![]()
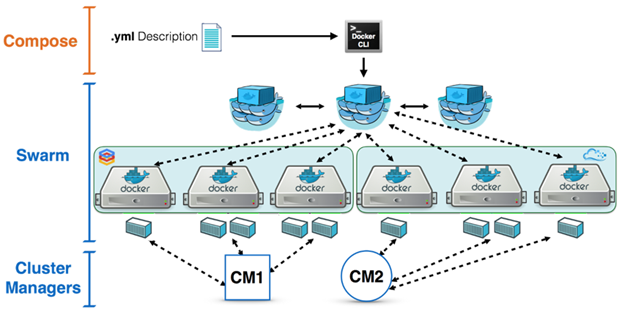
¶ IV – Docker Swarm
¶ A - Presentation de Docker Swarm

¶ 1 – Le mode « Swarm »
« Docker Swarm » est un « mode » de « Docker Engine » qui permet la gestion de cluster de type Docker comprenant n’importe quel nombre d’hôtes Docker. Il permet également d’effectuer une gestion centralisée du cluster ainsi que l’orchestration des différents conteneurs, des volumes, des réseaux, etc.
L’avantage de « Docker Swarm » est qu’il est déjà intégré par défaut à Docker.
Lorsque les nœuds Docker ne fonctionnent pas dans un cluster Swarm, on dit qu’ils sont dans un « single-engine mode ».
Au contraire, dès qu’ils sont intégrés dans un cluster ils fonctionnent en « swarm mode »., c’est pour cela que je parle de « mode ».
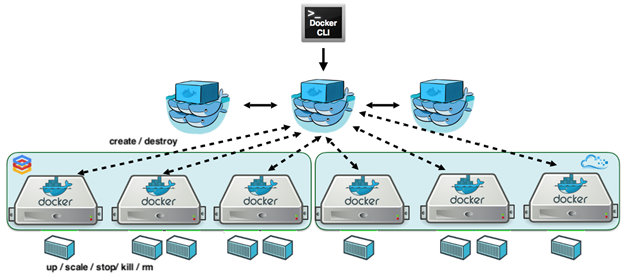
« Docker Swarm » est basé sur une architecture de type « maître-esclave ».
Chaque cluster Docker se compose d’au moins un nœud de gestion appelé « Swarm Manager » et d’un nombre quelconque de nœuds Docker appelés des « Swarm Workers » (ou simplement « Workers) afin de déployer des services, des conteneurs, des stacks, etc. par le biais de filtres ou de stratégies de déploiement.
Le « Swarm Manager » est responsable de la gestion du cluster et de la répartition des tâches tandis que les « Swarm Workers » prennent en charge l’exécution des différentes tâches.
¶ 2 – Les fonctionnalités
Docker Swarm est un mode particulièrement complet qui possède de nombreuses fonctionnalités.
Voici une liste des plus importantes :
- Swarm est intégré dans le moteur « Docker Engine ». Aucune installation supplémentaire n’est nécessaire car il suffit juste d’activer le « mode swarm »
- Planification avancée des déploiement via des stratégies ou des filtres
- Assurer la « scalabilité » et la flexibilité de l’infrastructure, en augmentant ou diminuant le nombre d’hôtes du cluster, des conteneurs ou des services, etc. Il s’agit d’une mise à l’échelle du nombre de nœuds, conteneurs, services, etc.
- Load Balancing. Activé par défaut entre les différents serveurs du cluster. En interne il est possible de préciser comment répartir les différents conteneurs entre les nœuds. Il est également possible d’utiliser un équilibreur de charge externe en ouvrant des ports.
- Toutes les communications dans le cluster sont sécurisées et chiffrées. Chaque nœud du swarm applique l'authentification et le chiffrement mutuels TLS pour sécuriser les communications entre lui-même et tous les autres nœuds. Nous avons aussi la possibilité d’utiliser des certificats racine auto-signés ou des certificats provenant d'une autorité de certification racine personnalisée.
- Multi-host networking. Possibilité de mettre en place des réseaux virtuels permettant aux différents nœuds et conteneurs du cluster de communiquer entre eux. C’est-à-dire qu’on va pouvoir créer un ou plusieurs réseaux virtuels qui seront affectés à plusieurs hôtes Docker permettant ainsi leur communication ainsi que celle des conteneurs qu’ils hébergent.
- Rolling update. Il s’agit de la possibilité de mettre à jour les conteneurs et les services ou un type de conteneur et de service sans avoir à les détruire pour les redémarrer.
- Rolling back. Il s’agit ici de la possibilité de revenir en arrière en cas de problème suite à une mise à jour. Nous pourrons dans ce cas revenir à la version précédente qui était fonctionnelle.
Il existe bien d’autres fonctionnalité au cluster Docker. Je n’ai parlé ici que des plus intéressantes de mon point de vue.
Pour plus d’informations, il est possible de consulter la documentation officielle à cette adresse :
https://docs.docker.com/engine/swarm/
¶ 3 – Le « Swarm Manager »
Comme nous l’avons évoqué, dans un cluster Docker nous allons trouver un ou plusieurs nœuds appelés « swarm manager » (ou parfois leader). La configuration de plusieurs « Swarm Manager » permettra de mettre en place de la haute disponibilité.
Ces nœuds ont pour fonction de gérer l’ensemble du cluster ainsi que le cycle de vie du cluster lui-même à travers la gestion :
- Du cluster lui-même à travers le maintien de son état
- Des « stacks »
- Des services (créations, suppressions, modifications, etc.)
- Des nœuds qui composent le cluster
- Des updates
- Le mode de déploiement
- Etc.
Attention : Lorsqu’un « Swarm Manager » est down, un nœud du cluster est alors élu pour le remplacer et devient à son tour « Swarm Manager ».
¶ 4 – Les « Swarm workers »
Un « Swarm Worker » est une instance de « Docker Engine » qui participe au « Docker Swarm ».
Il ne participe pas au cycle de vie du cluster et ne prend aucune « décisions ».
Le seul but d’un « Worker » sera donc d'exécuter des conteneurs, des services, etc., en fonction des demandes et des besoins du « Manager ».
Pour cela, un agent s’exécute sur chacun des « Worker » afin de leur rapporter les différentes tâches qui leur sont affectées.
Les « Workers » notifient aux « Manager » l’état des tâches qui leur sont assignées afin que les « Manager » puissent maintenir l’état de chacun des « Worker ».
Cela permet par exemple de signifier aux « Managers » l’état des différents services, conteneur, etc. afin de savoir s’il faut les démarrer, arrêter, recharger, mettre à jour, etc.
¶ 5 – Les Services
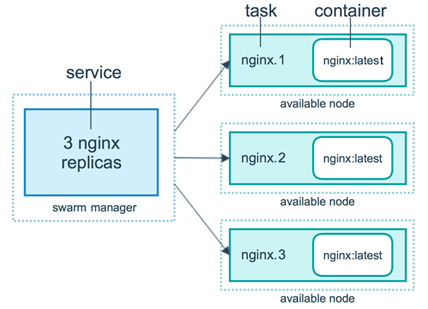
Un service est un réalité une tâche qui sera déployée via un « Manager » sur différents nœuds.
Il est composé d’un ou plusieurs conteneurs qui seront répliqué sur plusieurs nœuds.
Chaque service consiste donc en un ensemble de tâches individuelles, chacune traitée dans son propre conteneur sur l’un des nœuds du cluster.
Pour fonctionner, un service a besoin d’un conteneur et de commandes à exécuter sur celui-ci.
Docker Swarm supporte deux modes dans lesquels les « services Swarm » sont définis :
• Services répliqués : un service répliqué est une tâche qui s’exécute dans un nombre de répliques défini par l’utilisateur.
Chaque réplique est une instance du conteneur Docker défini dans le service. Les services répliqués peuvent être mis à l’échelle en créant des répliques supplémentaires. Par exemple, un serveur Web comme NGINX peut être mis à l’échelle à 2,4 ou 100 instances avec une seule ligne de commande.
• Services globaux : lorsqu’un service s’exécute en mode global, chaque nœud disponible dans le cluster démarre une tâche pour le service correspondant. Lorsqu’un nouveau nœud est ajouté au cluster, le gestionnaire Swarm lui assigne immédiatement une tâche pour le service global. Les services globaux sont adaptés, par exemple, à la surveillance d’applications ou de programmes anti-virus.
¶ 6 – Les Stacks
Un « stack » (ou « pile » en français) est une application multi-conteneurs.
Elle est composée de plusieurs conteneurs qui proposent chacun d’entre eux ce qu’on appelle un « micro-service ».
Elle est déployée à l’aide d’un fichier « compose », de la même manière que nous avons vu précédemment.
C’est-à-dire qu’à l’aide d’un fichier « compose » nous pourrons déployer via un « Swarm Manager » plusieurs conteneurs ensemble permettant d’avoir des « micro-services » qui fonctionnent ensemble.
Par exemple nous pourrions avoir un serveur Nginx dans un conteneur, sa base de données dans un autre conteneur, un autre conteneur avec le service PHP, etc.
L’association de ces différents « micro-services » à travers plusieurs conteneurs correspond donc à un « stack » et permettra de proposer un service complet basé sur plusieurs conteneurs tout en étant déployé par un fichier « compose ».
¶ B - Creation du cluster Docker
Dans cette partie de la documentation, nous allons voir comment mettre en place un « Docker Swarm ».
Pour cela, j’ai créé au total 5 machines virtuelles tournant sous Debian 9 et configuré sur chacune d’entre elles « docker Engine ».
Je ne reviendrai pas sur la mise en place de « Docker Engine » dans cette partie de la documentation car nous l’avons déjà évoqué.
¶ 1 – initialisation du Swarm
Pour rappel, « Docker Swarm » est un mode intégré au moteur Docker.
Pour initialiser ce mode il suffira simplement de taper une commande et le « swarm » sera alors créé sur l’hôte sur lequel on aura effectué cette commande.
Dans un premier temps, nous allons vérifier l’activation de « swarm » sur notre hôte
docker info | grep -i swarm
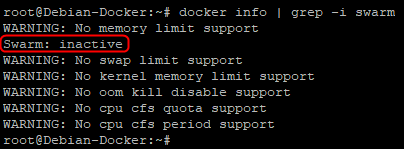
Attention : l’option « -i » permet de ne pas respecter la casse
Le mode swarm n’est pas actif sur notre hôte et nous allons donc pour voir l’initialiser.
Pour cela, la commande à taper est la suivante :
docker swarm init

On peut à nouveau vérifier si le swarm est initialisé avec la commande précédente
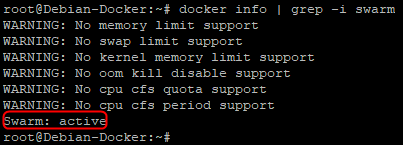
Le mode swarm est maintenant initialisé, notre hôte est devenu automatiquement un « swarm manager » et il ne reste plus qu’à y ajouter des nœuds.
Bonus :
Petite précision lors de l’initialisation du Swarm. Dans mon cas il s’agit de VM qui ont été créées spécialement pour cette documentation et qui ne possèdent qu’une seule carte réseau cependant en entreprise il n’est pas rare d’avoir des VM avec plusieurs cartes réseaux.
Dans ce cas, lors de l’initialisation du « swarm » la commande effectuée précédemment ne fonctionnera pas.
En effet, il sera obligatoire de préciser l’une des adresses IP de l’hôte afin de l’utiliser pour le swarm
La commande à taper sera alors la suivante :
docker swarm init --advertise-addr "IP_ciblée"
Une fois le swarm initialisé, il sera possible de lister les différents nœuds qui le composent à l’aide de la commande
docker node ls

On retrouvera le détail des nœuds avec leur ID, leur nom d’hôte, le statut mais également l’information précisant s’il s’agit d’un « leader » ou d’un « worker »
¶ 2 – Ajout des « Workers »
Maintenant que nous avons correctement initialisé un « docker swarm » il va nous falloir y ajouter des nœuds.
Pour rappel, j’ai 5 VM tournant sous Debian 9 sur lesquelles « Docker Engine » est installé.
La première VM a été utilisée pour initialiser le swarm et est donc à présent un « leader » du cluster.
Je vais à présent ajouter 3 « Workers » à ce swarm.
Pour les ajouter, il faudra taper la commande suivante :
docker swarm join --token "ID_du_token" "IP_du_manager":"2377"

Le token ainsi que la commande exacte nous a d’ailleurs été fourni lors de l’initialisation du swarm.
Dans mon cas le token est « SWMTKN-1-5f1bypg13oa8ke3jye9knnefrcnx650e3uw0otirshpup8n1ch-9ry4axv9m4d3toc1co56h3mt9 »
Il me suffira donc de me connecter sur un des futurs « Workers » puis de taper la commande suivante pour l’ajouter au swarm en tant que « worker »
docker swarm join --token "SWMTKN-1-5f1bypg13oa8ke3jye9knnefrcnx650e3uw0otirshpup8n1ch-9ry4axv9m4d3toc1co56h3mt9" "192.168.189.158":"2377"

Le nœud a été ajouté avec succès au swarm en tant que « Worker ».
Je vais donc recommencer cette procédure pour les deux autres nœuds que je souhaite ajouter en « worker ».


Une fois les différents « Workers » ajoutés au swarm je peux à nouveau lister les différents nœuds du swarm avec la commande « docker node ls »

¶ 3 – Ajout des « managers»
De la même manière que j’ai pu ajouter des « Workers » dans le swarm je vais pouvoir ajouter des « leaders ».
Actuellement parmi les différentes VM que j’ai créées pour ce lab, j’ai 1 « leader » et 3 « Workers ». Il me reste donc une VM à disposition.
Je vais l’ajouter au swarm en tant que « leader ». Pour cela, il faudra taper la commande suivante sur le manager :
docker swarm join-token manager
Cette commande nous avait également été indiquée lors de l’initialisation du swarm sur le premier manager


Une fois la commande tapée sur le manager, nous obtenons une nouvelle commande mais cette fois-ci à taper sur le nœud qui est destiné à être le futur manager.
Cette commande se présente de la même manière que celle d’ajout de « Workers » à la différence que le token qui a été généré permettra d’ajouter le nœud en tant que manager.
docker swarm join --token "ID_du_token" "IP_du_manager":"2377"

Malheureusement on ne voit pas très bien sur la capture donc je vais prendre que la phrase qui nous intéresse le plus ici :
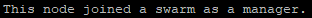
Une fois le nouveau « manager » ajouté au swarm je peux encore lister les différents nœuds du swarm avec la commande « docker node ls »

Nous pouvons constater dans la colonne « Manager Status » l’apparition d’une nouvelle information. Nous verrons plus en détail ce que tout cela signifie par la suite cependant le fait de voir une nouvelle information dans cette colonne indique que notre nœud est maintenant un des « Manager »du cluster.
¶ C - Gestion des noeuds
¶ 1 – La commande « docker node ls »
Nous l’avons vu précédemment, la commande « docker node ls » permet de lister les différents nœuds qui composent le cluster.
Nous allons voir ici un peu plus en détail les informations que nous pouvons y retrouver
Reprenons la capture d’écran précédente pour avoir un visuel.

¶ 1.1 - La colonne « AVAILABILITY »
Cette colonne indique si le planificateur peut ou non affecter des tâches aux nœuds.
- Active : signifie que le planificateur peut affecter des tâches sur le nœud
- Pause : signifie que le planificateur n'attribue pas de nouvelles tâches sur le nœud, mais que les tâches existantes continuent de s'exécuter
- Drain : signifie que le planificateur n'attribue pas de nouvelles tâches sur le nœud et que le planificateur arrête toutes les tâches existantes sur ce nœud pour les planifier sur un autre nœud disponible. Le nœud ne pourra alors pas recevoir de nouvelles tâches tant qu’il aura ce statut
¶ 1.2 - La colonne « MANAGER STATUS »
Cette colonne indique la colonne montre la participation des nœuds au cluster.
- Vide : signifie que le nœud est un « Worker » et qu’il ne participe pas aux décisions ainsi qu’au management du cluster
- Leader : signifie que le nœud est le « Manager » principal qui prend toutes les décisions de gestion et d'orchestration dans le cluster
- Reachable : signifie que le nœud est un « Manager » participant à la gestion du cluster ainsi qu’au quorum permettant d’élire le « leader ». Si le nœud « leader » devient indisponible, ce nœud peut être éligible comme nouveau leader
- Unavailable : signifie que le nœud est un « Manager » qui ne peut pas communiquer avec les autres « Managers ».
Si un « Manager » devient indisponible il est indispensable, soit d’ajouter un nouveau nœud en tant que « Manager » du cluster, soit promouvoir un « Worker » comme « Manager »
¶ 2 – Inspection des noeuds
De la même manière qu’il est possible d’inspecter, un conteneur, un volume, un réseau, etc. il est possible d’inspecter un nœud à l’aide de la commande « inspect ».
Pour cela, depuis un manager du cluster nous utiliserons cette commande :
docker node inspect "nom_du_noeud"
La sortie par défaut est comme toujours au format JSON.
Nous pourrons retrouver l’intégralité des informations concernant le nœud sélectionné telles que
- ID
- Hostname
- Son statut
- Son « availability »
- Les caractéristiques techniques (OS, ram, CPU, etc)
- Le ou les volumes
- Les réseaux et leurs types
- Les logs
- Les informations TLS et le certificat
- etc
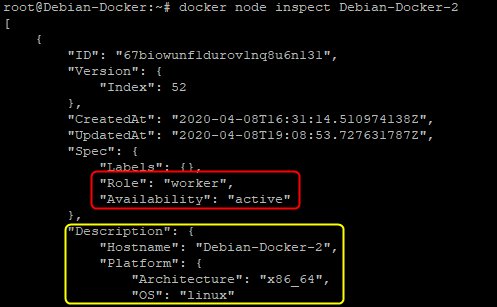
Le format JSON n’est pas forcément très lisible ou « user friendly », c’est pourquoi il existe une option à rajouter à la commande afin de pouvoir avoir une sortie un peu plus compréhensible.
Dans ce cas la commande sera :
docker node inspect "nom_du_noeud" --pretty
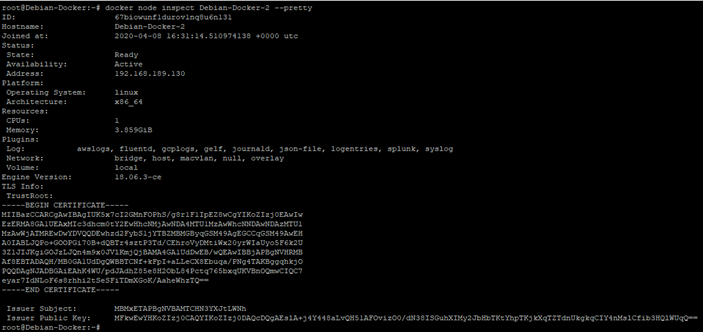
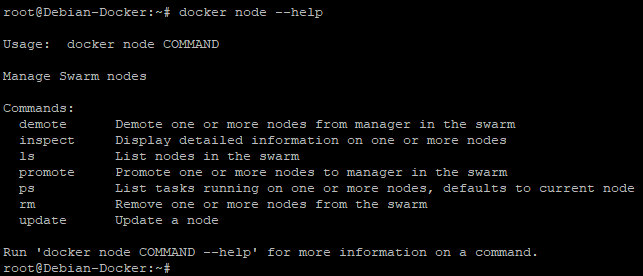
¶ 3 – Promouvoir et dépromouvoir un noeud
Nous l’avons vu précédemment la commande « docker node » permet d’interagir avec les différents nœuds du cluster.
Pour l’instant nous ne l’avons utilisé que pour lister les nœuds du cluster mais elle possède plusieurs options très intéressante.
Nous allons les afficher à l’aide de la commande
docker node --help
¶ 3.1 – Promouvoir un noeud
Parmi les différentes options nous en retrouvons une assez intéressante.
Elle permet de promouvoir un « Worker » en tant que « Manager ». A la différence de la commande que nous avions effectué précédemment pour AJOUTER un « Manager », ici nous allons promouvoir un nœud déjà présent dans le cluster comme « Manager ».
En effet, la commande que nous avions utilisé avec le token permettait d’ajouter des nœuds externe au cluster dans ce dernier et de définir leur rôle.
La commande pour promouvoir un nœud en tant que « Manager » est la suivante :
docker node promote "nom_du_noeud"
vérifions d’abord quels sont les « Workers » et les « Managers » de notre swarm

Maintenant nous allons promouvoir à l’aide de la commande « promote » un des « Workers » en « Manager »

Vérifions à nouveau la liste de nos nœuds et regardons la colonne « Manager Status »

Le nœud « Debian-Docker-2 » est effectivement passé « Manager » du cluster. Nous avons donc à présent 3 « Managers » et deux « Workers ».
¶ 3.2 – Dépromouvoir un noeud
De la même manière qu’il est possible de promouvoir un nœud en « Manager , il est possible de rétrograder un « Manager » en tant que simple « Worker ».
Pour cela nous utiliserons la commande :
docker node demote "nom_du_noeud"

On peut vérifier à nouveau la liste de nos nœuds ainsi que leur rôle dans le cluster

Le nœud « Debian-Docker-2 » est de redevenu à nouveau un « Worker ». Il ne fait plus parti de la liste des « Manager » du cluster.
¶ 4 – Sortir un nœud du cluster
Pour une raison X ou Y il est tout à fait possible de sortir un nœud du cluster.
Pour ce faire il faudra effectuer la sortie en deux étapes, sinon cela ne marchera pas et un message d’erreur sera visible.

La première étape consiste à se connecter au nœud qui est destiné à quitter le cluster puis d’effectuer la commande
docker swarm leave

Cette commande aura pour effet de positionner le statut de ce nœud à « down », ce qui est impératif pour le supprimer du cluster.
Une fois que l’on a effectué cette commande, nous pouvons revenir sur un de nos « Manager » et vérifier l’état de nos nœuds au sein du cluster.

Une fois le nœud à l’état « down », la deuxième étape pour le supprimer du cluster consiste à utiliser, depuis un « Manager » la commande suivante
docker node rm "nom_du_noeud"

Pour être sûr on peut à nouveau vérifier la liste des nœuds de notre cluster. Si tout s’est bien passé, le nœud « Debian-Docker-2 » ne devrai plus y être présent

Attention : une fois cette commande effectuée, le nœud ne fera plus parti du cluster. Pour le réintégrer au cluster il faudra obligatoirement réutiliser la commande utilisant le token pour rejoindre de nouveau le cluster.
Nous pouvons faire le test et l’ajouter de nouveau au cluster avec la commande « join »

Puis nous vérifions la liste depuis un des « Managers »

Ce que nous pouvons remarquer c’est que l’ajout du nœud au cluster fonctionne y compris pour un nœud qui a été supprimé du cluster mais également que si on réintègre ce même nœud dans le cluster il n’aura plus la même ID que précédemment.
ID avant la suppression :

¶ 5 – « Update » d’un nœud du cluster
Contrairement à ce que l’on pourrai penser, l’update d’un nœud ne signifie pas mettre à jour son kernel ou ses packages.
Il s’agit en réalité de mettre à jour les informations le concernant. La liste des options est visible avec cette commande :
docker node update --help
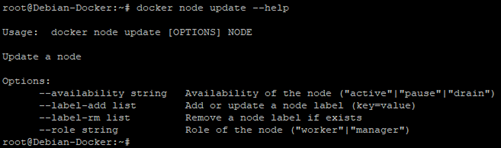
Nous pouvons donc modifier les informations concernant :
- les « availability » (ou disponibilités)
« active », « pause », « drain » dont nous avons parlé précédemment
- Les labels des nœuds
Les « Labels » des nœuds fournissent une méthode flexible d'organisation des nœuds. Vous pouvez également utiliser des « labels » dans les contraintes de service. Un « label » est donc une sorte d’étiquette permettant une sorte d’organisation concernant les fonctions d’un nœud. Il s’agit en réalité de Meta data qui lui sont ajoutées.
- Les rôles
« Worker » ou « Manager »
¶ 5.1 – « availability »
Actuellement dans notre lab il n’y a pas de services en place. Rien ne tourne à part le cluster lui-même.
Pour les besoins de la démonstration de la modification du statut dans la colonne « availability », nous allons mettre en place un service répliqué. Pour cela nous allons effectuer la commande suivante :
docker service create -p "8000:80" -d --replicas "5 nginx"

Vérifions l’état du service et sa réplication
docker service ps "nom_du_service"

Attention : cette partie sera expliquée plus en détail par la suite.
Nous avons donc actuellement un service répliqué sur l’ensemble des nœuds de notre cluster, y compris les deux « Managers » qui sont « Debian-Docker » et « Debian-Docker-5 ».
Cela est dû au fait que la disponibilité (« availability ») de chacun des nœuds est positionnée sur « Active ». Ils sont donc tous disponible pour héberger des services et des conteneurs.

Dans le cas où nous ne voulons pas que les « Managers » soient utilisés pour autre chose que pour la gestion du cluster il va nous falloir modifier l’état de la disponibilité. Pour cela nous allons la positionner à « drain », les rendant alors incompatible avec l’hébergement de services.
Commençons par reprendre depuis le début et par supprimer notre service.
docker service rm "nom_du_service"
Attention : la suppression du service n’est pas obligatoire mais je voulais reprendre depuis le début pour les besoins de la démonstration. Cela marche aussi sans supprimer le service. Tout sera arrêté sur le nœud ciblé et aucune nouvelle tâche ne pourra lui être affecté.
Nous somme de nouveau dans la configuration d’un lab composé seulement du cluster et de ses nœuds.
Modifions la disponibilité de notre leader
docker node update --availability drain "nom_du_noeud"
ou
docker node update --availability drain leader

Vérifions les nœuds du cluster

La disponibilité du leader est effectivement passée à « drain ».
Maintenant recommençons la création du service répliqué sur les 5 nœuds de notre cluster.

Puis vérifions l’état du service et sa réplication

Nous pouvons constater que le leader « Docker-Debian-5 » ne fait pas partie des nœuds hébergeant ce service.
Cependant nous remarquons également que le service a été répliqué 5 fois comme nous l’avons demandé lors de l’exécution de la commande car il se trouve deux fois sur le nœud « Docker-Debian-2 ».
¶ 5.2 – « Labels »
Comme indiqué précédemment, les « Labels » permettent d’organiser les nœuds en leur fournissant des informations supplémentaires, comme une sorte d’étiquette permettant d’organiser les nœuds en fonction d’informations précise.
Par exemple, imaginons que nous soyons en entreprise. Nous avons des hyperviseurs pour faire tourner nos nombreux serveurs et des baies SAN pour y effectuer les différents stockages des disques dur de nos serveurs virtuels.
Partons du principe que l’une de nos baies SAN soit full SSD tandis que l’autre soit full HDD et que nous avons décidé d’héberger les disques dur de nos hôtes Docker dans la baie full SSD. Dans ce cas à l’aide des « labels » il sera possible d’ajouter une étiqueté à l’hôte pour indiquer qu’il est dans la baie full SSD.
La commande à utiliser pour ajouter un « label » sera alors :
docker node update --label-add "le_label_souhaité" "nom_de_l’hôte"

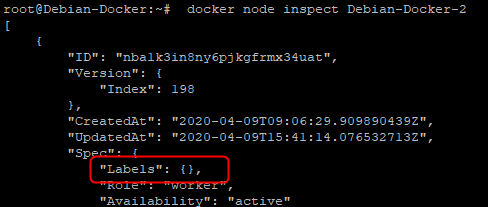
Une fois le « label » ajouté il sera visible dans les informations que l’on peut avoir lorsqu’on effectue un « inspect » sur un hôte
docker node inspect "nom_du_noeud"
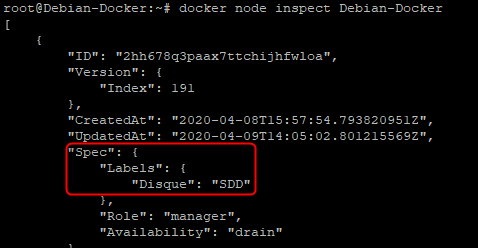
Le résultat est aussi possible avec l’option « --pretty » que nous avions évoqué tout à l’heure.

Attention : ceci est un exemple il est possible d’ajouter n’importe quel « label » souhaité et pas seulement concernant le type de disques durs utilisé. Par exemple :

Tout comme nous pouvons ajouter des « labels », nous pouvons les supprimer.
Dans ce cas la commande est celle-ci :
docker node update --label-rm "le_label_existant" "nom_de_l’hôte"
- Debian-Docker :

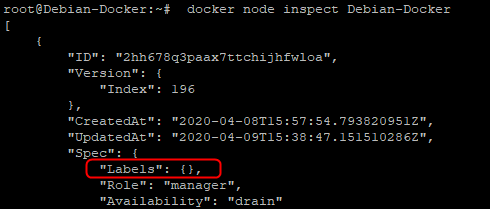
Attention : pour ce label il n’aura pas fallu mettre le nom complet mais s’arrêter à la première partie avant le « = ». Si j’avais mis en entier « Disque=SDD » ça n’aurai pas marché.
- Debian-Docker-2