¶ Introduction
Dans cette documentation nous allons voir ensemble comment créer un cluster Proxmox avec deux nœuds, sans activer la haute disponibilité (HA) et sans utiliser de Qdevice pour le quorum.
Ce type de configuration est souvent utilisé en lab, en environnement de test ou dans de petites infrastructures mais elle présente toutefois des limitations importantes que nous aborderons en détail.
Je ne conseille ABSOLUMENT PAS de reproduire cette configuration et la présente uniquement à titre informatif.
L'environnement Proxmox que j'utilise pour faire cette documentation est un environneent virtuel.
C'est à dire que les serveurs Proxmox que je vais utiliser sont des VMs cependant la procédure reste identique avec du matériel physique.
¶ Prérequis
- Deux serveurs (physiques ou VMs)
- Même version de Proxmox VE sur les deux nœuds
- Avoir accès à l'interface graphique de Proxmox.
- Un compte ayant suffisament de droits pour effectuer les manipulations.
- Une connectivité réseau stable entre les deux nœuds
- De préférence une latence faible (idéalement < 5 ms surtout pour de la prod)
- Débit recommandé : 1 Gbps minimum (10 Gbps idéal)
- Nom d’hôte correctement défini
- Résolution DNS ou /etc/hosts fonctionnelle (important)
¶ Inconvénients
Avant de commencer la configuration il est important de prendre en comptes les différents problèmes que peut générer un Cluster à 2 nœuds ne possédant ni HA ni Qdevice pour le quorum.
En effet, mettre en place un cluster à deux nœuds avec Proxmox peut sembler simple et séduisant, mais cette architecture repose sur des bases fragiles : sans haute disponibilité (HA) et sans qdevice, plusieurs problèmes structurels apparaissent.
ATTENTION : J'insiste et je vous invite à bien prendre connaissance des informations suivantes avant de configurer un Cluster un cluster Proxmox avec deux nœuds sans activer la haute disponibilité (HA) et sans utiliser de Qdevice pour le quorum.
Il est important de garder en tête de NE JAMAIS faire cette configuration en Prod.
¶ Le problème du quorum
Dans un cluster, le quorum représente le nombre minimum de nœuds nécessaires pour que le système considère que l’état du cluster est fiable et cohérent.
Autrement dit, le quorum est un mécanisme qui permet de garantir l’intégrité du cluster.
Dans un cluster à 2 nœuds, chaque nœud possède 1 vote pour un total de 2 votes or le Quorum requis est lui aussi égal à 2 (majorité stricte).
Le quorum se calcul comme ceci : quorum = (nombre de nœuds / 2) + 1 et dans notre exemple il est bien égal à 2.
Cela signifie que les deux nœuds doivent impérativement être actifs et communiquer entre eux pour que le cluster fonctionne.
Dans cette configuration, si un nœud tombe (panne matérielle, coupure réseau, reboot) il ne restera qu’un seul vote actif et le quorum ne sera plus atteint.
Le cluster basculera alors en mode de sécurité, les actions critiques seront bloquées et certaines opérations deviendront impossibles (démarrage VM, modifications, etc.)
Ce comportement est valable même si le nœud restant est parfaitement fonctionnel puisqu'il se comportera comme s’il n’était plus autorisé à agir.
Il s'agit en réalité d'un comportement est volontaire pour éviter des incohérences graves.
¶ Le risque de split-brain
Le split-brain est l’un des pires scénarios dans un cluster.
Il survient généralement lors d’une perte de communication entre les deux nœuds (ex : câble réseau débranché, switch HS, problème VLAN, etc.).
Dans ce cas le nœud A ne voit plus le nœud B et le nœud B ne voit plus le nœud A
Sans mécanisme tiers comme un qdevice, chaque nœud peut croire qu’il est le seul nœud encore actif.
Même si Corosync tente d’éviter ce scénario via le quorum, certaines manipulations peuvent aggraver la situation.
Pour rappel, Corosync est le cœur du cluster Proxmox et prend en charge :
- La gestion de la communication entre les nœuds.
- La synchronisation de la configuration.
- La détection des nœuds actifs et inactifs.
En cas de split-brain nous pourrons avoir plusieurs conséquences possibles :
- Une même VM peut être démarrée sur les deux nœuds.
- Des écritures simultanées sur un stockage partagé.
- Des corruptions de données.
- Des incohérences irréversibles.
Dans ce cas et sans un "arbitre externe" il est alors impossible de déterminer “qui a raison” en cas de désaccord des nœuds.
¶ Absence totale de haute disponibilité (HA)
Dans un cluster classique avec HA si un nœud tombe pour une raison ou une autre, les VM sont automatiquement redémarrées sur un autre nœud.
Mais dans notre exemple, sans HA, il n'y aura :
- Aucun redémarrage automatique.
- Aucun monitoring intelligent des services.
- Aucun failover.
- etc.
Par exemple, si un serveur Proxmox s’éteint brutalement, l'ensemble des VMs qu’il héberge seront arrêtées. Aucune d'entre elles ne sera redémarées ailleurs et un administrateur devra intervenir manuellement.
Autant dire que cela annule en grande partie l’intérêt d’un cluster dans un contexte de production.
¶ Maintenance et exploitation
Dans un cluster à 2 nœuds, toute opération de maintenance devient compliquée.
Par exemple, redémarrer un nœud devient tout de suite complèxe.
Dès qu’un nœud est arrêté alors le quorum est perdu et le cluster devient partiellement bloqué.
Cela implique donc des difficultés à appliquer les mises à jour, un risque d’interruption de service et nécessité des manipulations manuelles qui peuvent être risquées (l'erreur est humaine).
¶ Aucune tolérance de pannes
Un cluster est supposé améliorer la résilience.
Dans le cas de la configuration du cluster que je vais créer pour cette documentation il est important de tenir compte de ces éléments :
- Une panne = cluster dégradé ou inutilisable.
- Pas de redondance décisionnelle.
- Pas de continuité de service automatique.
- Pas de HA.
¶ Dépendance critique au réseau
Le bon fonctionnement du cluster repose entièrement sur Corosync qui utilise le réseau pour :
- Synchroniser les états.
- Échanger les votes.
- Maintenir le quorum.
Dans ce cas une simple instabilité réseau peut entraîner une perte de quorum, des désynchronisations et un blocage du cluster.
En effet, contrairement à un cluster à 3 nœuds ici il n’y a aucune tolérance aux micro-coupures réseau.
Je le dis à nouveau mais pour tout environnement sérieux il est fortement recommandé d’ajouter un 3ème nœud ou un qdevice pour stabiliser le quorum.
Ça tombe bien nous verrons ça dans une autre documentation ICI 
¶ Configuration du réseau
¶ Architecture réseau recommandée
Idéalement il faut à minima deux interfaces réseau sur les serveurs Proxmox :
- 1 interface pour le management
- 1 interface dédiée au cluster (Corosync)
Exemple :
| Usage | Interface | IP |
|---|---|---|
| Management | vmbr0 | 192.168.60.x |
| Cluster | vmbr1 | 192.168.70.x |
¶ Configuration des interfaces
Voici un exemple de la configuration réseau nécessaire pour créer le Cluster.
On y retrouvera nos deux cartes réseau ainsi que les subnets dédiés à chacune d'elles.
Cette configuration est à mettre dans /etc/network/interfaces et sera a faire sur les deux serveurs en prennant évidemment soin de ne pas utiliser les mêmes adresses sur les deux nœuds.
auto lo
iface lo inet loopback
iface ens192 inet manual
iface ens224 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.60.1/24
gateway 192.168.60.254
bridge-ports ens192
bridge-stp off
bridge-fd 0
auto vmbr1
iface vmbr1 inet static
address 192.168.70.1/24
bridge-ports ens224
bridge-stp off
bridge-fd 0
¶ Configuration du Cluster
¶ En CLI
¶ Configuration
Pour créer le Cluster en utiliant les lignes de commande (CLI) il faudra effectuer les manipulations suivantes :
# Sur le premier serveur Proxmox
pvecm create Cluster-Name
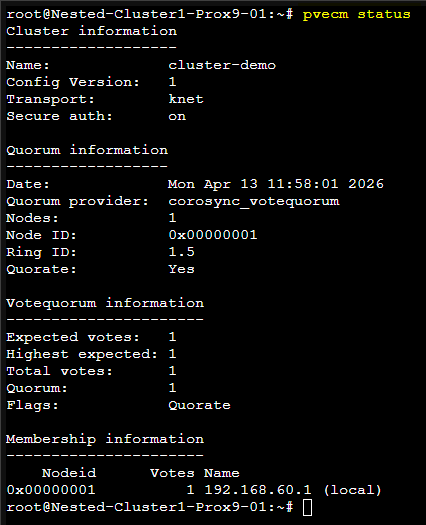
Une fois la commande passée on peut vérifier que le Cluster est correctement créé à l'aide de la commande suivante : pvecm status
Le résultat sera comme ceci :
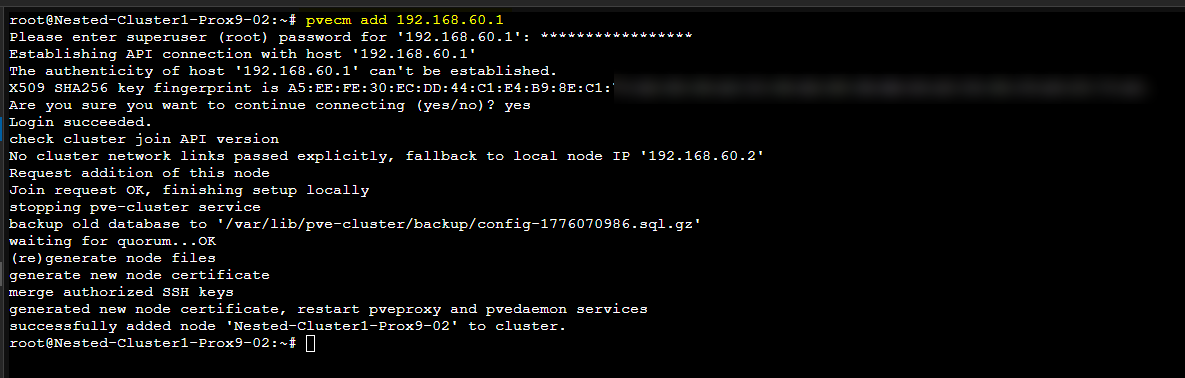
Une fois le Cluster créé il faudra en suite ajouter le second serveur Proxmox
# Sur le second serveur Proxmox
pvecm add 192.168.60.1 # adresse IP du premier serveur PVE
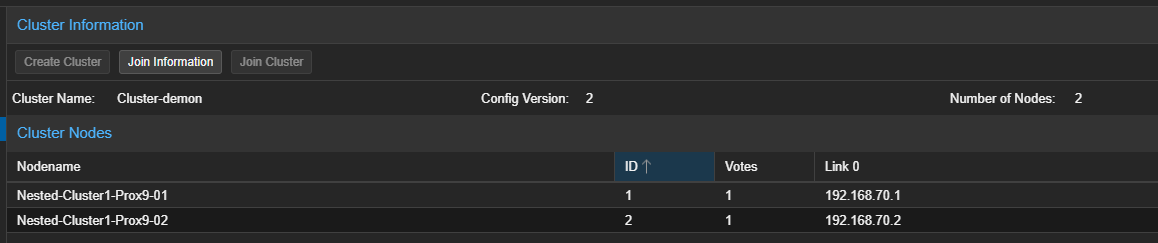
Après avoir ajouté le second serveur Proxmox au Cluster, les deux serveur seront visibles depuis leur interface graphique.
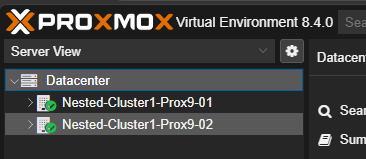
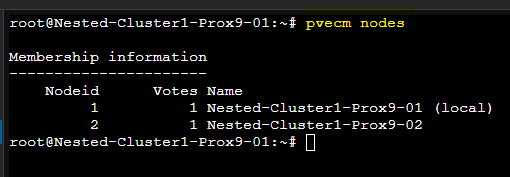
Il sera également possible de vérifier le Cluster avec les commandes suivantes :
pvecm nodes
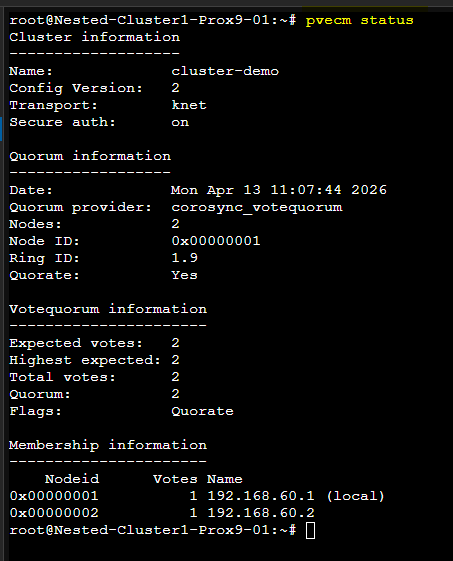
pvecm status
¶ Modification du lien Corosync
Nous venons créer un Cluster et d'ajouter le second nœud cependant le réseau utilisé ne correspond pas à celui que nous avons configuré et qui sera dédié à Corosync.
Pour utiliser le réseau dédié nous allons devoir faire quelques modifications.
- Editer le fichier
/etc/pve/corosync.conf
Dans la partie "nodelist", modifier l'adresse ip par celle du réseau dédié
AVANT
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.60.1
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.60.2
}
}
APRES
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.70.1 # <== ICI
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.70.2 # <== ICI
}
}
ATTENTION : Pour que la modification soit prise en compte il faudra redémarrer le service corosync sur chacun des nœuds :
systemctl restart corosync
¶ Vérifications
Nous pouvons vérifier que la modification a bien été prise en compte en utilisant à nouveau la commande pvecm status
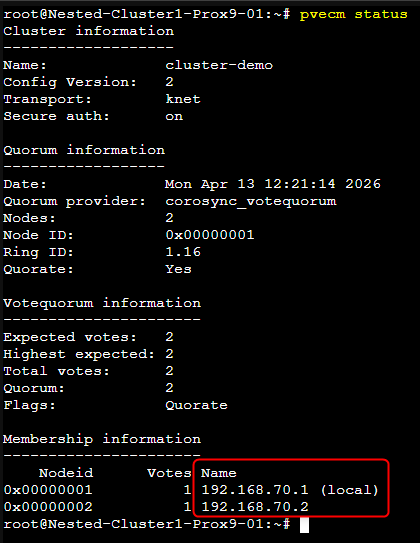
¶ En mode graphique
¶ Sur le premier serveur Proxmox.
- Cliquer sur Dataceter puis cliquer sur Cluster.
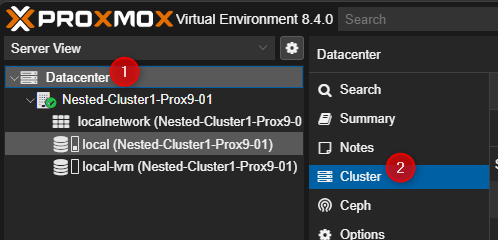
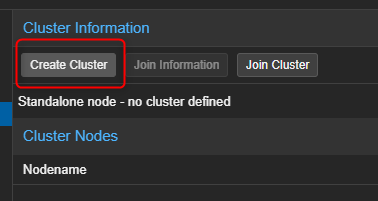
- Dans la partie de droite cliquer sur "Create Cluster".
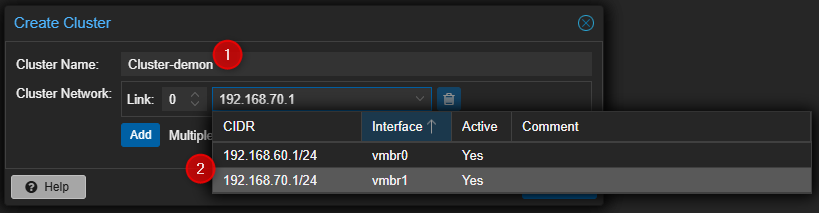
- Entrer un nom pour le Cluster et sélectionner l'interface qui sera utilisée pour les communications du Cluster.
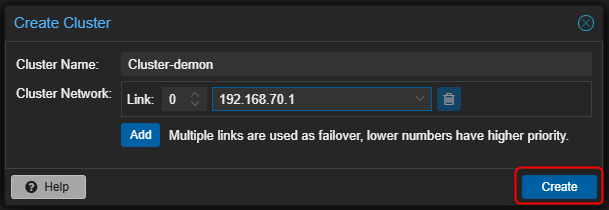
- Cliquer sur "Create" pour valider la création.
- Attendre la fin de la tâche de création.
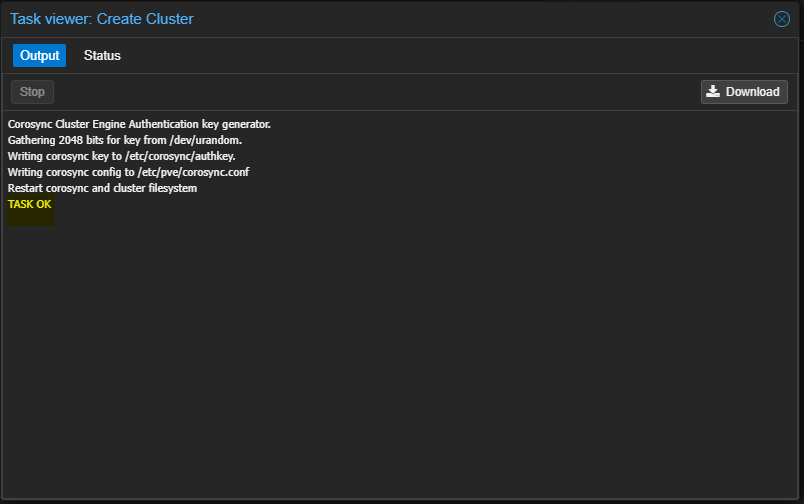
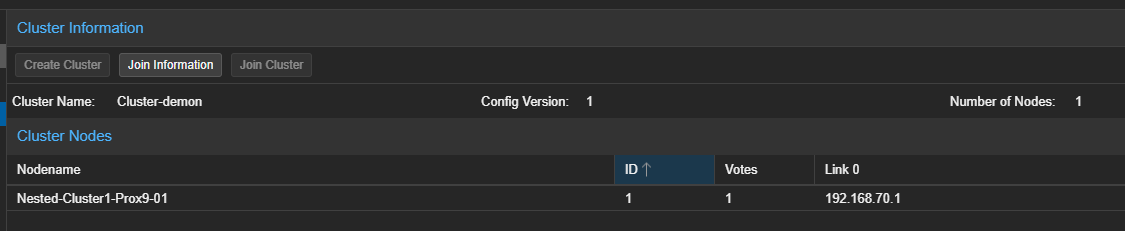
- Le Cluster sera visible dans la partie de droite.
- Récupérer les informations permettant de joindre le Cluster.
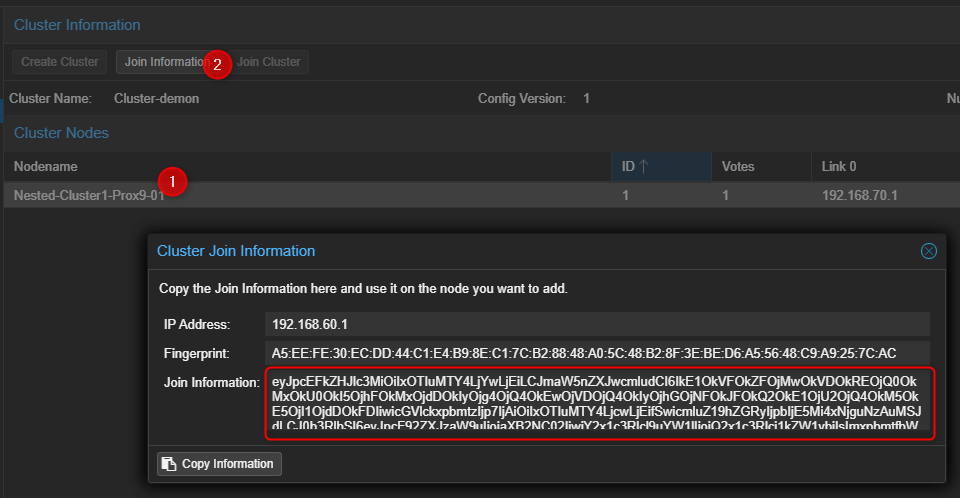
¶ Sur le second serveur Proxmox.
- Cliquer sur Dataceter puis sur Cluster et pour terminer sur "Join Cluster" dans la partie de droite.
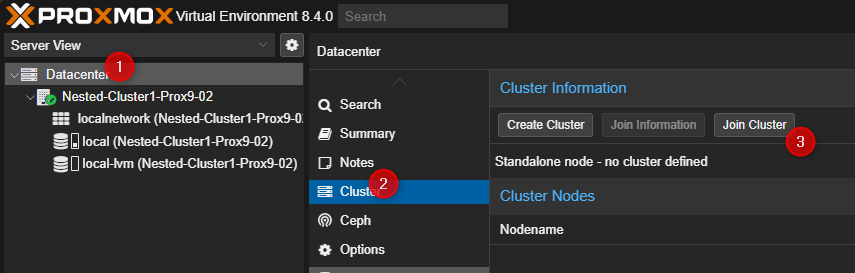
- Entrer les liens d'accès au cluster, le password du compte root du premier serveur PVE, sélectionner l'interface qui sera utilisée pour le cluster puis cliquer sur "Join" en bas à droite.
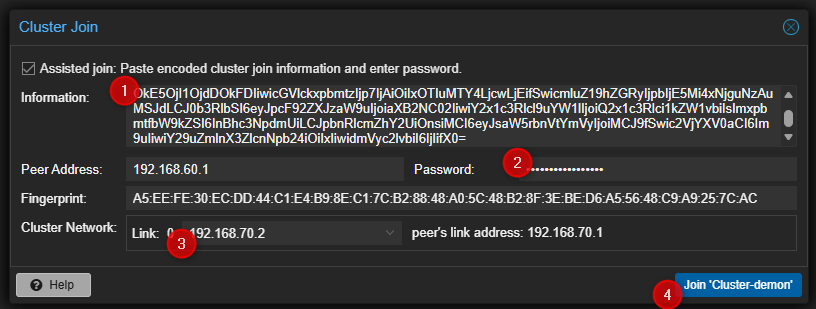
- Attendre la fin de la tâche puis vérifier que le serveur a bien été join au Cluster.