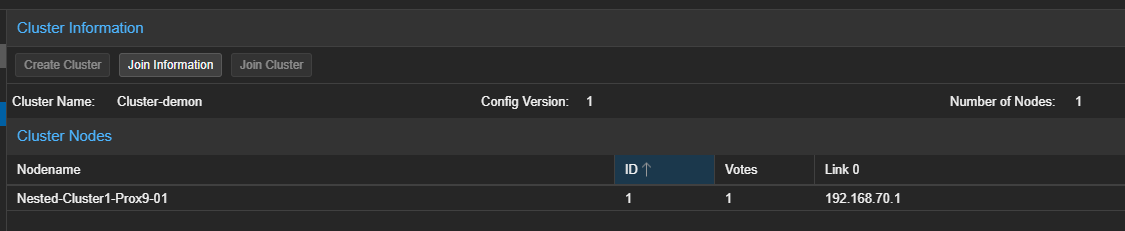
- Récupérer les informations permettant de joindre le Cluster.
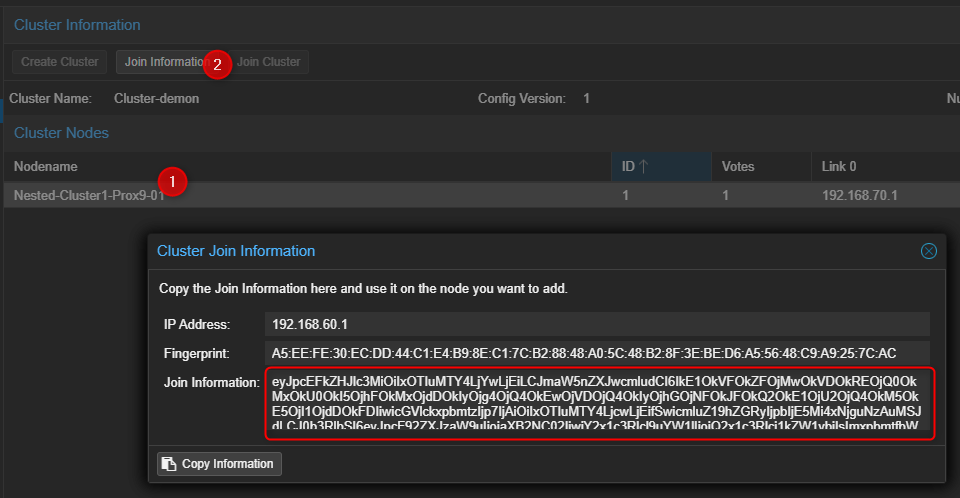
¶ Sur le second serveur Proxmox.
- Cliquer sur Dataceter puis sur Cluster et pour terminer sur "Join Cluster" dans la partie de droite.
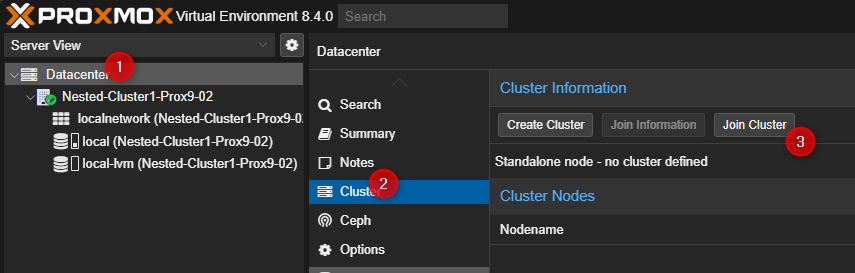
- Entrer les liens d'accès au cluster, le password du compte root du premier serveur PVE, sélectionner l'interface qui sera utilisée pour le cluster puis cliquer sur "Join" en bas à droite.
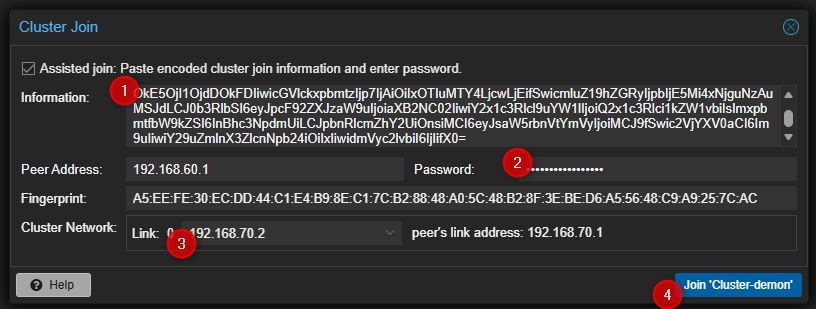
- Attendre la fin de la tâche puis vérifier que le serveur a bien été join au Cluster.
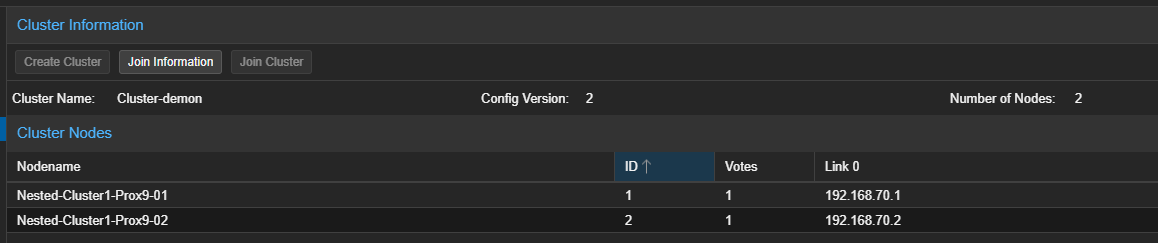
¶ En CLI
¶ Configuration
Pour créer le Cluster en utiliant les lignes de commande (CLI) il faudra effectuer les manipulations suivantes :
# Sur le premier serveur Proxmox
pvecm create Cluster-Name
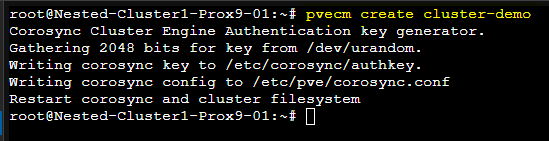
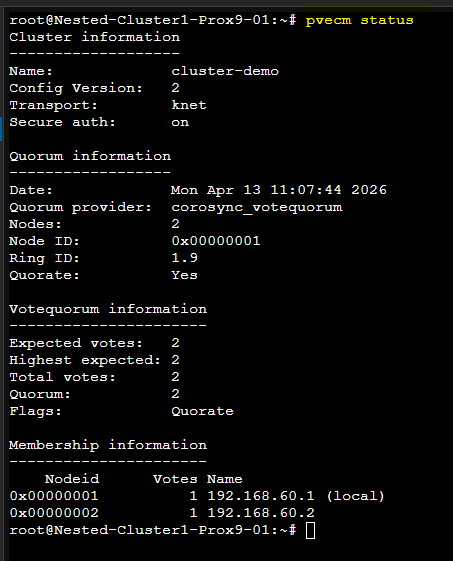
Une fois la commande passée on peut vérifier que le Cluster est correctement créé à l'aide de la commande suivante : pvecm status
Le résultat sera comme ceci :
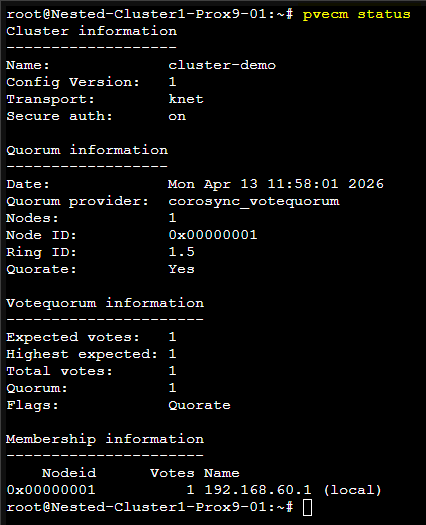
Une fois le Cluster créé il faudra en suite ajouter le second serveur Proxmox
# Sur le second serveur Proxmox
pvecm add 192.168.60.1 # adresse IP du premier serveur PVE
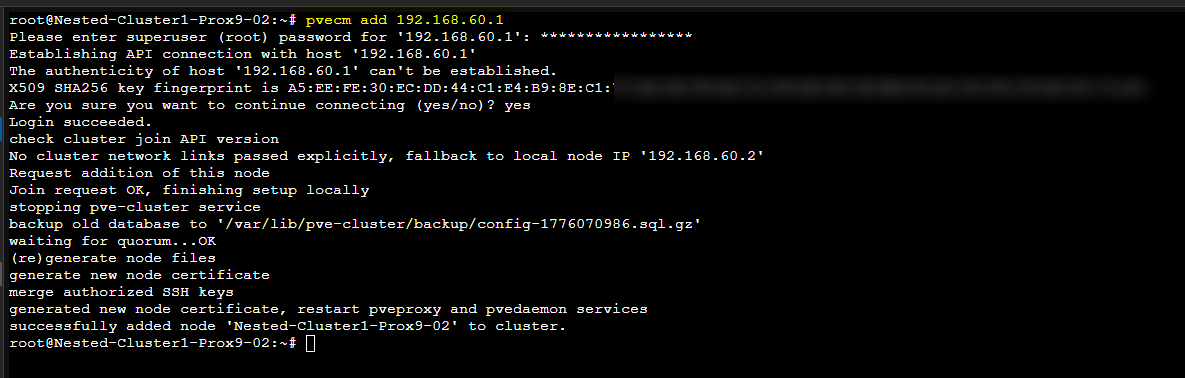
Après avoir ajouté le second serveur Proxmox au Cluster, les deux serveur seront visibles depuis leur interface graphique.
Il sera également possible de vérifier le Cluster avec les commandes suivantes :
pvecm nodes
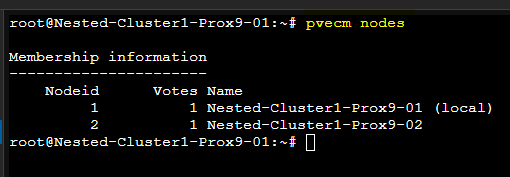
pvecm status
¶ Modification du lien Corosync
Nous venons créer un Cluster et d'ajouter le second nœud cependant le réseau utilisé ne correspond pas à celui que nous avons configuré et qui sera dédié à Corosync.
Pour utiliser le réseau dédié nous allons devoir faire quelques modifications.
- Editer le fichier
/etc/pve/corosync.conf
Dans la partie "nodelist", modifier l'adresse ip par celle du réseau dédié
AVANT
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.60.1
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.60.2
}
}
APRES
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.70.1 # <== ICI
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.70.2 # <== ICI
}
}
ATTENTION : Pour que la modification soit prise en compte il faudra redémarrer le service corosync sur chacun des nœuds :
systemctl restart corosync
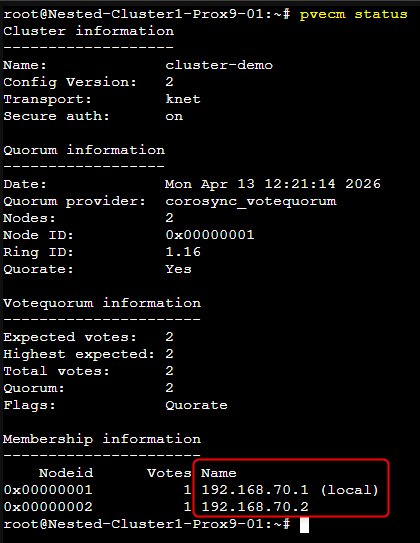
¶ Vérifications
Nous pouvons vérifier que la modification a bien été prise en compte en utilisant à nouveau la commande pvecm status
¶ Installation du QDevice
¶ Installation sur la machine Linux
- Se connecter en SSH sur la machine Linux externe qui sera utilisée comme Qdevice.
Taper la commande suivante :
apt install corosync-qnetd
- Valider la demande d'installation en tapant "o" (ou "y" si l'OS est en anglais) lorsque ce sera demandé.
- Activer et démarrer le service.
systemctl enable corosync-qnetd && systemctl start corosync-qnetd

- Vérifier l'état du service "corosync-qnetd"
systemctl status corosync-qnetd
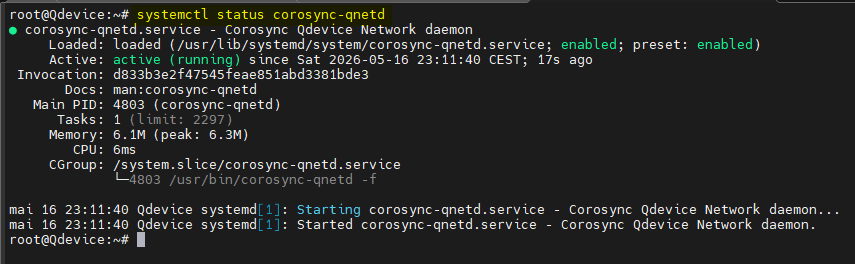
Le service doit être à l'état "active (running)".
Si ce n'est pas le cas vous avez un problème qu'il faudra corriger.
- Vérifier que le service est bien en écoute.
Par défaut le service écoute sur le port 5403/TCP.
ss -tulnp | grep 5403

¶ Installation sur le cluster PVE
Nous allons devoir faire les manipulations suivantes sur les deux serveurs PVE qui composent actuellement le Cluster.
- Installation du service "corosync-qnetd"
apt install corosync-qdevice
Valider la confirmation des packages en tapant soit "o" soit "y" selon la langue de l'OS.
¶ Configuration du QDevice dans le cluster PVE
¶ Ajout automatique via "pvecm"
- Depuis le premier serveur Proxmox du Cluster taper la commande suivante :
pvecm qdevice setup <IP_QDEVICE>

- Valider par "yes" puis entrer le password root du Qdevice
Cette commande effectue plusieurs actions importantes :
- Génère des certificats dans /etc/corosync/
- Configure automatiquement Corosync
- Ajoute la section QDevice dans /etc/pve/corosync.conf
- Synchronise la configuration sur tous les nœuds
¶ Vérification du fichier "corosync.conf"
Nous allons à présent vérifier le fichier "corosync.conf" et s'assurer que tout est en order.
Ouvrir le fichier "corosync.conf"
cat /etc/pve/corosync.conf
Après l'ajout du service dans le cluster Proxmox le fichier devrait comporter ces lignes :
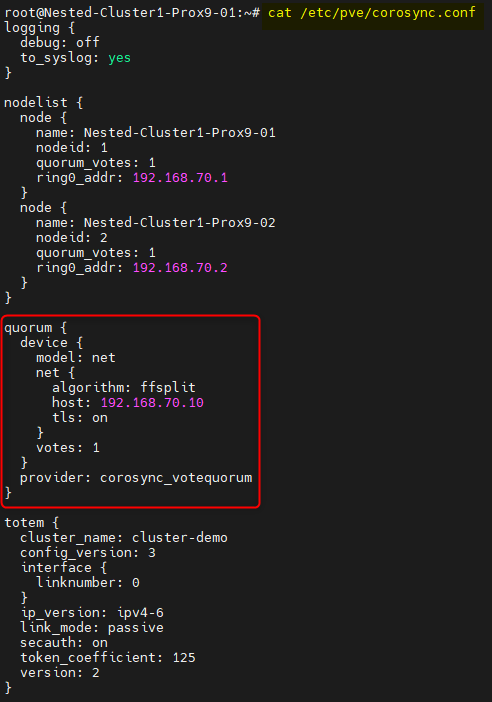
Pour information : Cette section indique que le cluster utilise un vote externe.
¶ Vérification globale du cluster
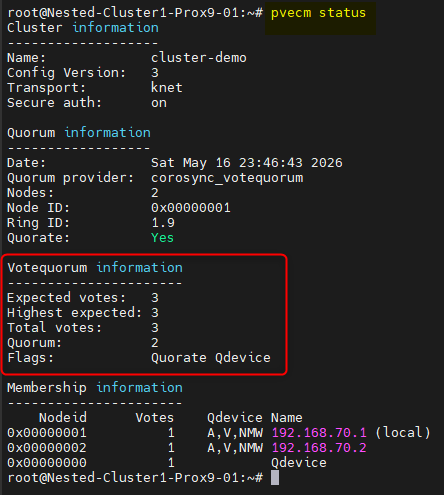
Pour vérifier la configuration globale du Cluster il faudra taper cette commande :
pvecm status
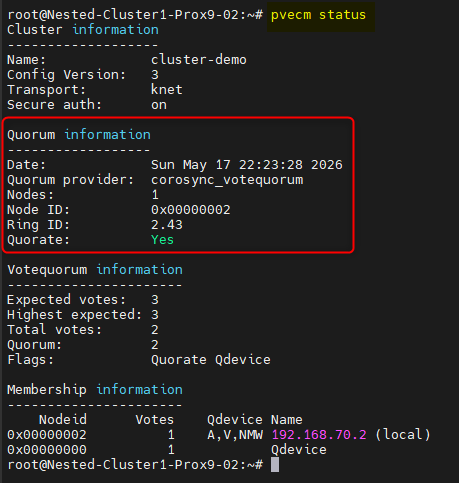
Nous devrions avoir ce résultat :
- Expected votes: 3
- Highest expected : 3
- Total votes: 3
- Quorum: 2
- Flags : Quorate Qdevice
¶ Vérification des certificats
Les certificats sont stockés dans :
/etc/corosync/qdevice/net/

Ils permettent l’authentification entre les nœuds et le QDevice.
¶ Tests de fonctionnement du quorum
¶ Simulation de panne
Pour simuler une panne je vais éteindre le premier serveur Proxmox du Cluster.
shutdown now
Puis, depuis le second serveur Proxmox, je vais vérifier l'état du Cluster.
pvecm status
Si tout c'est correctement passé le quorum doit être maintenu grâce au QDevice.
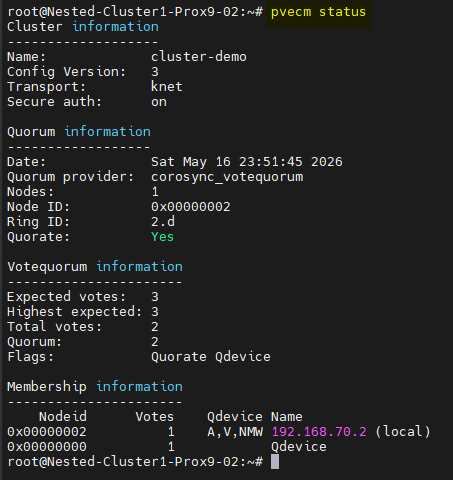
Rallumer le premier serveur Proxmox.
¶ Test de perte réseau
Pour tester le réseau et vérifier que tout fonctionne correctement en cas de panne nous allons simuler une coupure réseau vers un nœud.
Depuis le premier serveur Proxmox taper la commande suivante :
ip link set vmbr1 down
Si tout se passe correctement, le Cluster fonctionne toujours.
¶ Activation et configuration du HA
¶ Services HA
- Sur chaque nœud, activer les services suivants :
systemctl enable pve-ha-lrm
systemctl enable pve-ha-crm
systemctl start pve-ha-lrm
systemctl start pve-ha-crm
¶ Vérification
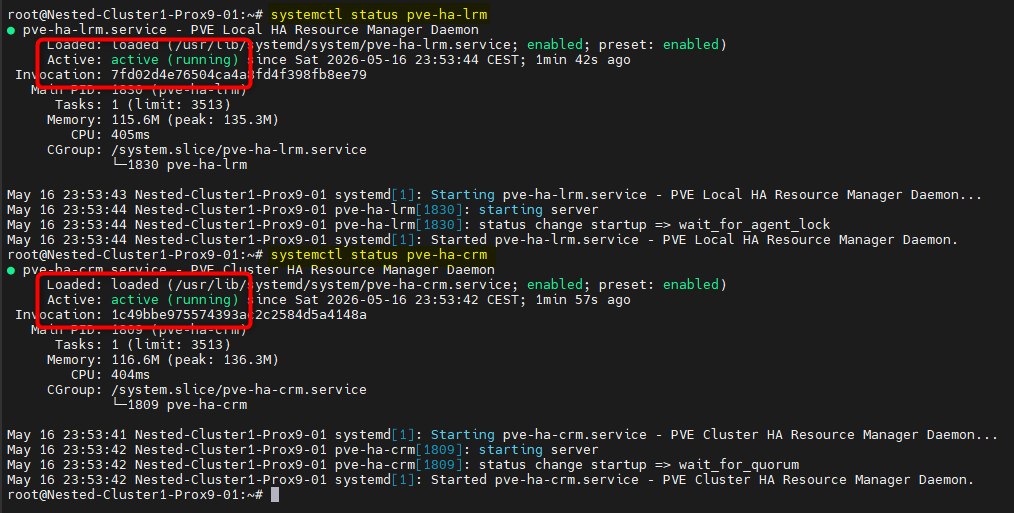
- Sur chaque nœud, vérifier le status des services :
systemctl status pve-ha-lrm
systemctl status pve-ha-crm
Les services doivent être actifs.
¶ Fichiers de configuration HA
Tous les fichiers du HA sont dans le répertoire /etc/pve/ha/
- Fichier resources.cfg :
/etc/pve/ha/resources.cfg
Ce fichier définit :- Les VM gérées en HA
- Leur comportement
- Fichier manager_status :
/etc/pve/ha/manager_status
Ce fichier contient l’état interne du cluster HA (Il ne pas modifier manuellement)
¶ Configuration du HA sur une VM
- Ajout du HA sur une VM
ha-manager add vm:100

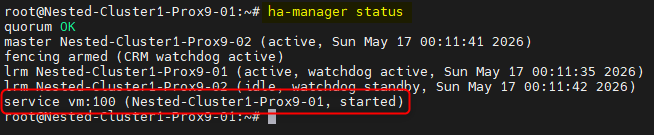
- Vérification du HA sur une VM
ha-manager status
- Modification des paramètres
ha-manager set vm:100 --max_restart 5 --max_relocate 2

¶ Fonctionnement interne du HA
-
CRM (Cluster Resource Manager)
- Lit /etc/pve/ha/resources.cfg
- Décide où démarrer les VM
-
LRM (Local Resource Manager)
- Exécute les actions localement
- Démarre/arrête les VM
Ces composants communiquent via Corosync.
¶ Vérifications avancées
- Logs Corosync
journalctl -u corosync
- Logs HA
journalctl -u pve-ha-lrm
journalctl -u pve-ha-crm
- État QDevice
corosync-qdevice-tool -s
¶ Réplication ZFS
La réplication dans Proxmox utilise "snapshots ZFS", "zfs send" et "zfs receive".
Elle est "incrémentale", automatisée et très efficace.
ATTENTION : Dans Proxmox VE, la réplication ZFS fonctionne par VM (ou CT).
Il sera donc nécessaire de faire un job de réplicaton par VM ou par CT.
Si vous avez 10 VMs il faudra donc créer 10 jobs de réplication.
¶ En mode graphique
- Cliquer sur "Datacenter" puis sur "Replication" et en fin sur "Add" dans la partie de droite.
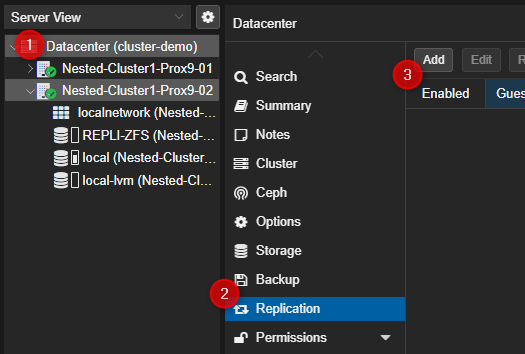
- Sélectionner les paramètres suivants :
- CT/VM ID : L'ID de la VM ou du CT qui sera répliqué.
- Target : le nœud sur lequel la réplication sera effectuée.
- Schedule : Définit quand le job de réplication doit s’exécuter.
Le reste des paramètre peut être laissé par défaut à moins que l'on souhaite brider le débit de la réplication.
Dans ce cas il faudra configurer le paramètre "Rate Limit (MB/s)"
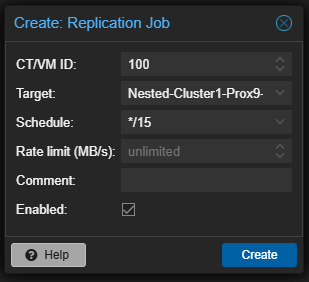
Dans cet exemple, la réplication se fera toutes les 15 minutes.
- Cliquer sur "Create" pour valider.
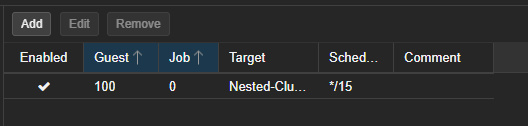
- Le job sera visible dans la liste.
¶ En CLI
- Se connecter en SSH sur le serveur qui héberge la VM ou le CT et taper la commande suivante :
pvesr create-local-job 100-0 Nested-Cluster1-Prox9-02 --schedule "*/15"
| Éléments | Descriptions |
|---|---|
| pvesr | Proxmox replication |
| create-local-job | Commande de création du job |
| 100-0 | ID du CT ou de la VM suivi d'un ID de réplication |
| Nested-Cluster1-Prox9-02 | Le nœud ciblé |
| --schedule | Fréquence |

- Vérifier la réplication avec la commande suivante :
pvesr list

- Vérifier les snapshots ZFS avec la commande suivante :
zfs list -t snapshot

¶ Test de migration
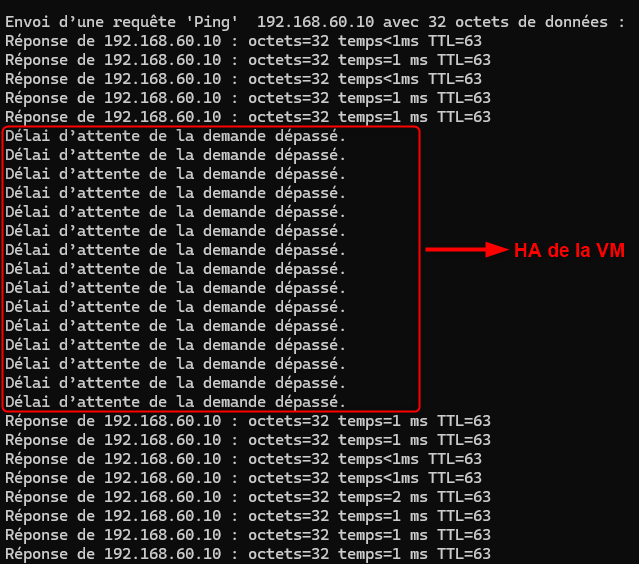
Pour vérifier que tout est fonctionnel, nous allons faire un test de migration en simulant une panne sur le premier serveur PVE. Pour rappel, c'est lui qui porte actuellement la VM de test.
- Arrêter le premier serveur PVE.
shutdown -h now

- Le quorum doit rester valide grâce au QDevice.
- HA de la VM
- Reboot automatique de la VM sur le second serveur PVE à partir de la dernière réplication disponible.