¶ II – Introduction aux containers
¶ A - Comprendre les containers sous Linux
¶ 1 – Les machines virtuelles
¶ 1.1 – Qu’est ce qu’une machine virtuelle
La virtualisation consiste à exécuter sur une machine hôte (dans un environnement isolé) des systèmes d'exploitation.
On parle alors de virtualisation système. Ces ordinateurs virtuels sont appelés « machine virtuelles » ou « Virtual machines » (VM).
Une machine virtuelle est donc une machine physique représentée virtuellement qui, à l'instar d'un ordinateur physique, exécute un système d'exploitation et des applications.
Elle se compose d'un ensemble de fichiers de spécification et de configuration et est secondée par les ressources physiques d'un hôte physique.
Chaque machine virtuelle dispose de périphériques virtuels qui fournissent la même fonctionnalité que le matériel physique, comme le CPU, la RAM, les disques, les cartes réseau, etc.
¶ 1.2 – L’infrastructure de virtualisation
Une infrastructure de virtualisation se présente généralement comme ceci :
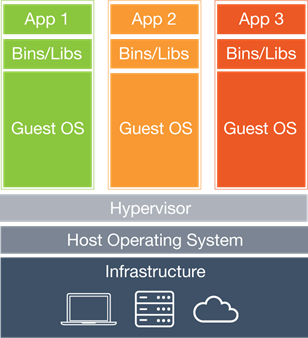
Dans ce schéma l’infrastructure représente l’hôte physique permettant la création de machine virtuelles.
Il peut être de différentes sortes telles que :
- Le cloud (on parle ici d’instanciation plutôt que création de machine virtuelle)
- Un ou plusieurs serveurs de virtualisation
- Des PC ayant un outil de virtualisation
L’hôte physique possède son propre système d’exploitation ainsi qu’un outil de virtualisation appelé « hyperviseur » qui lui va permettre de créer des machines virtuelles.
Ces deux couches sont souvent réunies en une seule, tout dépend du type « d’hyperviseur » utilisé pour effectuer la virtualisation mais ce n’est pas le propos de ce document et nous ne le détaillerons pas ici.
Dans cette machine virtuelle, tout comme pour une machine physique, on va alors installer un système d’exploitation qui possèdera ses propres ressources allouées (CPU, mémoire, stockage, etc.). On aura donc un OS par machine virtuelle.
Ce qui est très important de comprendre c’est que dans une machine virtuelle on peut distinguer deux parties :
- L’espace noyau
- L’espace utilisateur
L’espace noyaux sera composé du système d’exploitation invité qui aura été utilisé pour créer la machine virtuelle.
Il est complet et identique à celui qui aurai pu être installé sur une machine physique.
Il sera donc possible d’utiliser n’importe quel OS lors de la création d’une machine virtuelle (ex : Windows 10, Windows server 2016, Debian 9, CentOS, etc. en fonction de la machine à créer).
L’espace utilisateur quant à lui va comprendre tout ce qui concerne le bureau, les applications par défaut de l’OS ou celles rajoutées par la suite, les binaires et librairies, etc. permettant à l’utilisateur final de travailler comme sur une machine physique.
¶ 2 – Les conteneurs
¶ 2.1 – Qu’est ce qu’un conteneur
Un conteneur consiste en un environnement d'exécution complet : une application, plus toutes ses dépendances, ses bibliothèques et autres fichiers binaires, ainsi que les fichiers de configuration nécessaires pour l'exécuter, regroupés dans un seul package. Ils peuvent être utilisés pour exécuter des applications Linux ou Windows.
Les conteneurs sont donc proches des machines virtuelles mais présentent l’avantage de se partager le même noyau de système d’exploitation et d’isoler les processus de l’application du reste du système tandis que la virtualisation consiste à exécuter de nombreux systèmes d’exploitation sur un seul et même système hôte.
Pour faire simple, plutôt que de virtualiser le hardware comme dans le cas d’une machine virtuelle, le container virtualise le système d’exploitation. Un conteneur consomme donc moins de ressources système qu’une machine virtuelle.
¶ 2.2 – L’infrastructure de virtualisation
Une infrastructure de conteneurisation se présente généralement comme ceci :
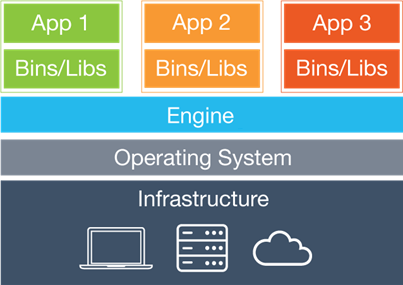
Dans ce schéma on retrouve un modèle à peu près similaire à celui des machines virtuelles mais toutefois avec une différence de taille.
L’infrastructure représente l’hôte physique permettant la création de machine virtuelles.
Il peut être de différentes sortes telles que :
- Le cloud
- Un ou plusieurs serveurs proposants de la conteneurisation
- Des PC ayant un outil de conteneurisation
Sur cet hôte un système d’exploitation sera installé tel que Windows ou Linux (pour cette documentation il s’agira de Linux).
Dans ce système d’exploitation un moteur de conteneurisation sera installé, ici ce sera « Docker Engine »
Le moteur est une application qui va permettre la création et la gestion des conteneurs.
Contrairement à la virtualisation, la conteneurisation va déployer et installer uniquement l’espace utilisateur.
En effet l’espace noyau ne sera pas redéployé puis qu’il s’agit de celui du système d’exploitation de l’hôte.
Les conteneurs vont donc se partager le noyau du système d’exploitation de l’hôte.
Si l’on reprend le schéma ci -dessus, les trois applications « APP1 », « APP2 » et « APP3 » ainsi que leurs binaires et librairies sont totalement isolées les unes des autres du fait qu’elles soient dans des espace utilisateurs différents et vont donc se partager le noyau du système d’exploitation présent dans l’infrastructure.
Elles vont également utiliser le matériel physique de l’infrastructure en direct comme si elles étaient directement installées sur l’hôte physique, à part pour les cartes réseau où une virtualisation sera faite.
Il n’y a donc pas de virtualisation à proprement parler comme pour des machines virtuelles ce qui rend les conteneurs très légers et rapide à utiliser puisqu’il n’y a pas de système d’exploitation à démarrer.
Attention : il faut savoir que tous les modèles de conteneurs sous Linux n’utilisent pas forcément de moteur de conteneurisation contrairement à « Docker »
¶ 3 – Les types de conteneurs Linux
Il existe deux types de conteneurs :
- Les conteneurs de type système d’exploitation
- Les conteneurs de type applicatif
Les conteneurs de type système d’exploitation vont généralement être utilisés pour pouvoir installer nos propres applications ou des applications bien spécifiques nécessitant un système d’exploitation bien particulier.
Par exemple dans un environnement entièrement Linux, il sera possible de créer un conteneur avec un OS Windows pour y installer et lancer une application propre à Windows dont on aura besoin.
Les conteneurs de type applicatif vont être utilisés pour déployer une application bien précise et seulement cette application.
En effet, le conteneur ne contiendra que cette application ainsi que les différents éléments dont elle a besoin pour fonctionner.
Dans ce type de conteneur, l’application est déjà installée et configurée. Il ne restera plus qu’à l’instancier.
Attention : pour information « Docker » est un système de conteneurisation plutôt orienté applicatif.
Il existe plusieurs solutions de conteneur pour Linux :
- rkt
- Docker
- LXC
- OpenVZ

Attention : nous n’allons pas détailler les possibilités et les différences de ces solutions dans cette documentation. Pour plus d’informations je vous invite à vous renseigner sur les sites officiels de ces solutions.
¶ 4 – Les Namespaces
Un « Namespace » ou « espace de noms » est une fonctionnalité du noyau Linux qui a pour but d’isoler.
En effet, cela permet de regrouper des ressources aux sein d’un contexte distinct et isolé de l’hôte ou des autres contextes.
Nous pouvons citer en exemple les isolations suivantes :
- Les processus (Process Namespace)
- La carte réseau (network Namespace)
- Le file système (Mount Namespace)
- La gestion des noms d’hôte et des noms de domaine (UTS Namespace)
- La gestion de la communication entre les processus (IPC Namespace - InterProcess Communication)
- La gestion des utilisateurs y compris de root, qui sera différent de celui de l’hôte (User Namespace)
L’utilisation de « Namespace » restreint pour un processus donné la visibilité des autres processus se trouvant en dehors de son propre contexte d’exécution.
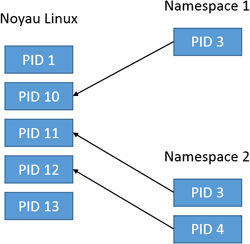
Un conteneur aura donc :
- Ses propre processus (Process Namespace)
- Sa propre carte réseau (network Namespace)
- Son propre file système (Mount Namespace)
- Sa propre gestion des noms d’hôte et des noms de domaine (UTS Namespace)
- Sa propre gestion de communication entre les processus (IPC Namespace - InterProcess Communication)
- Sa propre gestion des utilisateurs y compris de root mais ce dernier sera différent de celui de l’hôte (User Namespace)
Attention : les « espaces de noms » ne limitent pas l'accès aux ressources physiques telles que le processeur, la mémoire et le disque. Cet accès est mesuré et limité par une fonctionnalité du noyau appelée « cgroups ».
¶ 5 – Les groupes de contrôle « Cgroup »
Les « Namespaces » permettent de cloisonner les processus mais il est important également de cloisonner les ressources (RAM, réseau, stockage, etc.). C’est là que les « Cgroups » interviennent.
En effet, ils permettent de créer des groupes de ressources auxquels sont affecté des ressources matérielles ainsi que des ensembles de processus.
Il sera possible de :
- Contrôler les ressources
- Effectuer des allocations, prioritisassions et interdictions
- Faire de la surveillance et des mesures des ressources consommées
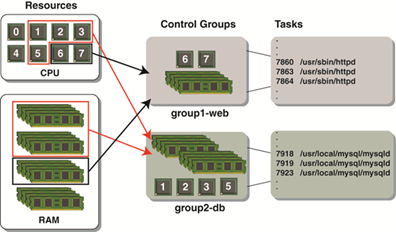
Attention : les « Namespaces » et les « Cgroups » travaillent ensemble mais sont des technologies bien distinctes du noyau Linux et indépendante l’une de l’autre.
¶ B – L'écosystème Docker
¶ 1 – Build, Ship and Run selon Docker
- Build
Le « Build » va consister à développer des applications dans n’importe quel type de langage ou de Framework et de les construire dans le but d’en faire des conteneurs

- Ship
Le « Ship » consiste à « Dockeriser » les applications construites précédemment ainsi que leurs dépendances.
Cela permettra de pouvoir les déplacer n’importe où (d’un serveur à un autre serveur, dans le Cloud, etc.) sans prendre de risque de les « casser » puisque le contenu n’est pas touché ou modifié.

- Run
Le « Run » consiste à exécuter et instancier les applications conteneurisées précédemment créées et déplacées aux endroits voulus avec par exemple de la très haute disponibilité, sans aucun « downtime », etc.

¶ 2 – Architecture de Docker
¶ 2.1 – Docker Engine
Docker Engine est une application « client-serveur » avec les composants principaux suivants :
- Un serveur Docker Daemon sous forme de processus « dockerd ».
- Une REST API qui spécifie les interfaces que les programmes peuvent utiliser pour communiquer avec le daemon et lui indiquer quoi faire.
- Un client sous forme d’interface en ligne de commande (CLI) dont la commande permettant d’effectuer des actions est « docker + le nom de l’action ».
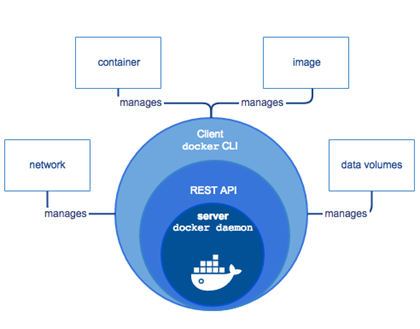
¶ 2.2 – L’architecture détaillée de Docker
Comme indiqué précédemment, Docker utilise une architecture de type « client-serveur ».
Le client Docker parle au daemon Docker qui lui se charge de la construction, de l'exécution et de la distribution des conteneurs Docker.
Le client et le daemon peuvent s'exécuter sur le même système mais il est également possible de connecter un client Docker à un daemon Docker distant.
Le client et le daemon Docker communiquent à l'aide d'une API REST, via des sockets UNIX ou une interface réseau.
Si l’on regarde un peu plus en détail l’architecture, nous pouvons distinguer trois éléments principaux qui sont le client, l’hôte sur lequel se trouve le daemon Docker et les registres
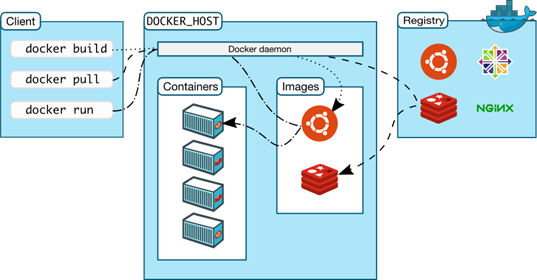
Nous pouvons également constater deux éléments se trouvant dans l’hôte hébergeant le daemon Docker qui sont les images et les conteneurs
- Docker daemon
Le daemon Docker (dockerd) écoute les requêtes de l'API Docker et gère les objets Docker tels que les images, les conteneurs, les réseaux et les volumes. Un démon peut également communiquer avec d'autres démons pour gérer les services Docker. C’est lui qui se chargera de l’instanciation des images en conteneurs.
- Docker client
Le client Docker est le moyen principal pour interagir avec Docker.
Lorsque vous utilisez des commandes telles que l'exécution de docker, le client envoie ces commandes à dockerd qui les exécute.
L’utilisation du client se fait en ligne de commande (CLI) et en tapant « docker + le nom de l’action.
Le client utilise l’API REST pour contrôler et/ou interagir avec le daemon Docker, ceci par le biais de scripts ou de commandes directes. De ce fait, tout ce que le client peut faire alors l’API peut le faire également.
L’API REST est une API HTTP, il sera d’ailleurs possible de développer des applications sur lesquelles on pourra contrôler le daemon.
De plus, le client Docker peut communiquer avec plusieurs démons.
- Images
Une « image » est un modèle en lecture seule qui sera utilisée pour créer un conteneur.
Elles utilisent un système de fichier appelé « union.fs » qui va permettre de créer des images en couches, c’est-à-dire qu’ il est possible de créer une image basée sur une autre image avec une personnalisation supplémentaire.
Prenons l’exemple suivant :
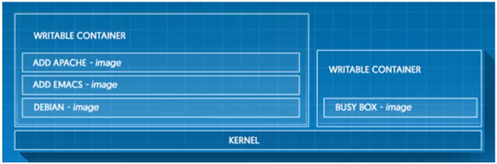
A partir d’une image de base, ici Debian, nous voulons installer une application appelée « EMACS ».
Il nous faudra simplement utiliser l’image de Debian sur laquelle nous rajouterons une nouvelle couche par le biais de l’image de l’application « EMACS » et uniquement celle de l’application. Il ne sera pas nécessaire d’utiliser un OS + l’application mais seulement l’application. En effet la couche de l’application viendra se superposer à celle de Debian, de ce fait rajouter un OS dans la couche comprenant l’application n’est pas utile.
Une fois que l’application « EMACS » est installée nous aurons besoin d’Apache, dans ce cas nous il suffira d’ajouter Apache « par-dessus » de la même façon que pour l’application « EMACS ».
Nous aurons donc une image en trois couches qui une fois instanciée permettra de créer un conteneur contenant ces éléments, qui lui sera en lecture écriture.
L’avantage de ce système en couches est que l’on peut revenir dans les différentes couches si besoin.
Il faut savoir qu’il est possible d’utiliser des images que l’on a créé soi-même ou d’utiliser celles créées par d'autres et publiées dans un registre.
Pour créer votre propre image, il faudra créer un fichier « Dockerfile » avec une syntaxe simple permettant de définir les étapes nécessaires à la création de l'image et à son exécution.
Lorsque vous modifiez le « Dockerfile » et reconstruisez l'image, seules les couches qui ont été modifiées sont reconstruites. Cela fait partie de ce qui rend les images si légères, petites et rapides.
Attention : Un « Dockerfile » est un document texte contenant toutes les commandes qu'un utilisateur peut effectuer en la ligne de commande pour assembler une image. En utilisant « docker build », les utilisateurs peuvent créer une construction automatisée qui exécute successivement plusieurs instructions de ligne de commande.
- Docker Registry
Le « Docker Registry » stocke les images Docker.
On peut faire le rapprochement avec une « bibliothèque » dans laquelle toutes les images sont répertoriées et enregistrées.
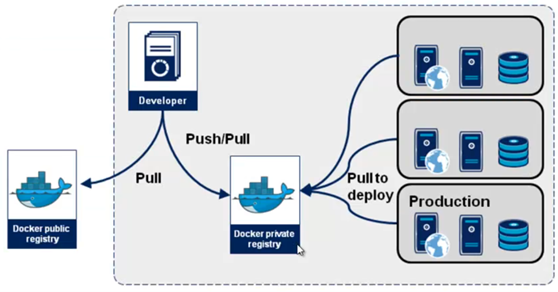
Il existe deux types de registres : les registres privés et les registres publiques.
« Docker Hub » est le registre officiel de docker. Il s’agit d’un registre que tout le monde peut utiliser car il est publique.
Par défaut, Docker est configuré pour rechercher des images sur « Docker Hub » mais il est possible de gérer soit même l’ajout de registres privés.
Lorsque vous utilisez les commandes « docker pull » ou « docker run », les images requises sont extraites du registre qui est configuré.
Lorsque vous utilisez la commande « docker push », l’image ciblée est transférée dans ce même registre.
Les images récupérées depuis des registres privés ou publiques sont également modifiables, il sera possible d’y ajouter ou supprimer des couches si besoins comme indiqué précédemment.
- Conteneurs
Un « conteneur » est une instance exécutable d'une image.
Autrement dit la ou les applications ainsi que les différentes dépendances qui ont été « Dockerisées » dans une image et qui tournent sur le noyau de l’hôte.

Il est possible de créer, démarrer, arrêter, déplacer ou supprimer un conteneur à l'aide de l'API ou de la CLI de Docker.
Un conteneur peut être connecté à un ou plusieurs réseaux, on peut y attacher un stockage ou même créer une nouvelle image en fonction de son état actuel.
Par défaut, un conteneur est relativement bien isolé des autres conteneurs et de son ordinateur hôte.
Il est également possible de contrôler le degré d'isolement du réseau, du stockage ou des autres sous-systèmes sous-jacents d'un conteneur par rapport à d'autres conteneurs ou à la machine hôte.
Un conteneur est défini par son image ainsi que par les options de configuration fournies lorsque qu’il est créé ou démarré.
Lorsqu'un conteneur est supprimé, toute modification de son état qui n'est pas stockée dans le stockage persistant disparaît.
Attention : il faut garder en tête que le but d’un conteneur est d’être éphémère. En effet un conteneur est utilisé uniquement le temps dont on en a besoin et par la suite il est arrêté voir supprimé. De ce fait, on va éviter de mettre des données persistante dans un conteneur mais plutôt les externaliser si on souhaite les garder.