¶ Introduction
Dans cette documentation, nous allons voir ensemble comment créer un Cluster de datastores.
Nous verrons également comment activer SDRS sur ce Cluster.
Pour commencer, nous allons voir ensemble la configuration mise en place pour cette démo.
J'ai actuellement deux ESXi virtualisés (Nested) connectés à un vCenter auxquels j'ai configuré trois datastores en iSCSI.
Je ne reviendrais pas sur la manière de créer un datastore en iSCSi nous l'avons vu ensemble précédemment donc je concidère que c'est le cas aussi pour vous.
Ces datastores sont visibles dans la partie stockage de vCenter.
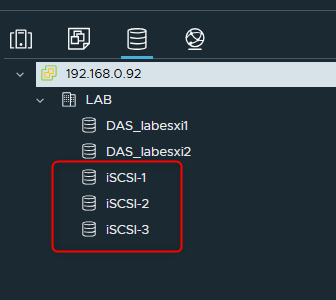
Lorsque l'on souhaite faire un Cluster de datastore il est impératif de garder en tête que les VMs qui se trouvent sur nos datastores peuvent potentiellement être amenées à migrer d'un de ces datastores vers un autre dans le Cluster.
Il faut considérer ces datastores comme étént interchangeables dans le sens où l'on peut être amené à en supprimer ou en ajouter d'autres.
Il est donc primordial que les datastores qui seriront à créer le Cluster soient strictement identiques.
Par exemple, si l'un de ces datastores est répliqué tandis que les autres ne le sont pas alors il ne conviendra pas pour faire un Cluster.
De la même manière si l'un des datastores repose sur un disque SSD très performant et qu'un autre repose sur un disque mécanique comme du Sata 7200 tr/min qui est de ce fait beaucoup plus lent que le SSD, alors là encore ce ne sera pas un bon choix pour le Cluster.
Je le répète et j'insiste, nous voulons des datastores qui fonctionnent exactement de la même manière, avec exactement les mêmes caractéristiques et performances non seulement pour optimiser les perfs mais également pour qu'ils puissent être interchangeables en cas de besoin.
Pour la démon, nous avons donc ici trois datastores totalement similaires en tout point de vue.
Ils ont la même taille, cibles des LUNs créés sur des disques stictement identiques et possèdent les mêmes performances.
Aucun d'entre eux n'est répliqué, ils sont donc d'excellents candidats pour la création de notre Cluster de datastores.
¶ Création d'un Cluster de datastores
Pour créer un Cluster de datastores, ça se passe dans la section stockage de vCenter.
Faire un clic droit sur le Datacenter puis sélectionner "Stockage" puis "Nouveau Cluster de banques de données".
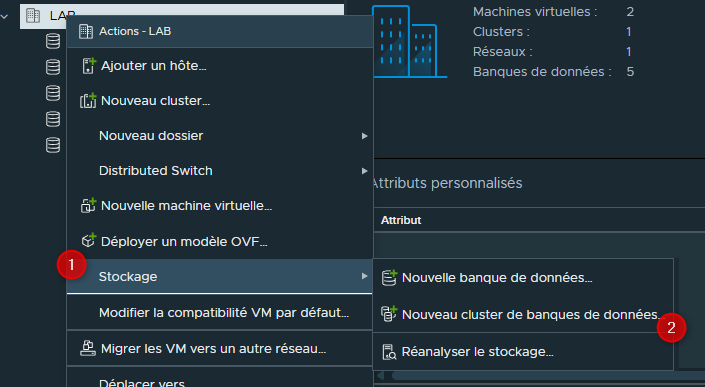
Un pop-up va apparaître nous permattant de créer et de configurer le Cluster.
Pour commencer nous allons donner un nom au Cluster.
Pour cet exemple, je vais l'appeler SDRSDemo.
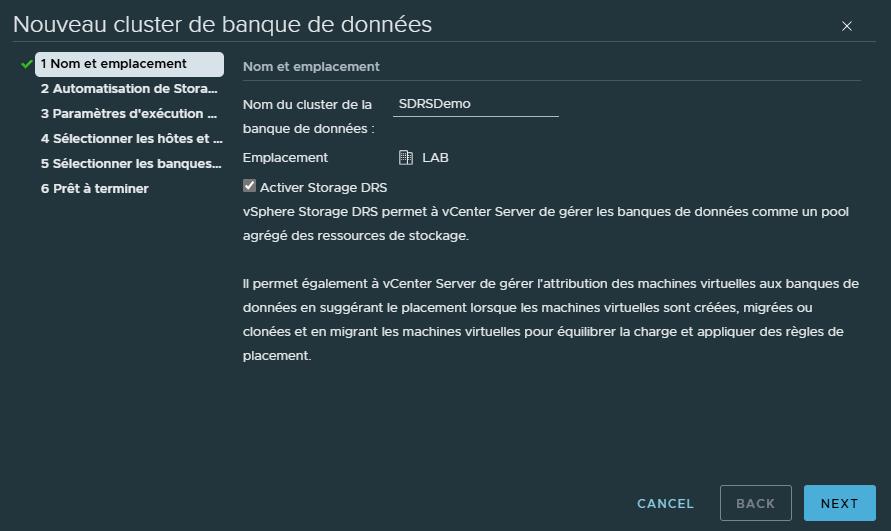
Evidemment il faut laisser la case "Activer Storage DRS" cochée par défaut.
Puis cliquer sur "Next".
Nous allons ensuite avoir plusieurs possibilités de configurations.
¶ Les différents modes
¶ Manual Mode
Commençons par voir ensemble le fonctionnement du mode manuel d'un Cluster de datastores.
Ce n'est pas le mode activé par défaut il faudra donc sélectionner tout en haut le mode manuel.
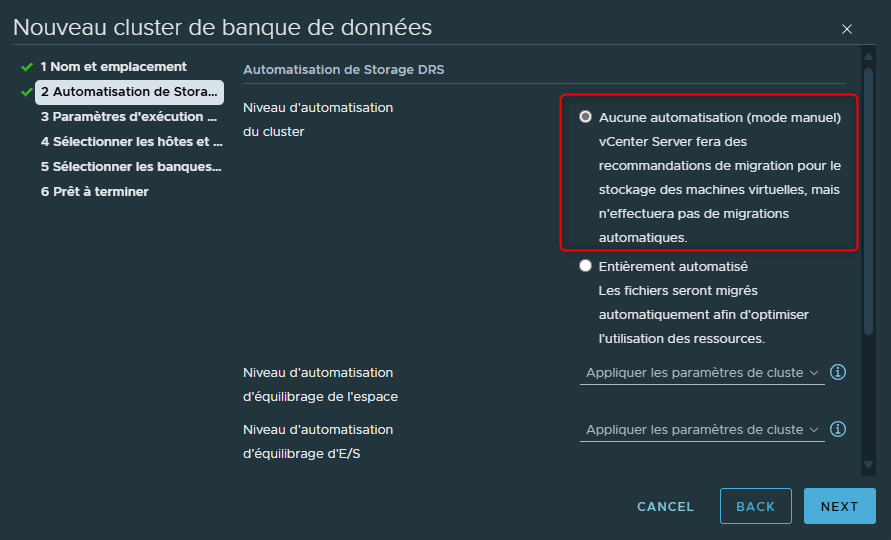
En mode manuel ce que le SDRS va faire essentiellement c'est analyser les datastores sans intervenir.
Il déterminera s'il existe un déséquilibre de consommation d'espace de stockage entre les datastores.
Autrement dit si l'espace disponible de l'un de ces datastores est nettement inférieur à celui des autres datastores du Cluster ou si un des datastore est saturé, il nous indiquera qu'il serait préférable de migrer une ou plusieurs VMs vers d'autres datastores du Cluster.
SDRS déterminera également s'il existe un déséquilibre dans les entrées-sorties (les I/O).
Ainsi si nous avons certaines VMs qui génèrent beaucoup de trafic d'entrées-sorties sur un datastore alors que le trafic sur d'autres datastores est beaucoup plus calme, SDRS nous avertira également qu'il serait bon de migrer des VMs pour équilibrer les I/O et donc améliorer les performances de nos VMs.
En mode manuel SDRS va donc rechercher les datastores qui se remplissent trop ou dont les I/O sont trop importants par rapport aux autres datastores afin de nous informer d'éventuels déséquilibres entre les datastores du Cluster et pour cela, il nous fera donc des recommandations.
SDRS nous indiquera ce que nous devons faire pour améliorer l'équilibre de l'uilisation de l'espace de stockage de nos datastores mais aussi comment améliorer les performances globales.
Dans ce mode, en aucun cas SDRS n'interviendra pour rétablir cet équilibre, il conviendra à nous de décider d'intervenir en suivant les recommandations ou de laisser les choses en l'état.
¶ Fully Automated
Voyons maintenant le mode qui est sélectionné par défaut à savoir le mode "entièrement automatisé".
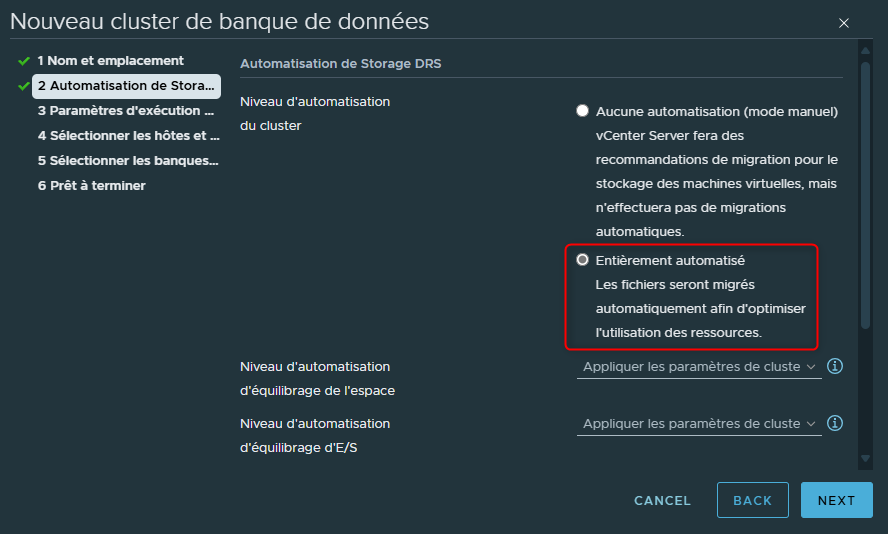
Là encore, SDRS va analyser les datastores et leurs performances à la différences que si nous laissons ce mode activé alors nous transfèrons le contrôle et la gestion au SDRS.
C'est un peu comme si on lui disait "si tu vois quelque chose à faire pour améliorer les performances alors fais le".
Il n'y aura pas de recommandations faites de la part de SDRS mais des actions effectuées à la place.
Il pourra utiliser le Storage vMotion pour déplacer et migrer des VMs comme bon lui semble.
Il en sera de même pour l'équilibrage de charge des I/O. Si SDRS détecte qu'un datastore possède un débit d'entrées-sorties trop important alors il migrera également des VMs vers d'autres datastores afin de tout rééquilibrer.
Là aussi aucune recommendation ne sera faite, SDRS agira par lui même.
¶ Outrepasser la configuration
Dans chacun des deux modes, nous allons pouvoir la possibilité d'outrepasser la configuration qui s'appliquera au niveau du Cluster pour une ou plusieurs options.
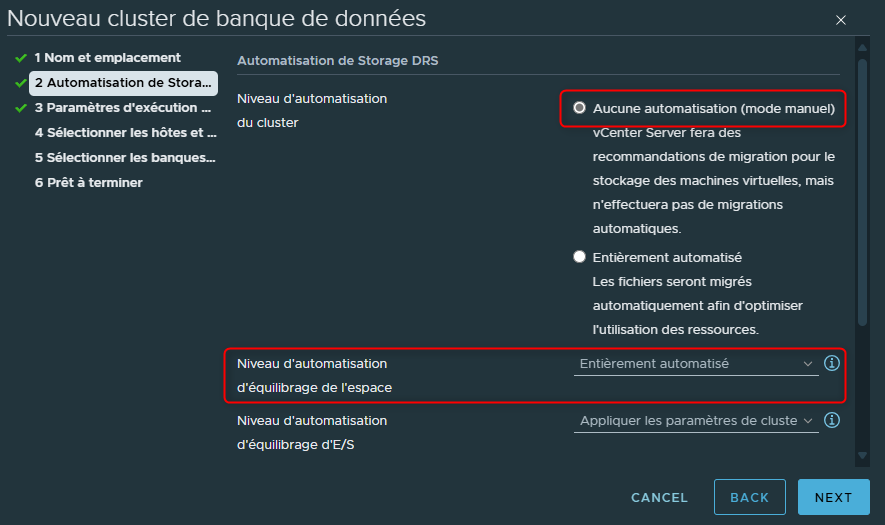
Par exemple en mode manuel nous pourrions très bien vouloir des recommendations sauf pour l'espace de stockage disponible. Peut être que nous voudrions définir pour cette action précise une automatisation complète et laisser agir SDRS ?
Dans ce cas en face de la ligne "Niveau d'automatisation d'équilibrage de l'espace" il nous suffira de sélectionner "Entièrement automatisé" lors de la configuration du cluster.
L'inverse est également vrai, nous pourrions laisser SDRS agir en activant le mode "entièrement automatisé" mais tout en refusant qu'il effectue des Storage vMotion afin de garder la main dessus.
Dans ce cas nous pourrions choisir d'outrepasser la configuration en sélectionnant "Aucune automatisation".
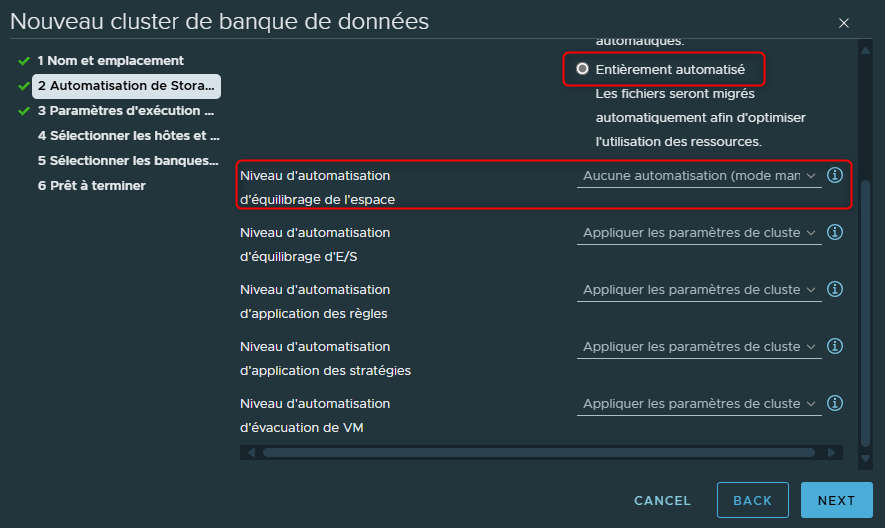
Nous pouvons outrepasser la configuration du Cluster pour les éléments suivants :
- Niveau d'automatisation d'équilibrage de l'espace
- Niveau d'automatisation d'équilibrage d'E/S
- Niveau d'automatisation d'application des règles
- Niveau d'automatisation d'application des stratégies
- Niveau d'automatisation d'évacuation de VM
Lorsque nous avons terminé notre sélection il faudra alors cliquer sur "Next" pour passer à l'étape suivante.
¶ Configuration des paramètres
Cette section va nous permettre de configurer les paramètres d'exécution de SDRS.
C'est à dire que nous allons définir les seuils à partir desquels SDRS enverra des recommendations ou effectuera des actions selon le mode précédemment choisi.
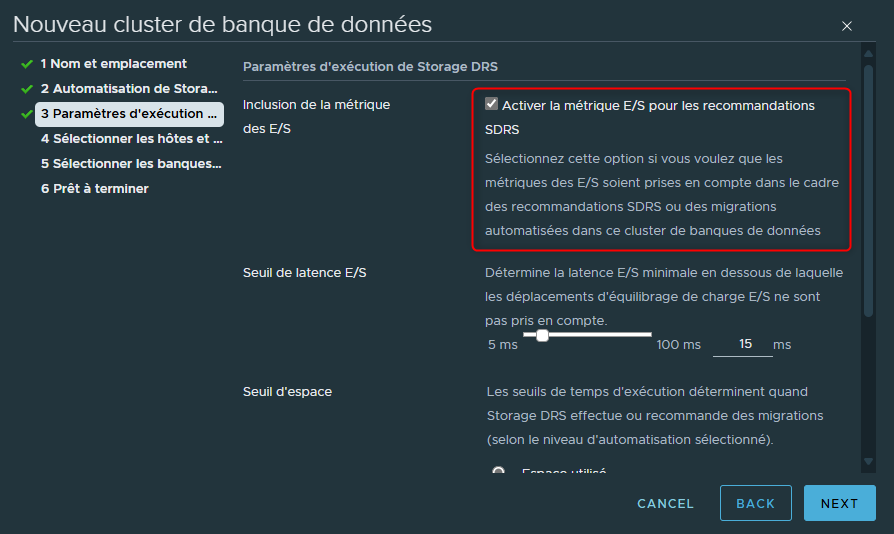
La première option que l'on peut voir et qui est d'ailleurs activée par défaut va nous permettre de déterminer si l'on souhaite que SDRS surveille les entrées-sorties de nos datastores.
Si l'on décoche cette case, nous n'effectuerons plus aucune surveillance des entrées-sorties de nos datastores. Nous ne pourrons plus déterminer si la latence du stockage est présente et si elle peut être améliorée.
C'est donc évidemment une case à laisser activée par défaut et à ne pas décocher.
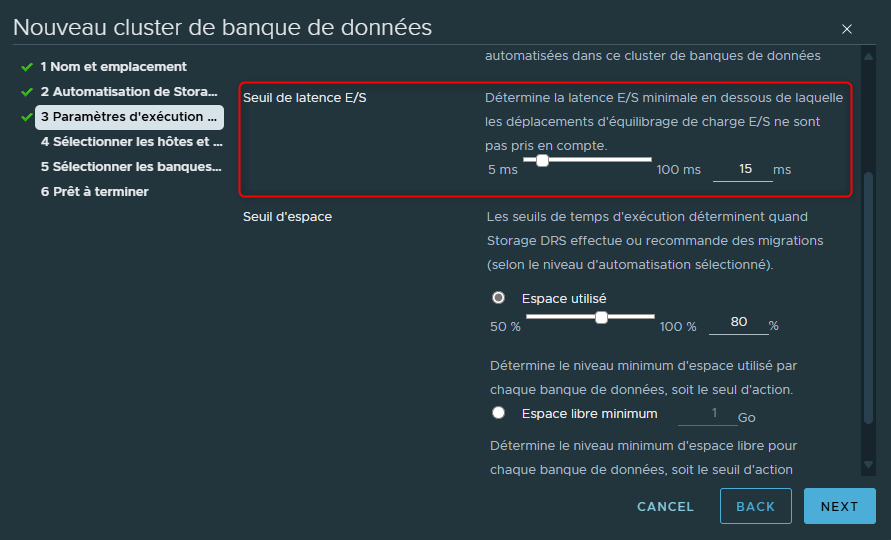
La seconde option va nous permettre de définir un seuil en dessous duquel la latence des I/O ne sera pas prise en compte. C'est à dire que toutes les latences constatées en dessous de ce seuil seront ignorées.
Par défaut le seuil est réglé à 15ms et il est possible de le modifier.
Donc si j'ai une VM qui possède une latence inférieure ou égale à 15ms vers le datastore, elle ne sera pas prise en compte pour les déplacements ou recommendations effetués par SDRS.
Par contre si sa latence dépasse les 15ms alors soit nous recevrons une recommendation soit la VM sera migrée via un Storage vMotion vers un autre datastore.
Encore une fois selon le mode de configuration choisi (manuel ou automatique).
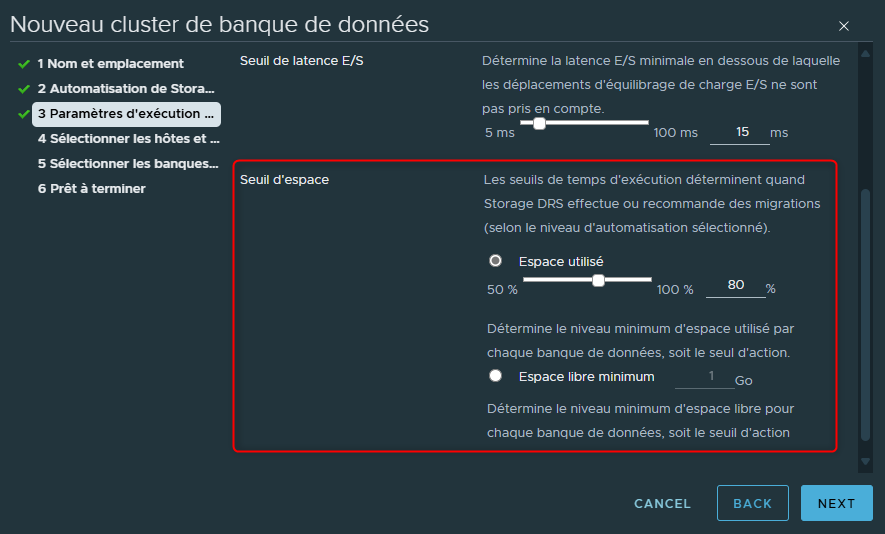
La troisème et dernière option ici concerne l'espace de stockage de nos datastores.
De la même manière que nous avons défini un seuil pour la latence, nous pouvons en définir un pour l'espace de stockage de nos datastores.
Ce seuil peut être est défini de deux manières. Soit en pourcentage d'utilisation soit en quantité d'espace libre minimum sur les datastores.
Si je choisi de sélectionner l'option pourcentage d'utilisation, lorsqu'un datastore sera rempli jusqu'à atteindre le pourcentage indiqué alors SDRS enverra une recommendation ou procèdera immédiatement à un rééquilibrage via un Storage vMotion pour passer en dessous du pourcentage indiqué.
Par défaut le pourcentage est de 80% mais il sera possible de le modifier selon les besoins.
Si je choisi de sélectionner l'option espace libre minimum, lorsqu'un datastore possèdera une quantité d'espace libre inférieure à la quantité indiquée alors SDRS entrera en scène.
Par défaut la quantité d'espace libre est placée à 1Go mais il sera également possible de la modifier.
Passons maintenant à l'étape suivante en cliquant sur "Next"
Nous allons à présent choisir les datastores qui seront utilisés pour créer notre Cluster mais avant cela nous devons choisir les hôtes qui utiliseront le Cluster.
Soir vous avez un Cluster d'ESXi soit vous avez des ESXi en mode standalone.
il faudra sélectionner ce qui correspond à votre configuration puis cliquer sur "Next".
Dans mon cas je vais sélectionner le Cluster contenant les deux ESXi de démo.
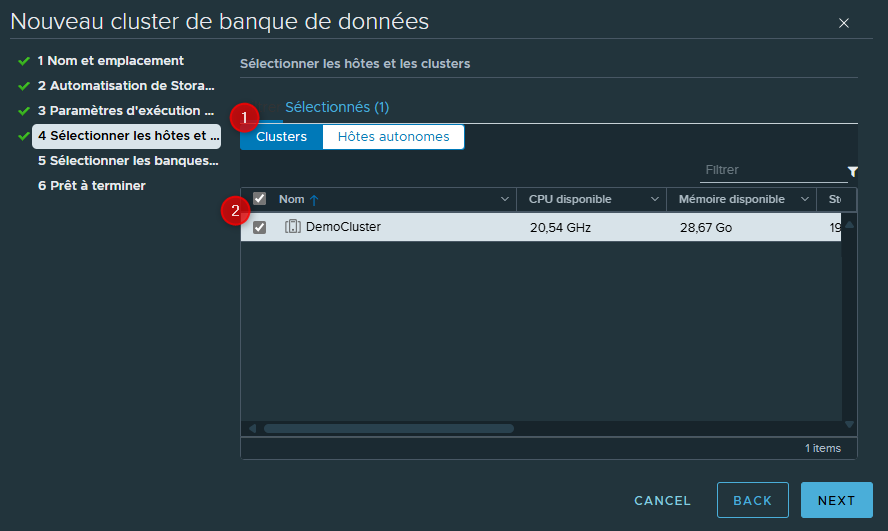
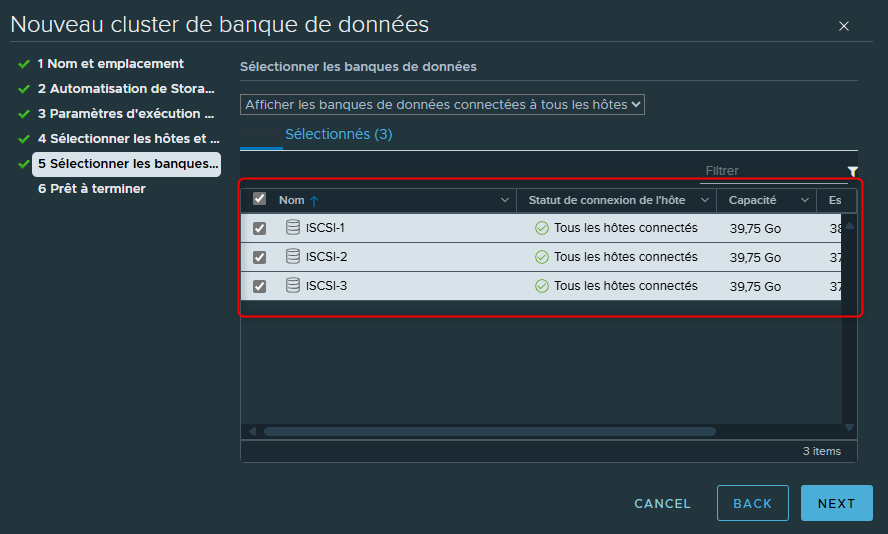
Puis sélectionner les datastores.
Dans mon cas il va s'agir des trois datastores en iSCSI spéciélement créés pour cette documentation et dont j'ai parlé précédemment.
Attention, par défaut nous ne verrons que les datastore connectés à l'ensemble des ESXi sélectionnés mais il sera possible d'afficher tous les datastore y compris les datastore locaux. Evidemment il n'est pas du tout recommandé de créer un Cluster avec des datastores locaux si l'on souhaite avoir du Storage vMotion 
On ne va donc pas les sélectionner...
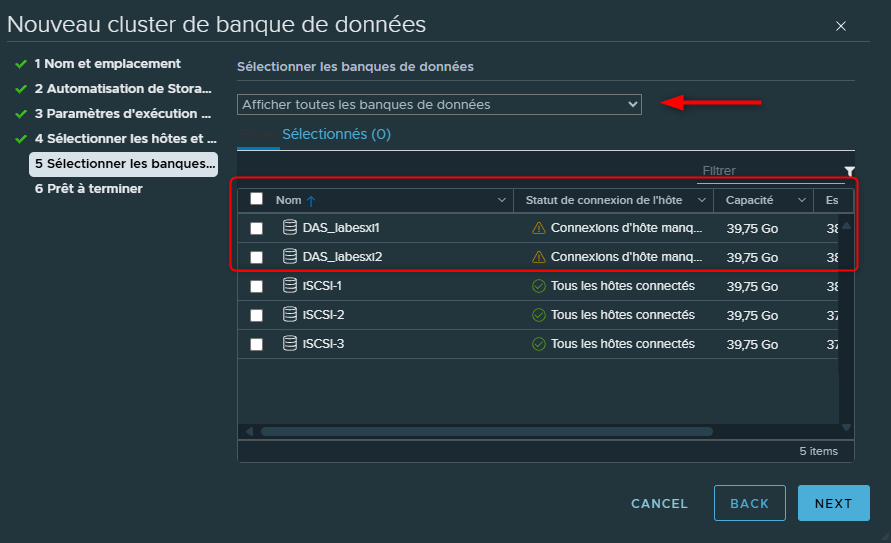
Une fois la sélection des datastores effectuée on clique sur "Next"
On peut vérifier la configuration du Cluster puis cliquer sur "Finish" pour valider sa création.
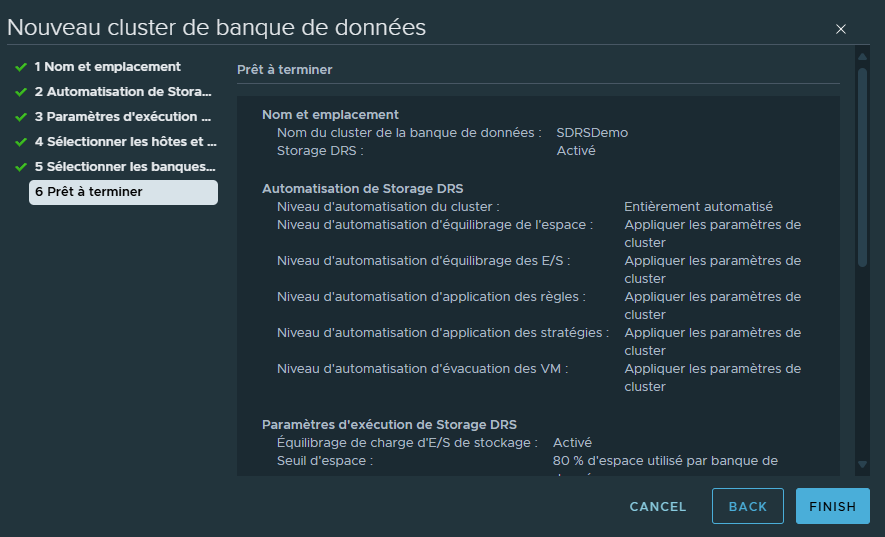
Nous avons correctement créé un Cluster de datastores pour notre Cluster d'ESXi.
Il sera visible dans la section stockage de vCenter.
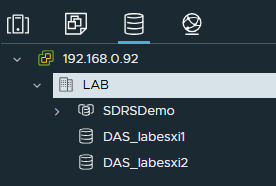
¶ Fonctionnement d'un Cluster de datastores
Maintenant que notre Cluster est opérationnel voyons un peu comment il fonctionne.
J'ai donc créé une VM qui se trouve pour l'instant dans le datastore local de l'ESXi "labesxi1".
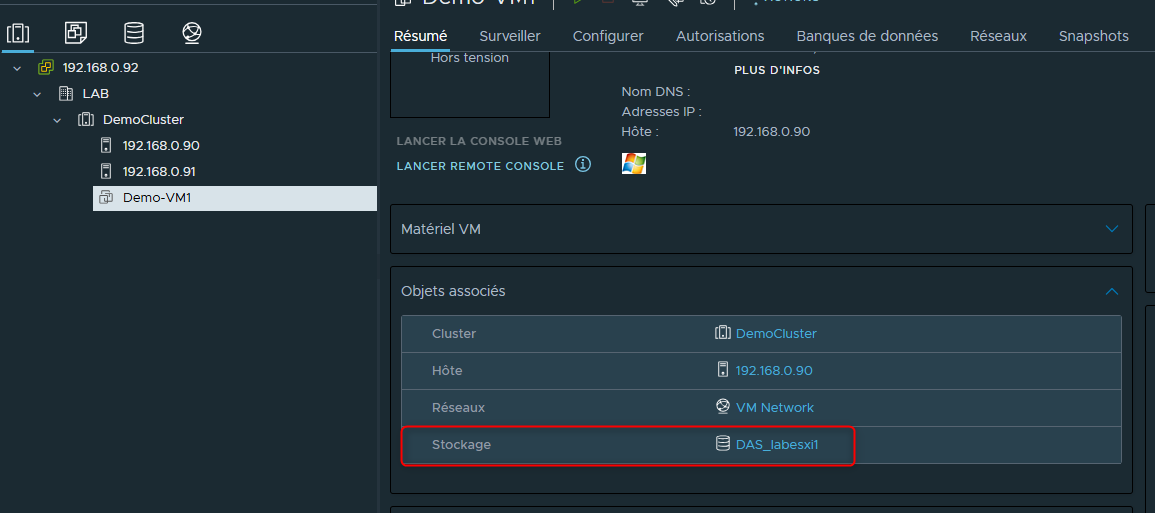
Nous allons la migrer vers notre Cluster de datastores.
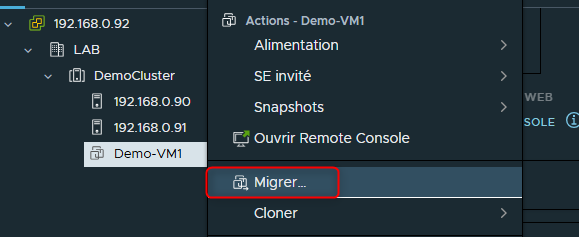
Faire un clic droit sur la VM et sélectionner "Migrer"
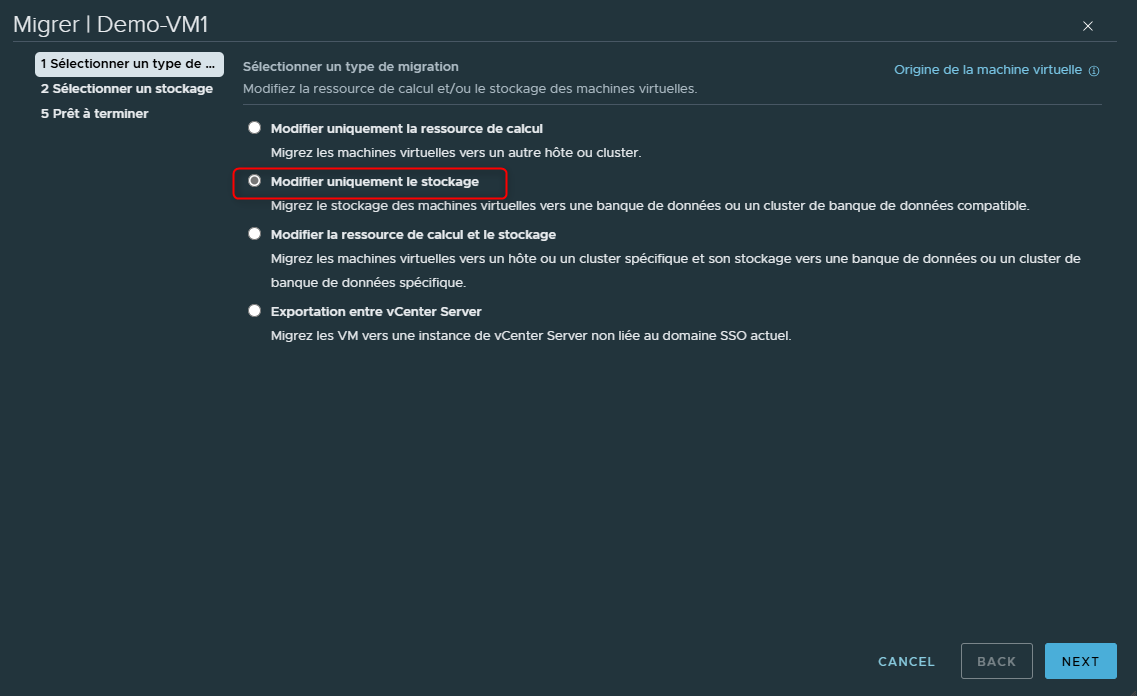
Puis sélectionner "Modifier uniquement le stockage"
Sélectionner le Cluster de datastores que l'on vient de créer et cliquer sur "Next".
Notez bien que lors du choix du datastore, les datastores iSCSi1 à 3 utilisés précédemment ne sont plus visibles mais que nous avons à la place le Cluster en lui même.
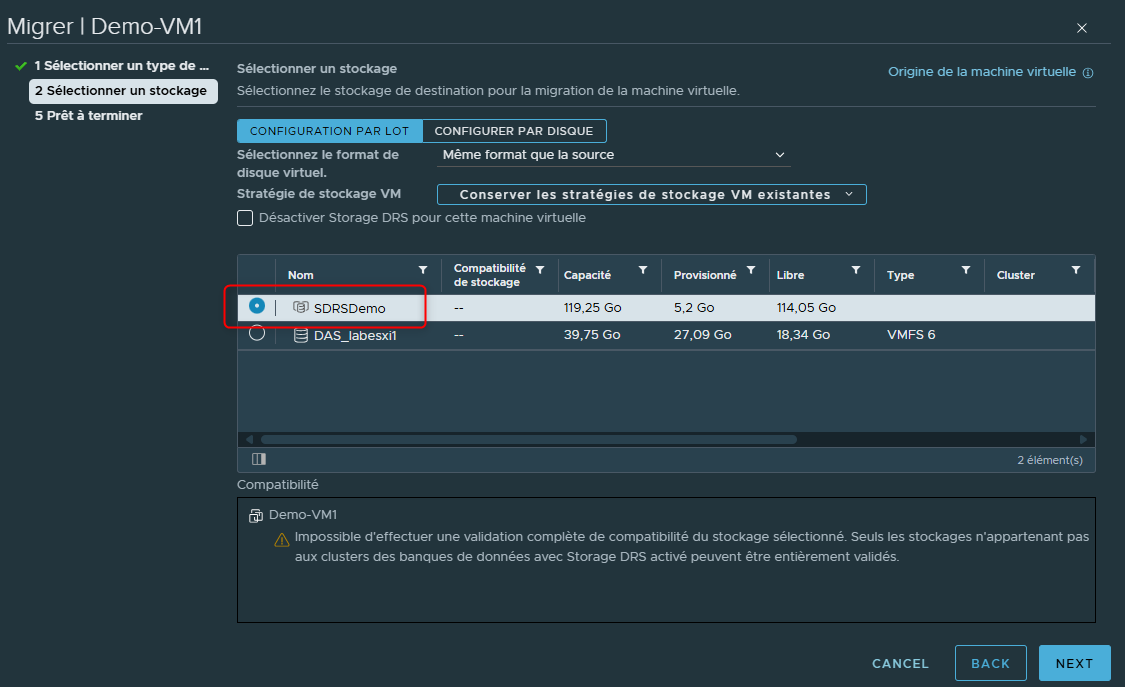
Vérifier les informations et cliquer sur "Finish" pour lancer la migration du stockage.
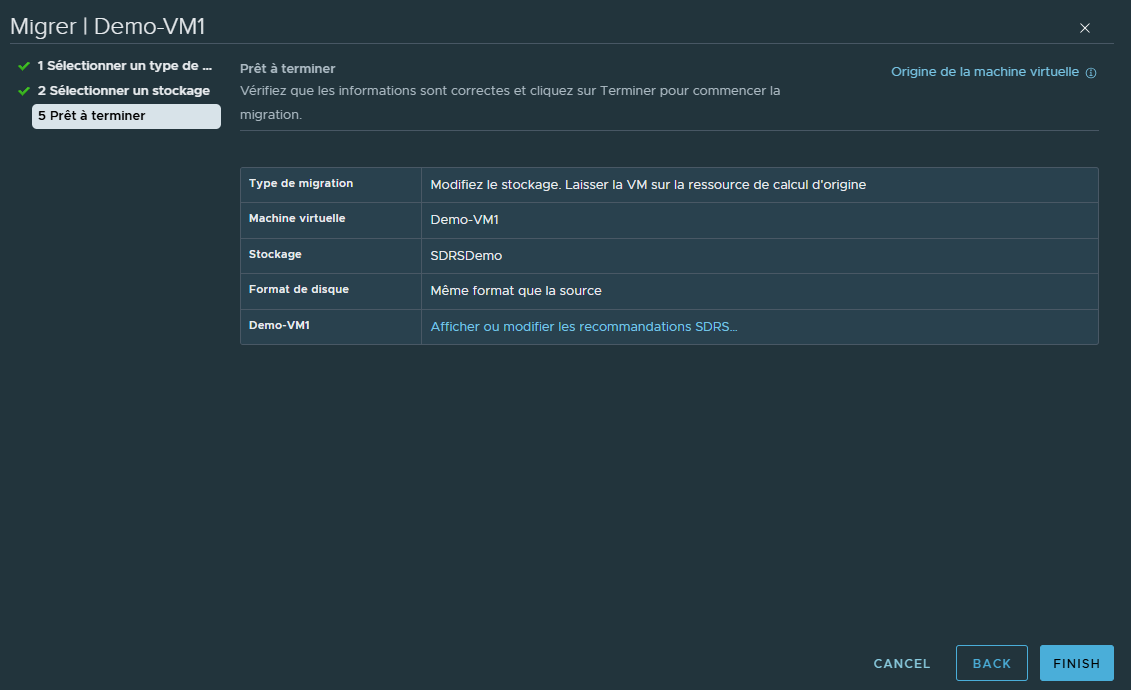
Lorsque la migration sera terminée, nous pourrons voir que notre VM sera à présent stockée dans le Cluster de datastores.
Elle sera donc stockée sur l'un des 3 datastores qui composent le Cluster mais en aucun cas je ne pourrai choisir celui qui l'hébergera.
C'est SDRS qui choisira pour nous.
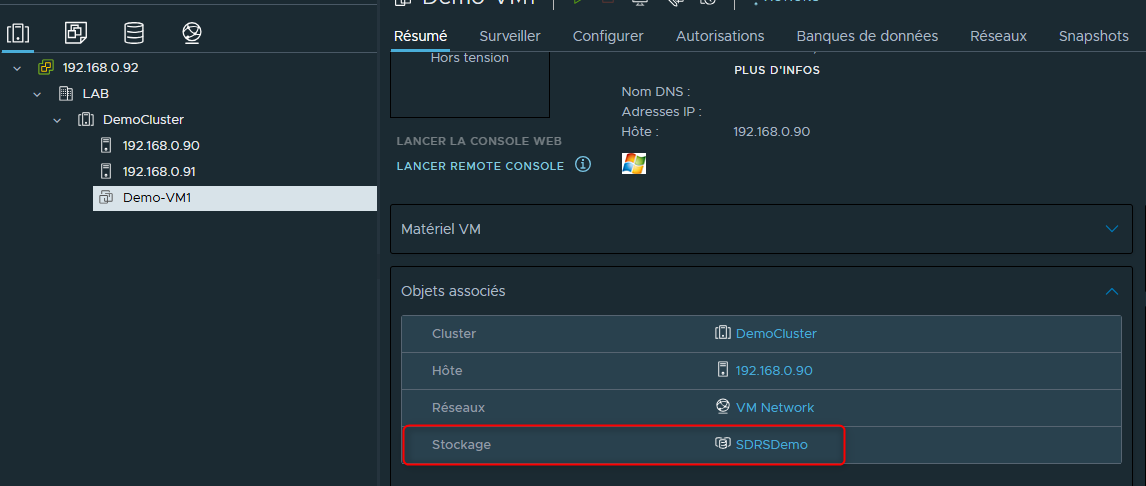
Si nous souhaitons savoir quel datastore héberge réellementr la vM, il faudra cliquer sur un datastore puis sur VM en haut à droite et chercher la VM en question.
Ici je n'ai qu'une seule VM elle a donc été assez simple à trouver. Elle se trouve dans le datastore iSCSI-1.

En cliquant sur le CLuster nous pourrons retrouver dans la section "Résumé" les informations le concernant.
On y verra l'espace utilisé, l'espace libre, les règles que l'on a défini auparavant, s'il y a des pannes, etc.
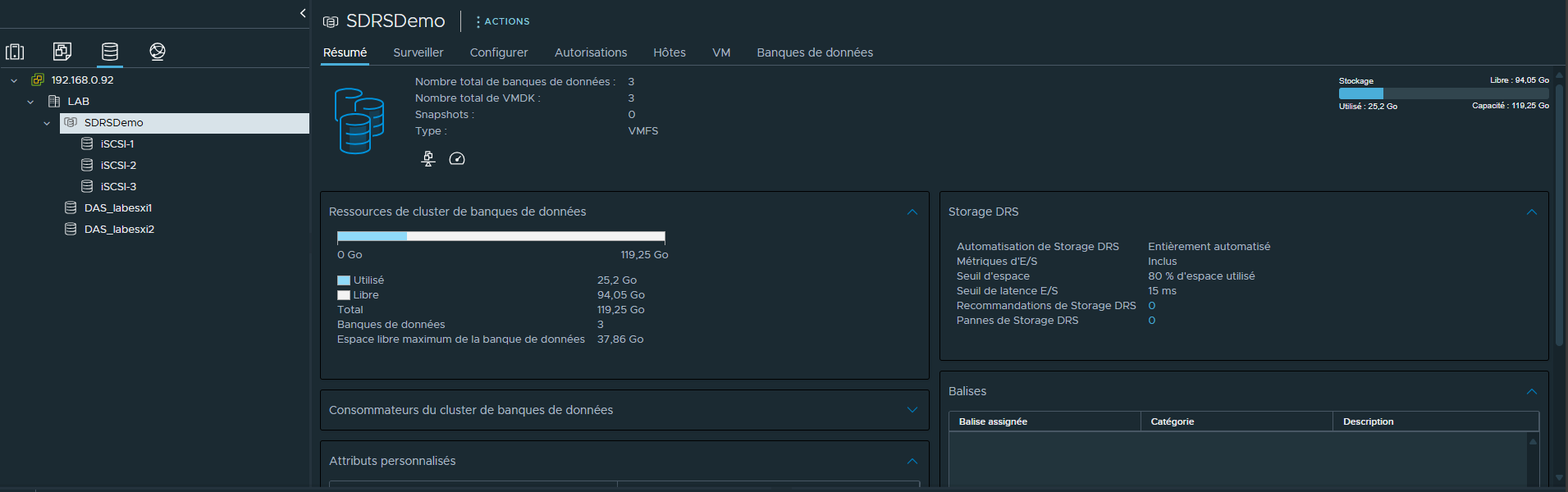
Notre Cluster est créé, il est opérationnel et il héberge une VM.
Nous avons donc réussi à créer un Cluster de datastores pour équilibrer la charge en fonction de la capacité disponible et de la latence.
Chapitre précédent : 12- Introduction to Storage DRS (SDRS) : Review - Chapitre suivant : 14 - vSAN vs baie de stockage traditionnelle