![]()
¶ V – Les conteneurs Docker
¶ A – Créer ses conteneurs
¶ 1 – créer un conteneur
Si on reprend le principe du « Build Ship and Run » de docker, la dernière étape est le « run ».
Cela consiste à instancier les conteneur à partir des images. Cette partie de la documentation sera donc principalement montrer le fonctionnement de la commande « run »
Regardons les images à dispositions
Pour cet exemple nous allons utiliser l’image de Debian et créer (ou instancier) un conteneur à partir de celle-ci
docker run "image"

Le conteneur a été créé mais nous n’avons pas de visibilité dessus.
¶ 2 – lister les conteneurs actifs
Pour voir les différents conteneurs il faudra utiliser la commande
docker container ps

On remarque qu’il n’y a pas de conteneur en cours d’exécution dans la liste. Nous allons donc refaire la commande mais en lui rajoutant une option pour voir tous les conteneurs, peu importe leur état.
¶ 3 – lister tous les conteneurs
docker container ps --all

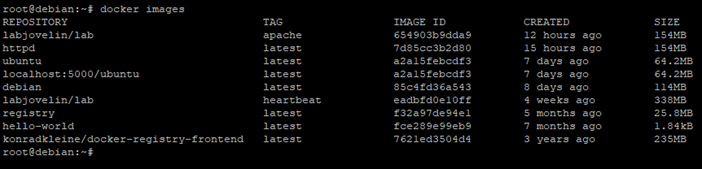
Cette fois-ci nous pouvons voir le conteneur ainsi que des informations telles que son Container ID, l’image utilisée, la commande qui a été passée par le conteneur, quand il a été créé son statut, le port et son nom (généré aléatoirement par docker)
On constate que le statut indique « exited »
Cela veut dire qu’il y a eu une activité qui s’est terminée et le conteneur s’est arrêté.
¶ 4 – Exécuter une commande au lancement du conteneur
Pourquoi s’est-il arrêté ? Pour rappel, un conteneur est par définition éphémère, c’est-à-dire qu’il va lancer une commande puis lorsque celle-ci est finie il s’arrête.
Dans cette exemple la commande qui a été lancée est celle ci

Nous pouvons changer la commande exécutée par le conteneur. Par exemple nous cela nous allons taper cette commande :
Docker run "image» «la_commande"

A nouveau on relance la commande pour consulter tous les conteneurs peu importe leur état.
docker container ps --all

On voit que le conteneur a été exécuté que notre commande l’a été aussi et qu’il est également avec un statut « exited » indiquant que le conteneur est lui aussi arrêté.
La commande « run » créée donc un conteneur qui lui exécute une commande et qui s’arrête lorsque celle-ci est terminée.
¶ 5 – créer un conteneur et interagir avec lui
Que faire si l’on souhaite travailler dans le conteneur ? Dans ce cas il faudra utiliser des options lors de l’utilisation de la commande « run ».
Pour voir la liste des options taper
docker run --help
Attention : la capture d’écran ne correspond pas à l’intégralité des options. Elles sont très nombreuses.
L’une des options qui nous intéressent est « -i » ou « --interactive » (ce sont les mêmes).
En effet cette option permet de créer le conteneur en mode « interactif » et de faire en sorte qu’il ne s’arrête pas à la fin de l’exécution de sa commande.
L’autre option sera « -t » car il s’agit d’une option qui permet d’utiliser la commande « tty ».
Pour rappel, « tty » est une commande Unix qui affiche sur la sortie standard (l’écran) le nom du fichier connecté sur l'entrée standard(le conteneur), ce qui permet en réalité d’avoir un terminal.
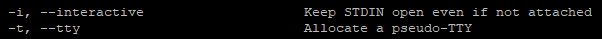
Cependant pour pouvoir interagir avec lui l’idéal serait d’avoir un « Shell ». Pour cela nous passerons la commande « /bin/bash » lors de la création du conteneur pour qu’il l’exécute.
La commande à saisir sera alors celle-ci :
docker run -i -t "image" /bin/bash
Ou
docker run -it "image" /bin/bash

Une fois la commande passé, nous pouvoir voir que l’utilisateur « root » n’est plus celui de la machine hôte mais bien celui du conteneur.
Que se passerait-il si on n’utilisait pas l’option « -t » ? on aura quand même un « Shell » car la commande « /bin/bash » serait correctement passée mais sans l’affichage du nom du conteneur auquel nous sommes connecté, ce qui n’est pas très pratique pour travailler surtout si l’on se trompe d’image.

Attention : cela fonctionne seulement si l’image permet d’utiliser ces options. Tous les conteneurs ne peuvent pas être interactif ou ne permettent pas d’avoir un terminal.
¶ 6 – effectuer des modifications dans le conteneur
Une fois que l’on possède un terminal et que l’on peut interagir avec le conteneur nous pourrons par exemple nous déplacer dedans, créer un répertoire, etc.
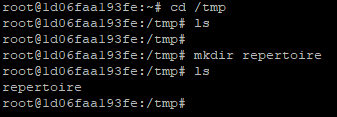
Evidemment, ceci n’est qu’à titre d’exemple, l’image que nous avons utilisé est celle d’un OS nous pourrions donc effectuer n’importe quelle commande que cet OS permet de faire.
Si l’image était cette d’une application les commandes passées ne seraient pas nécessairement les mêmes.
¶ 7 – sortir d’un conteneur
Pour sortir du conteneur, il suffira de taper la commande « exit »
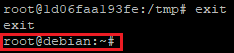
On est correctement sorti du conteneur et de retour sur la machine hôte.
Effectuons à nouveau la commande permettant d’afficher les conteneurs en activité
docker container ps

Aucun conteneur n’est en activité
Lançons la commande permettant de voir tous les conteneurs
docker container ps --all

Cette fois-ci le conteneur est visible mais on remarque que son statut est en « exited », c’est-à-dire qu’il est arrêté.
Cela vient du fait que nous avons utilisé la commande « exit » pour sortir du conteneur.
En effet, cette commande a arrêté le conteneur au moment où nous en sommes sorti.
¶ 8 – sortir d’un conteneur sans l’arrêter
Nous allons de nouveau lancer la commande pour créer un conteneur
docker run -it "image" /bin/bash
Puis nous allons retourner dans « /tmp » et vérifier si le répertoire que nous avons créé est présent

Il ne l’est pas. En effet la commande « run » créée un NOUVEAU conteneur et on peut voir que son ID n’est pas la même, il est donc logique que le répertoire que nous avons créé ne soit pas présent.

A nouveau nous allons créer un répertoire dans ce deuxième conteneur
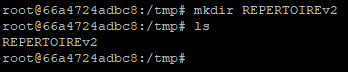
Cette fois-ci, nous voulons quitter le conteneur SANS l’arrêter, pour cela il faudra faire la combinaison de touche « control + p + q »
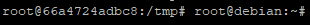
Affichons la liste des conteneur en activité
docker container ps

Le conteneur est effectivement visible dans la liste et possède le statut « up » indiquant qu’il tourne.
¶ 9 – Entrer dans un conteneur qui tourne
Il est parfaitement possible de retrouver un terminal sur un conteneur qui tourne.
Pour cela il faudra utiliser la commande suivante :
docker container attach "ID_du_conteneur"

Ou
docker container attach "nom_du_conteneur"

On constate d’ailleurs qu’une fois le terminal récupéré sur le conteneur nous sommes exactement au même endroit dans l’arborescence que lorsque nous sommes sorti du conteneur
Vérifions si le répertoire créé précédemment est bien présent

A nouveau quittons le conteneur avec la commande « exit » pour quitter et arrêter le conteneur.
¶ 10 – Démarrer un conteneur arrêté
Il est possible de démarrer un conteneur qui arrêté à l’aide de la commande « start »
docker start "ID_du_conteneur"

OU
docker start "nom_du_conteneur"

Vérifions si le conteneur est correctement démarré
docker container ps

¶ 11 – Arrêter un conteneur
De la même manière qu’il est possible de démarrer un conteneur arrêté, il sera possible d’arrêter un conteneur démarré.
docker stop "ID_du_conteneur"

OU
docker start "nom_du_conteneur"

Vérifions si le conteneur est correctement arrêté

¶ 12 – utiliser un conteneur en tant que daemon
Parmi les nombreuses options de la commande « run », l’une d’entre elles permet d’utiliser un conteneur sous forme de « daemon Linux ». C’est-à-dire que le conteneur tournera en tâche de fond et sera visible dans la liste des processus de l’OS.
Cette option est particulièrement intéressante lors d’utilisation d’images de serveurs.
Attention : Pour rappel, un daemon désigne un type de programme informatique, un processus ou un ensemble de processus qui s'exécute en arrière-plan plutôt que sous le contrôle direct d'un utilisateur.
L’option à utiliser est « -d »

docker run -d "image"
Grâce à cette option, il ne sera pas utile de lancer l’image du serveur en mode interactif avec un terminal et d’en sortir.
Le conteneur sera donc « daemonisé » directement
Prenons l’exemple de « Nginx » qui est un serveur Web.

Si on affiche à nouveau la liste des conteneur en cours d’exécution on retrouve le serveur Nginx

¶ 13 – créer un conteneur et lui affecter un nom
Comme on a pu le voir précédemment, tous les conteneurs possèdent un nom ainsi qu’une ID.
Le nom des conteneur est généré aléatoirement par docker mais il est possible d’utiliser l’option « --name » pour nommer le conteneur lors de sa création.
docker run --name «nom_souhaité» "image» «commande"

Vérification la liste des conteneurs

¶ 14 – Supprimer un conteneur
Pour supprimer un conteneur l’option à utiliser sera « rm »
docker container rm "ID_du_conteneur"

ou
docker container rm "nom_du_conteneur"

Il est possible de forcer la suppression d’un conteneur en utilisant la commande suivante
docker container rm -f "nom_du_conteneur" ou "ID_du_conteneur"
¶ B – Mappage de ports
¶ 1 - Explication
Prenons l’exemple d’un conteneur qui permette d’avoir un serveur web comme Nginx.
Par défaut, un serveur web écoute sur le port 80. Comment pouvons-nous accéder à ce conteneur si nous en avons plusieurs qui servent de serveur Web et qui écoutent tous sur le port 80 ?

Cela risque d’être compliqué à moins de travailler sur l’adresse IP de chaque conteneur. Le problème est que l’adresse IP des conteneurs n’est pas accessible de l’extérieur. En effet elle n’est accessible QUE depuis l’hôte.
La solution sera donc d’effectuer un mappage des ports de la machine hôte vers le port 80 des conteneurs, autrement dit mettre en place du NAT.
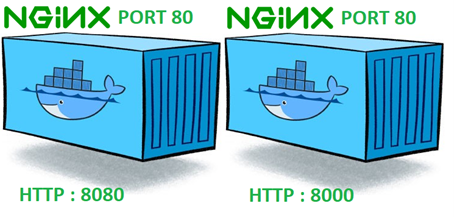
Par exemple, le premier serveur Web Nginx se verra associer le port 8080 tandis que le deuxième se verra associer le port 8000.
Pour se connecter à l’un ou l’autre des serveurs Web, il faudra se connecter à l’hôte qui contient les conteneurs via son adresse IP publique ou privée en spécifiant le port qui a été mappé, ici 8080 ou 8000.
¶ 2 – Mise en place du mappage de port
Le mappage de port se fera lors de la création du conteneur avec la commande « run »
docker run -d -p "port_mappé_de_l’hote:port_ciblé_sur_le_conteneur" --name "nom_du_conteneur" "image"


Vérification des conteneurs qui tournent

¶ 3 – accès au conteneur depuis l’extérieur
Comme indiqué précédemment, pour accéder aux conteneurs il faudra passer par l’adresse IP de la machine hôte.
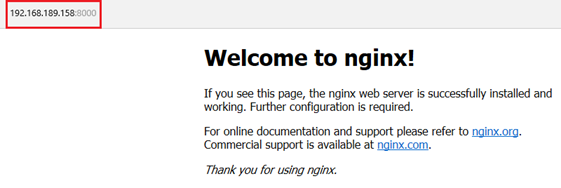
Comme nous avons créé des serveurs Web et mappé des ports il suffira donc d’entrer dans un navigateur Web l’adresse IP de l’hôte et de préciser le port correspondant au conteneur qui nous intéresse.
- Srb_web_01
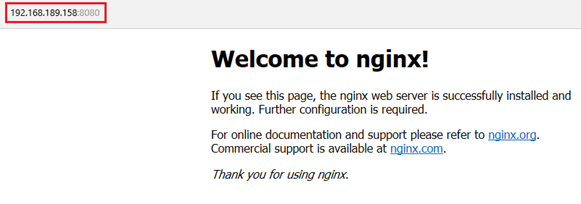
- Srb_web_02
¶ C – Gestion des volumes de donnees
¶ 1 – Qu’est-ce qu’un volume de données
Comme il a déjà été indiqué un conteneur par définition est voué à être éphémère.
On va créer un conteneur lorsqu’on en aura besoin et uniquement lorsqu’on en aura besoin.
Une fois son objectif rempli on ne le conserve pas ou on ne le gardera pas actif, bien sûr comme dans toute infrastructure de production il peut y avoir des exceptions ou des cas particuliers.
Lors de la création d’un conteneur son contenu est également créé à chaque fois, ce qui n’est pas une bonne solution en production si l’on a besoin de conteneur bien spécifique comme par exemple un serveur Web dans lequel on aura ajouté des modifications. Il faudra refaire les modifications à chaque fois qu’un nouveau conteneur sera créé.
Docker propose le concept de « volume de données ». Cette solution permet de stocker les données dans un répertoire spécifique du serveur hôte par exemple plutôt que dans le système de fichiers par défaut du conteneur.
Autrement dit, docker permet d’effectuer un mappage de volume de données entre un conteneur et un stockage externe.
Dans cette documentation nous allons effectuer le mappage des données sur l’hôte mais il existe des solutions qui permettent de le faire sur des systèmes de fichiers extérieurs (SAN, NAS, etc.)
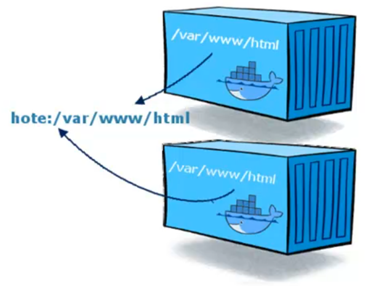
Ce stockage externe appelé « volume de données » permet de rendre les données indépendantes de la vie du conteneur.
Le volume permet également de partager ces données entre plusieurs conteneurs.
Le « volume de données » dans Docker propose ces fonctionnalités :
- le volume est initialisé à la création du conteneur. Si l’image de base contient déjà des données à l’initialisation du volume, alors elles seront copiées dans le volume.
- un volume de données peut être partagé ou réutilisé par plusieurs conteneurs.
- les changements dans le volume de données sont appliqués immédiatement.
- le volume de données est persistant même si le conteneur lui-même est supprimé.
¶ 2 – Création d’un volume de données
¶ 2.1 – création d’un conteneur sans mappage de volume
Afin de bien faire la différence entre un conteneur qui n’ aurait pas de mappage de volume et un autre qui aurait un volume mappé, nous allons commencer par créer deux conteneurs avec le serveur Web Nginx sans effectuer de mappage de volume et afficher sa page d’accueil.
Comme vu précédemment, il faudra effectuer un mappage de port à l’aide de la commande est la suivante
docker run -d -p "port_mappé_de_l’hote:port_ciblé_sur_le_conteneur" --name "nom_du_conteneur" "image"
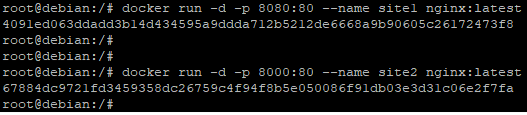
Pour l’instant nous avons donc deux conteneur en mode daemon sans mappage de volume qui sont accessibles via l’adresse IP de l’hôte avec des ports spécifiques :
Site1 : 192.168.189.158 :8080
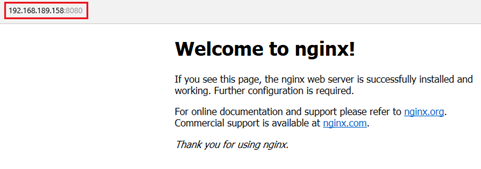
Site1 : 192.168.189.158 :8000
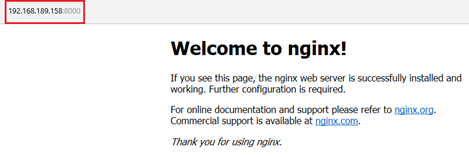
La page d’accueil de chacun des sites est actuellement celle qui se trouve dans les fichiers de configuration dans leur conteneur respectif.
Si on fait des modification puis qu’on supprime le conteneur pour en créer un autre avec exactement la même commande « docker run », les modifications ne seront plus présentes puis qu’il s’agira d’un nouveau conteneur.
A l’aide des commandes précédemment citées nous allons arrêter ces deux conteneurs et les supprimer.
¶ 2.2 – création d’un conteneur Avec mappage de volume
Puis nous allons créer deux nouveaux conteneurs mais cette fois-ci avec un mappage de volume.
Un volume de données peut être ajouté de deux manières à un conteneur, soit manuellement à la création du conteneur soit avec le fichier de construction « Dockerfile ».
Nous allons voir comment effectuer manuellement un volume de données.
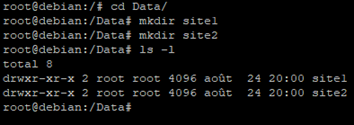
Pour commencer nous allons créer un répertoire que nous appellerons « Data » à la racine de l’hôte.
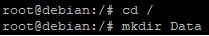
Nous allons en suite entrer dans ce répertoire pour y créer deux autres répertoires : « site1 » et « site2 » qui seront utilisés pour le mappage de volume.
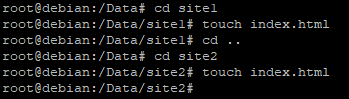
A l’intérieur de chacun des répertoire nous allons créer un fichier « index.html »
Nous allons éditer ces deux fichier pour qu’ils contiennent ceci :
- Site1 : « ceci est le premier conteneur »

- Site2 : « ceci est le deuxième conteneur »
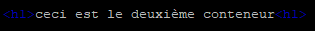
La partie « stockage externe » étant prête il ne reste plus qu’à créer les deux nouveau conteneurs incluant cette fois dans la commande l’option de mappage de volume
docker run -d --name "nom_du_conteneur" -p "port_mappé_de_l’hote:port_ciblé_sur_le_conteneur" -v "chemin_du_stockage_externe:chemin_dans_le_conteneur" "image"

Attention : Pour information, les sites du serveur Nginx sont stockées par défaut dans « /usr/share/nginx/html »
Le mappage est effectué, si tout s’est bien passé, nous devrions pouvoir nous connecter sur chacun des deux sites et voir le contenu des fichiers « intex.html » que nous avons précédemment créés et qui correspondent à chacun des sites
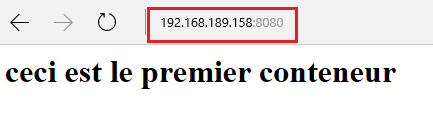
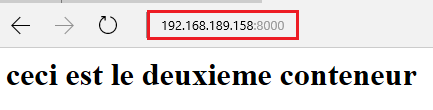
Ce que cela veut dire, c’est que nous avons donc deux conteneurs différents proposant un service Web dont les données ne sont plus stockées dans le conteneur lui-même mais directement dans un stockage externe qui est ici notre machine hôte.
Il est possible de modifier le contenu des fichiers « index.html » et d’afficher en direct les modifications
- Site1 :


- Site2 :
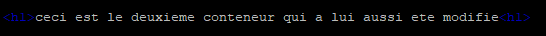

¶ 3 – Création de nouveaux conteneurs ciblant les volumes existant
Nous l’avons évoqué, le mappage de volume permet de rendre les données indépendantes de la vie du conteneur.
Pour en faire la démonstration nous allons créer de nouveaux conteneurs appelés sites3 et site4 qui utiliserons les deux répertoire qui servent de stockage que nous avons créé précédemment.
Avant de commencer et de les créer, nous allons vérifier la liste des conteneurs existant

Puis nous allons arrêter les deux conteneurs que nous avons utilisé pour l’exemple précédant avec la commande « stop »

Nous pouvons vérifier s’il sont bien arrêtés

Puis en utilisant l’option « rm » nous allons les supprimer.
Maintenant que nous n’avons plus aucun conteneurs, nous allons créer les deux nouveaux appelés site3 et site4 en mappant les répertoires « site1 » et « site2 ».
Le conteneur « site3 » sera mappé avec le répertoire « site1 » et la redirection de port se fera sur le 7070 et le conteneur « site4 » sera quant à lui mappé avec le répertoire « site2 » et la redirection de port se fera sur le 7000.

A nouveau il suffira de se connecter à l’adresse IP de notre machine hôte en spécifiant les ports 7070 et 7000 pour pouvoir afficher le même résultat qu’avec les conteneurs supprimés.


Le mappage fonctionne parfaitement et les données sont totalement indépendantes des conteneurs.
¶ D – Liaison inter conteneurs - Link
¶ 1 – Qu’Est-ce qu’une liaison inter conteneurs ?
A présent nous le savons, les conteneurs sont par définition éphémères mais aussi et surtout isolés les uns des autres et même de l’hôte. Il sera toutefois possible de faire en sorte que des conteneurs puissent interagir ensemble en cas de besoin à l’aide d’une « liaison inter conteneurs ».
En effet, une « liaison inter conteneurs » est tout simplement le fait de lier des conteneurs entre eux pour qu’ils puissent « travailler » ensemble.
Prenons par exemple un conteneur de type Web contenant un serveur Web qui aurai besoin d’une base de données ou de tout autre chose pour fonctionner.
Il suffira de créer les conteneurs avec une « liaison » ou un « link » pour qu’ils puissent être en relation l’un avec l’autre.
¶ 2 – Mettre en place une liaison inter conteneurs
¶ 2.1 – création de la liaison
On a déjà vu qu’à la création d’un conteneur, celui-ci reçoit un nom qui lui est automatiquement attribué par docker à moins d’en spécifier nous-même le nom.
Pour établir des liens entre les conteneurs, Docker s'appuie sur leur nom, ce qui implique que lors de la création d’un conteneur son nom à une importance.
Les liaisons vont permettre aux conteneurs de transférer en toute sécurité des informations.
Lorsqu'on configure une liaison on va créer un canal entre un conteneur source et un conteneur de destination.
Le destinataire pourra alors accéder à des données sur la source.
Pour créer une liaison entre des conteneurs, on utilisera l’option « --link » de la commande « run »
Pour commencer nous allons récupérer deux nouvelles images afin de faire une liaison entre elles.

Cette image contient une Web App « hello world » codée en python

Cette image contient l’image « PostgreSQL »
Ce que l’on souhaite faire ici , c’est lier les conteneurs de ces deux images. C’est-à-dire que l’application web utilise la base de données de l’autre conteneur.
Actuellement aucun conteneur créé à partir de ces images n’est actif sur notre machine hôte.
Nous allons donc commencer par en créer un qui sera le conteneur « source », autrement dit celui qui proposera une base de données.
Attention : il n’est pas utile d’en créer un si vous avez déjà des conteneurs existant et si vous voulez en utiliser un pour le lier à un nouveau conteneur. Il suffira simplement de faire la liaison entre le conteneur existant et le nouveau lors de sa création.
docker run -d --name "nom_du_conteneur" "image"

Maintenant que nous avons notre conteneur de base de données il ne reste plus qu’à effectuer la liaison entre celui-ci et un nouveau conteneur lors de sa création.
Pour cela il faudra utiliser la commande suivante :
docker run -d -P --name "nom_du_conteneur" --link "nom_du_conteneur_source" "image" "applicaton_à_lancer"

La liaison entre les conteneur est mise en place.
Attention : Lorsque nous avons créé le conteneur l'option « -P » a été utilisé pour mapper automatiquement le port réseau interne vers un port aléatoire de notre machine hôte. Lorsqu'on exécute « docker ps -a », nous voyons que le port 32768 de la machine hôte a été mappé avec le port 5000 du conteneur. Nous aurions pu également spécifier nous-même le mappage de port avec l’option « -p » comme vu précédemment

¶ 2.2 – Vérification de la liaison
Il est possible de vérifier que la liaison entre les conteneurs a correctement fonctionner.
Pour cela nous pourrons utiliser la commande « docker exec » qui permet d’exécuter une commande dans un conteneur qui tourne.
docker exec "commande"
Nous allons vérifier le contenu du fichier « /etc/hosts » de notre conteneur Webapp.
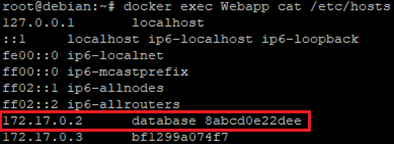
On retrouve dans ce fichier l’adresse IP, le nom ainsi que l’ID du conteneur database.
Nous pourrons également utiliser la commande « docker inspect » et chercher les liaisons d’un conteneur précis pour vérifier s’il en possède.
Pour cela il faudra utiliser la commande suivante :
docker inspect -f "{{ .HostConfig.Links }}" "nom_du_conteneur_de_destination"

Le résultat indique que la base de données utilisée se trouve sur le conteneur « database » et s’appelle « Webapp/database »
Nous pourrons également vérifier les variables d’environnement utilisées par le conteneur Webapp.
Pour cela nous utiliserons à nouveau la commande « docker exec »
docker exec "nom_du_conteneur" env
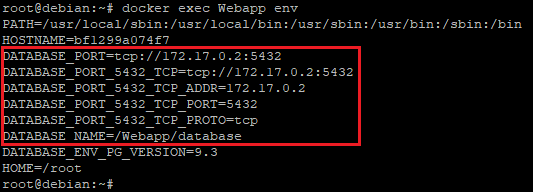
On retrouvera ici toutes les informations nécessaires à l’utilisation de la base de données qui se trouve dans le conteneur « database » :
- L’adresse IP du conteneur (172.17.0.2)
- Le port utilisé (5432)
- Le type de protocole (TCP)
- Le nom de la base de données (/Webapp/database)
La liaison entre les conteneurs Webapp et database est donc opérationnelle.