¶ Introduction
Dans cette documentation nous verrons ensemble quelques concepts de stockage virtuels, leur architecture et comment nous pouvons les dépanner efficacement en cas de problème.
¶ Virtual Hardware
Une machine virtuelle est composée en réalité de deux parties.
Nous avons le fonctionnement même de la machine virtuelle (le "running state") qui existe et s'exécute sur notre hyperviseur puis nous avons les fichiers qui la composent qui eux sont enregistrés dans un système de stockage.
Une machine virtuelle est donc très similaire à une machine physique.
Elle possède un système d'exploitation auquel nous devons allouer des ressources et des fichiers qui composeront ou feront partie de la VM.
Le système d'exploitation n'a aucun moyen de savoir qu'il tourne dans une VM, d'ailleurs tout sera fait pour qu'il ne le sache pas et qu'il soit trompé.
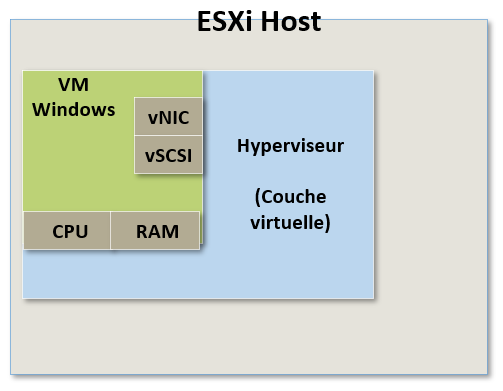
Donc d'une certaine manière nous devons faire croire au système d'exploitation qu'il a accès à de la RAM et à des CPU physiques.
Même si aucun matériel physique n'est réellement dédié à cette VM nous voulons qu'il apparaisse comme s'il était son propre matériel physique dédié : SA RAM et SES CPU.
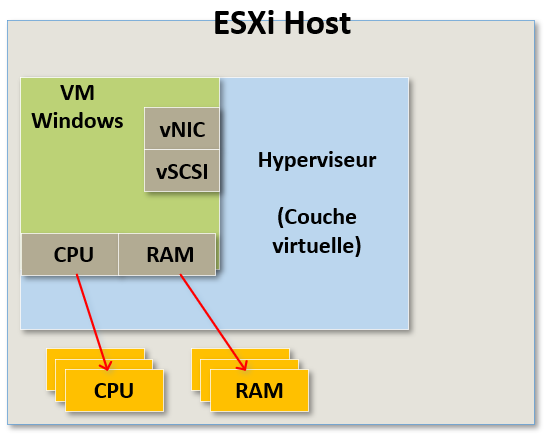
De la même manière nous voulons que le système d'exploitation pense qu'il possède son propre contrôleur SCSI, qui est une partie critique pour le stockage.
Pour cela, nous allons donc présenter des drivers à la VM qu'elle pourra utiliser pour accéder au stockage et ceci de la même manière qu'une machine physique pourrait le faire à partir de contrôleurs SCSI.
La différence ici réside dans le fait que les contrôleurs SCSI que la VM pourra utiliser seront virtuels.
C'est de cette manière que la machine virtuelle sera trompée et pensera accéder à du matériel physique dédié.
Nous allons faire croire à la VM qu'elle a accès au stockage physique alors qu'en réalité, nous allons prendre les commandes qu'elle génère pour le stockage, les transférer dans l'hyperviseur pour qu'elle puisse tirer ses ressources depuis celles de l'hyperviseur.
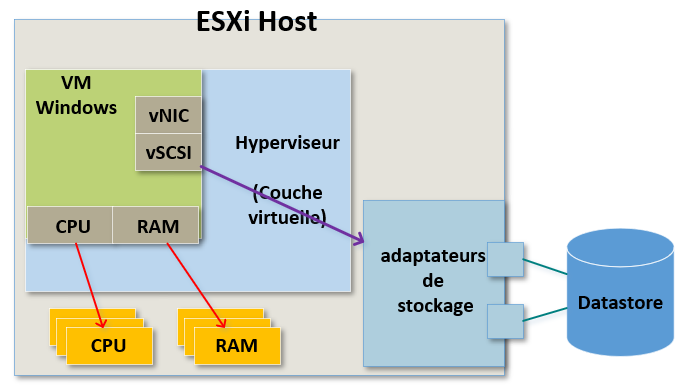
Il en est de même pour la partie réseau.
Nous faisons croire à la machine virtuelle qu'elle possède un ou plusieurs adaptateurs réseau physiques alors qu'en réalité elle possède simplement un driver pour une carte réseau soit de 1Gb/s (type : E1000) soit 10gb/s (type : vmxnet3).
Encore une fois, ce n'est pas du matériel physique. Nous allons prendre le trafic réseau que la VM génère, le transférer vers l'hyperviseur et celui-ci se chargera du trafic depuis ses propres cartes réseau physiques.
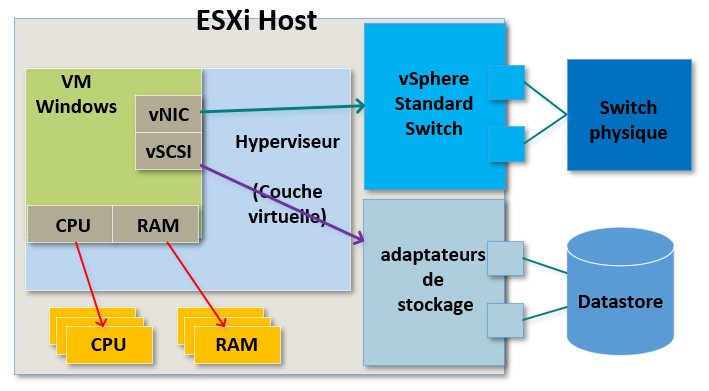
Ce qui est très intéressant dans tout ça, c'est que l'hyperviseur nous donne une couche de virtualisation entre le matériel virtuel et le matériel physique.
Le matériel physique n'a donc pas vraiment d'importance pour la machine virtuelle.
Par exemple dans le cas du stockage la machine virtuelle ne verra jamais à quel type de stockage elle a affaire.
Elle ne saura pas s'il s'agit de NFS, de vSAN, de iSCSI Fibre Channel ou même d'un disque local.
Tout ce qu'elle verra c'est un contrôleur SCSI sur lequel elle enverra ses commandes de stockage.
¶ Virtual Disk
¶ L'accès au disque
Concernant le stockage et les disques virtuels, nous avons à disposition plusieurs options possibles.
De la même manière que pour le CPU et la RAM, la VM ne dispose pas réellement de périphériques de stockage physiques.
A la place elle accède à une ressource partagée appelé un "Datastore".
Pour fonctionner l'OS doit voir le prériphérique de stockage et doit être en mesure de lui envoyer des commandes. Pour cela il va utiliser un contrôleur SCSI.
A nouveau nous allons tromper notre VM en lui mettant à disposition un driver qui cette fois sera utilisé pour le stockage grâce à un contrôleur SCSI virtuel.
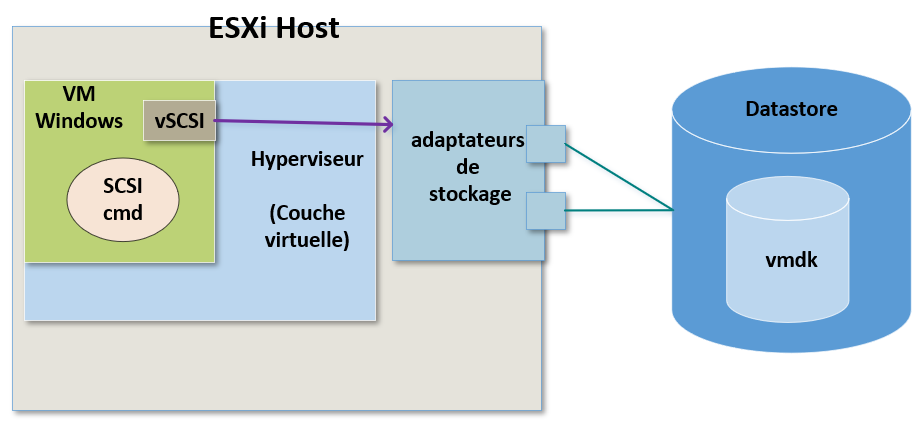
Lorsque l'OS aura besoin de lire ou d'écrire des données, ces commandes seront envoyées au contrôleur SCSI virtuel.
A partir de là, ces commandes de stockage vont atteindre l'hyperviseur qui lui se chargera de les rediriger vers le fichier ".vmdk" correspondant à cette machine virtuelle.
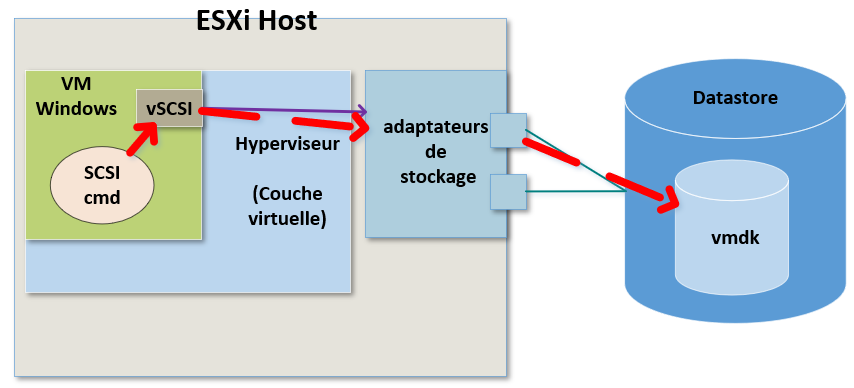
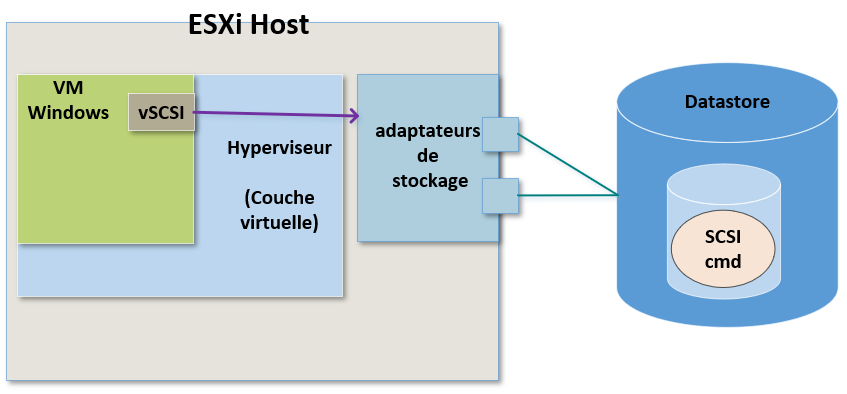
Cette manière de procéder est exactement ce qui va nous apporter de nombreuses fonctionnalitées de stockage dans vSphere.
Nous pourrions par exemple faire une migration du stockage (Storage vMotion).
Nous pourrions migrer ce fichier ".vmdk" d'un Datastore à un autre sans que la VM ne sache que ça s'est produit.
Tout ce que verra réellement la VM c'est une commande de stockage qui sortira d'un contrôleur SCSI.
Ce que fera par la suite l'hyperviseur avec cette commande lui est totalement inconnu.
¶ Les options du disque
¶ Provisionnement dynamique - Thin Provisioned
Il existe également des options pour le type de dsique virtuel que nous pourrons utiliser pour nos VMs.
Le choix le plus souvent utilisé est le "provisionnement dynamique (Thin Provisioned)".
Lorsque l'on crée une VM, une certaine quantité d'espace de stockage sur un Datastore est allouée aux fichiers du disque virtuel.
Le "provisionnement dynamique" va nous permettre de créer des disques virtuels dont la taille n'est pas fixe.
Les ESXi vont allouer depuis un Datastore l'intégralité de l'espace défini pour le disque de la VM mais seule la taille du stockage réel sera consommée.
Pour comprendre, imaginons que nous ayons une VM avec un disque virtuel de 80Go et que nous avons configuré ce disque comme étant un disque avec "provisionnement dynamique".
Imaginons maintenant que cette VM ne possède en réalité que 40Go de données réelles.
Cela signifie que seuls ces 40Go de données réelles seront consommés sur le Datastore lui-même.
La VM pense disposer d'un disque de 80Go mais sur le périphérique de stockage physique elle n'en consomme que 40Go.
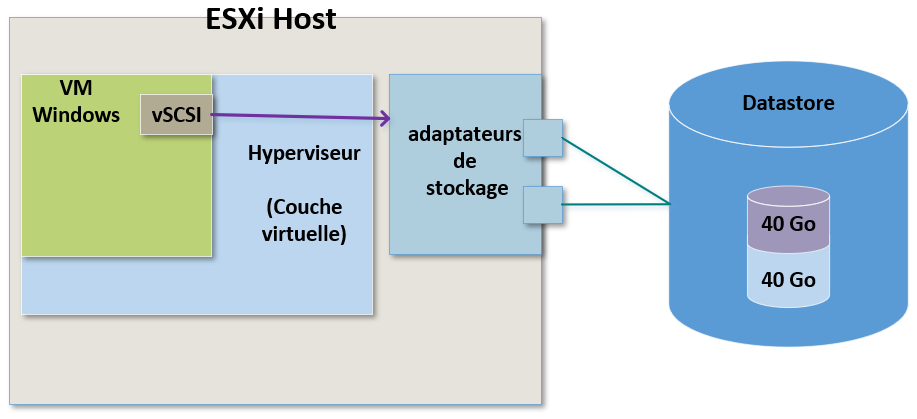
Le "provisionnement dynamique" est très pratique et permet déconomiser de l'espace de stockage mais comporte aussi un certain risque.
Si nous créons trop de disques avec "provisionnement dynamique" sur un Datastore et que nos VMs continuent de générer des données sur les disques alors leurs disques vont grandir pour occuper de plus en plus de place. Ainsi la place qu'ils prennent sur l'espace de stockage aussi va elle aussi grandir.
Dans ce cas il est possible que nous saturions accidentellement un Datastore.
Il est donc plus que conseillé d'utiliser les alarmes disponibles dans vCenter pour surveiller l'utilisation des Datastores, l'espace libre disponible, etc.
Ces alarmes peuvent être configurées pour envoyer des Emails ou des traps SNMP aux administrateurs de l'infrastructure.
Si l'on utilise le "provisionnement dynamique" il faut utiliser des mesures préventives pour éviter tout problème de saturation des Datastores car si l'on sature un Datastore, toutes les VMs dont les disques virtuels se trouvent sur ce Datastore se trouveront impactées.
Elles ne pourront plus écrire de données et s'arrêteront.
¶ Provisionnement statique - Thick Provisioned
Pour éviter les mauvaises surprises que l'on vient d'évoquer, une autre possibilité consiste à utiliser des disques virtuels avec "provisionnement statique (Thick Provisioned)".
Contraitrement au provisionnement dynamique, lorsque l'on créé un disque virtuel avec "provisionnement statique", l'intégralité de l'espace de stockage de ce disque virtuel est immédiatement utilisé sur le périphérique de stockage.
Si l'on reprend l'exemple précédent, notre VM voit et possède donc réellement un disque virtuel de 80Go et c'est bien 80Go qui seront directement utilisés dans notre Datastore même si la VM n'en utilise que 40Go.
Ce n'est pas aussi efficace en terme d'utilisation de l'espace de stockage mais le risque de saturer accidentellement un Datastore est quasi nul (tou dépend de votre gestion des Datastore évidemment).
Donc lorsque je créé un vmdk pour une VM (un disque virtuel), je peux donc choisir si je veux qu'il soit à "provisionnement dynamique" ou à "provisionnement statique".
Si vous décidez d'utiliser des disques avec "provisionnement statique" vous aurez alors la possibilité de le faire de deux manières différentes : "Eager zeroed" ou "Lazy zeroed".
Lors de la création d'un nouveau disque dur, il est possible que l'espace qui lui soit alloué dans le Datastore contienne encore d'anciennes données. Dans ce cas avant de pouvoir de nouveau utiliser cet espace, ces données vont devoir être effacées pour pouvoir y écrire à la place les nouvelles données nécesaires à notre VM.
¶ Thick Provisioned Eager zeroed
Un disque de type "Thick Provisioned Eager zeroed" est un disque statique disposant de tout l'espace requis au moment de sa création. Lorsqu'il est créé, tout cet espace est automatiquement effacé pour supprimer les anciennes données qui se trouvaient sur le support de stockage physique.
La création de ce type de disque prend donc un peu plus de temps mais on peut être certain que plus aucune donnée ne sera présente sur ce disque.
Pour cela il sera intégralement rempli de zéros lors de sa création. Chacun de ses blocs sans exception sera donc rempli de zéros.

¶ Thick Provisioned Lazy zeroed
Un disque de type "Thick Provisioned Lazy zeroed" est un disque statique disposant lui aussi de tout l'espace requis au moment de sa création mais dont l'espace peut contenir d'anciennes données sur le support de stockage physique.
Ces anciennes données ne sont ni effacées ni écrasées et seront « mises à zéro » uniquement à la demande lorsque de nouvelles données auront besoin d'être écrites dans les blocs déjà occupés.
Autrement dit, les blocs contenant d'anciennes données seront remplis de zéros uniquement si la VM a besoin d'écrire dans ces blocs et ceci AVANT d'y écrire des données.
Ce type de disque peut être créé plus rapidement, mais ses performances seront moins bonnes pour les premières écritures en raison de l'augmentation des IOPS (opérations d'entrée/sortie par seconde) pour les blocs qui contiennent d'anciennes données.
Pour ces raisons, ce type de disque n'est pas recommandé d'ordre général et encore moins pour les applications qui nécessitent d'écrire beaucoup de données comme par exemple des bases de données.
Pour information, les disques à "provisionnement dynamique (Thin Provisioned)" écrivent eux aussi des zéros à la demande dans les nouveaux blocs afin de supprimer d'éventuelles anciennes données.
¶ NFS Troubleshooting
Nous allons voir à présent l'architecture de stockage globale et essayer de déterminer d'où les problèmes et les latences peuvent survenir.
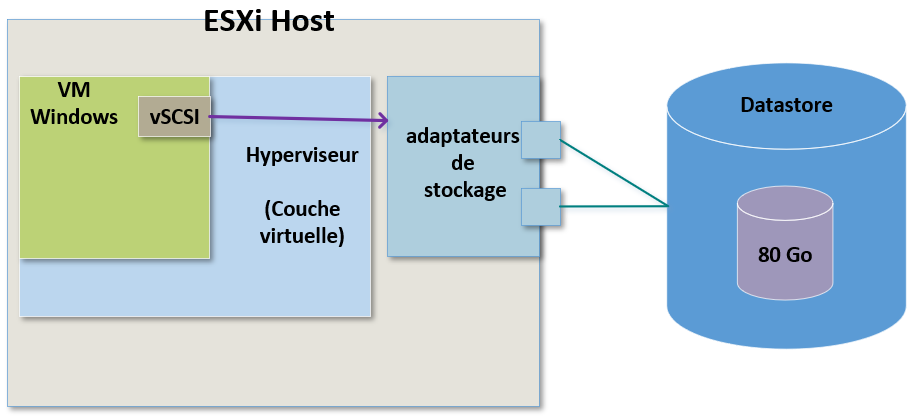
Dans le cadre de stockage avec des Datastores utilisant NFS, prenons l'exemple du schéma suivant :
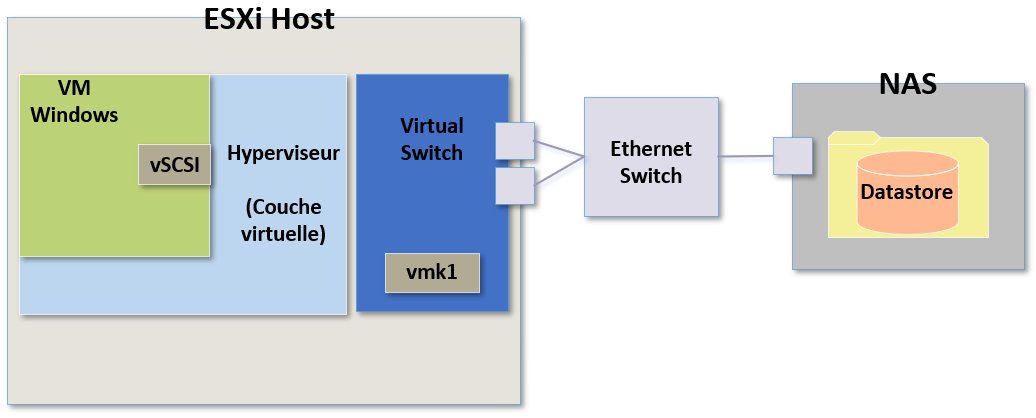
La première chose à faire quand on tente de résoudre un problème de stockage c'est de connaître son étendue :
Est-ce que ce problème est lié à chacune des VMs, est-il lié à une VM en particulier ?
S'il s'agit d'une Seule VM, il serait problablement intéressant de s'y connecter.
On pourrait par exemple vérifier s'il s'agit d'un problème du système d'exploitation, d'un problème avec le contrôleur SCSI virtuel.
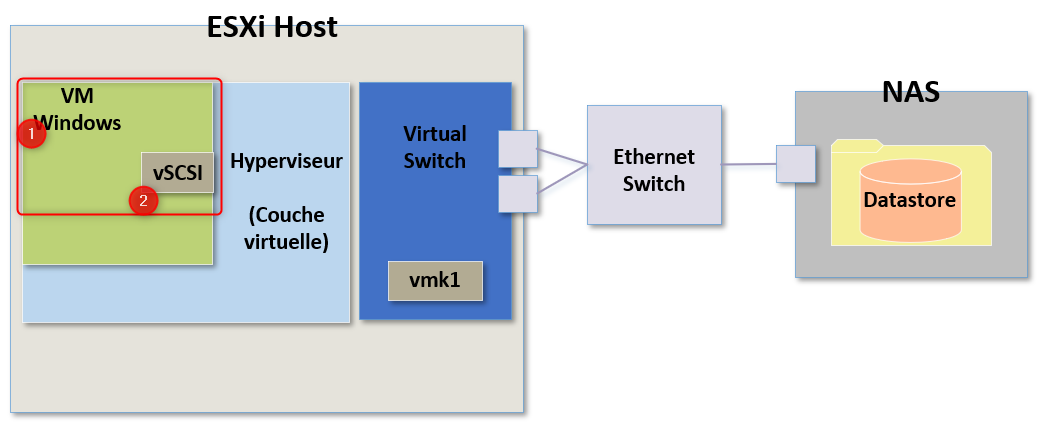
Si je découvre que toutes les VMs impactées se trouvent sur le même hôte ESXi, on peut supposer que le problème serait alors plutôt en local sur l'hyperviseur. Dans ce cas qu'est-ce que ça pourrait être ?
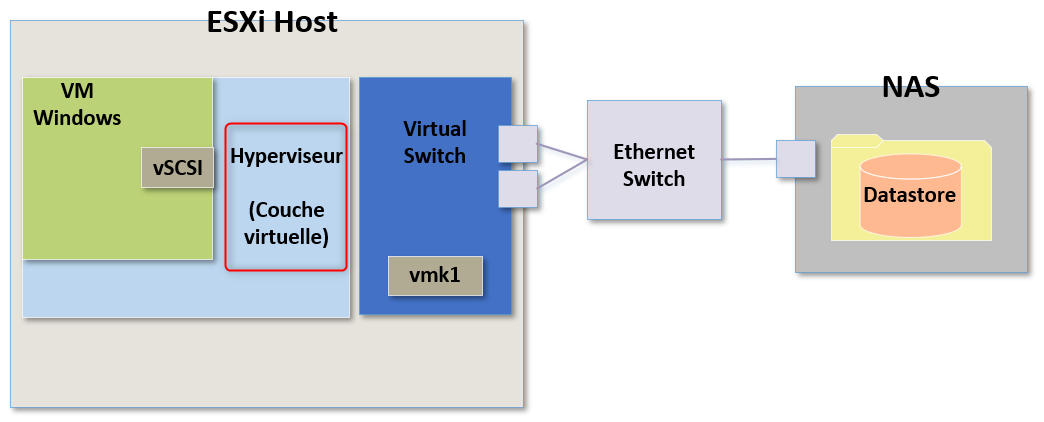
Je pourrai voir ce que l'on appel "Kernel Latency", c'est à dire des latences directement au niveau du kernel.
Ce type de latence indique que l'hyperviseur lui-même introduit de la latence dans les commandes de stockage.
On peut facilement vérifier cette information en utilisant esxtop et en vérifiant la colonne "KAVG/cmd (pour Kernel Average Latency)"
Le résultat doit être inférieur à 1ms. Si l'hôte ESXi met plus d'une milliseconde à traiter les commandes de stockage alors nous avons un problème et nous pouvons concentrer nos efforts de dépannage sur l’hôte lui-même.

Une autre des raisons qui pourraient dégrader les performances de stockage NFS d'un ESXi serait tout simplement un problème avec une des cartes réseau physiques.
Avec NFS toutes les commandes de stockage sont acheminées via un switch virtuel.
Donc si nous avons un problème avec soit un switch virtuel, soit un des ports physiques liés à ce vSwitch, soit directement sur la liaison Ethernet d'un des ports physiques liée à un switch physique alors cela entrainera des latences sur l'hôte.
C'est ici que je continuerai mes recherches pour trouver les causes de la panne.
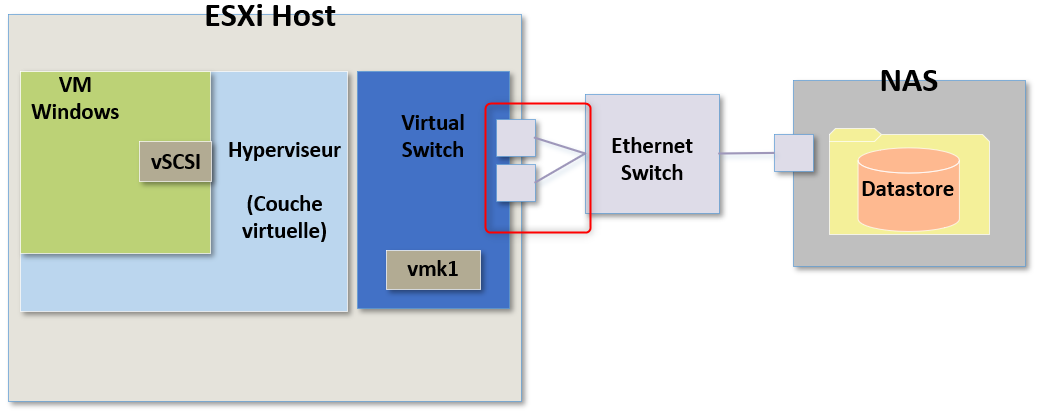
J'attire votre attention sur la manière dont j'ai créé le schéma.
Il n'est pas vraiment idéale et ne correspond pas vraiment à la réalité.
Si je devais configurer du stockage NFS en production, je ne connecterai surtout pas tous les ports physiques liés au vSwitch sur le même switch physique. Ici c'est un schéma simplifié pour nous aider à comprendre les différentes étapges de Troubleshooting.
Toutefois pour information, j'utilisrai des connexions vers des switches physiques différents pour avoir du failover et de la redondance en cas de problème.
Est-ce que cela solutionnerai tous les problèmes ? Non, les problèmes de connexion peuvent aussi arriver sur le switch physique.
On pourrai avoir une erreur de configuration des paramètres MTU ou le switch pourrait tout simplement être débordé et il serait en train de saturer en CPU ou en RAM par exemple.
Dans ce cas il s'agit d'un autre endroit potentiel où notre problème pourrait exister et où nous devrions chercher.
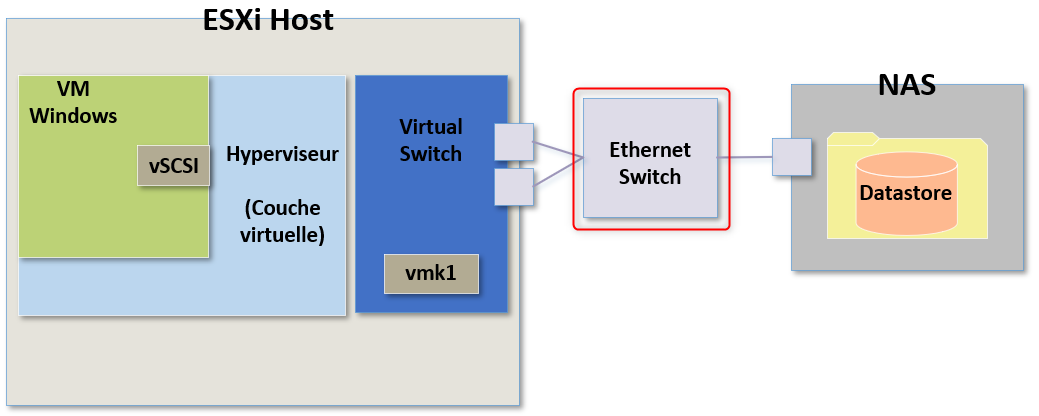
Je pourrai également avoir un lien encombré entre le switch physique et mon périphérique de stockage, les CPU du NAS pourraient également être saturés et trop monter en charge ou alors je pourrai avoir directement des problèmes de stockage physique dans le NAS lui même.
Toutefois si nous avions ce type de problèmes, ils se manifesteraient sur plusieurs ESXi et on pourraient directement se concentrer sur cette partie sans passer par la phase de recherche côté VM, en local sur les ESXi, etc.
Peut importe le type de problème que cela pourrait être, il est important de garder en tête qu'il existe également de nombreux problèmes potentiels que vous pourriez rencontrer sur le périphérique de stockage lui-même.
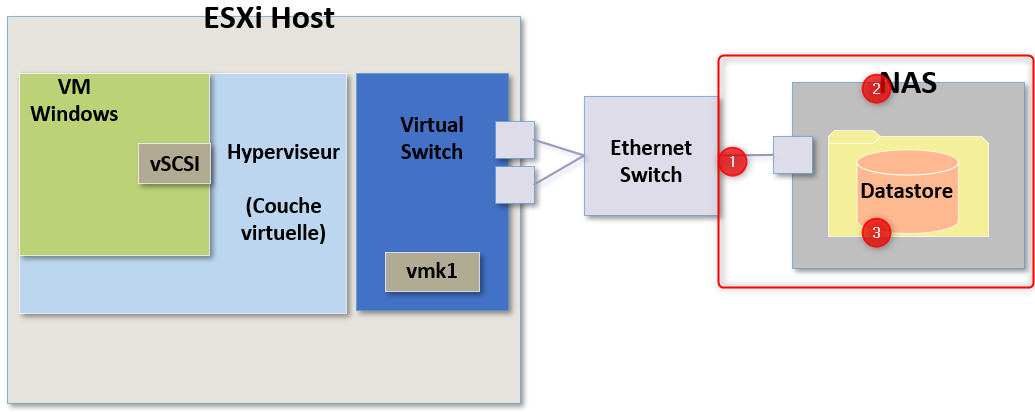
Attention encore une fois il s'agit d'un schéma simplifié et en production nous n'aurions pas qu'un seul lien et pas forcément non plus qu'un seul NAS mais je ne m'étendrai pas sur ça ici.
¶ iSCSI Troubleshooting
Voyons à présent le stockage mis en place avec de l'iSCSI et pour ça nous allons prendre comme exemple le schéma suivant :
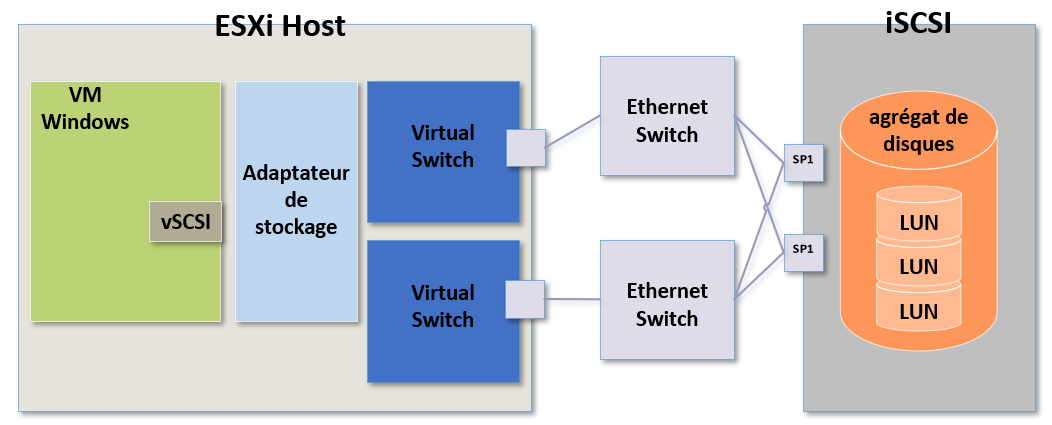
Le schéma n'est pas totalement différent mais il y a toutefois certains éléments spécifiques qu'ils faudra prendre en compte das nos recherches.
Comme précédemment si le problème ne concerne qu'une seule VM, nous allons concentrer nos recherche sur la partie système d'exploitation et sur le contrôleur SCSI virtuel.
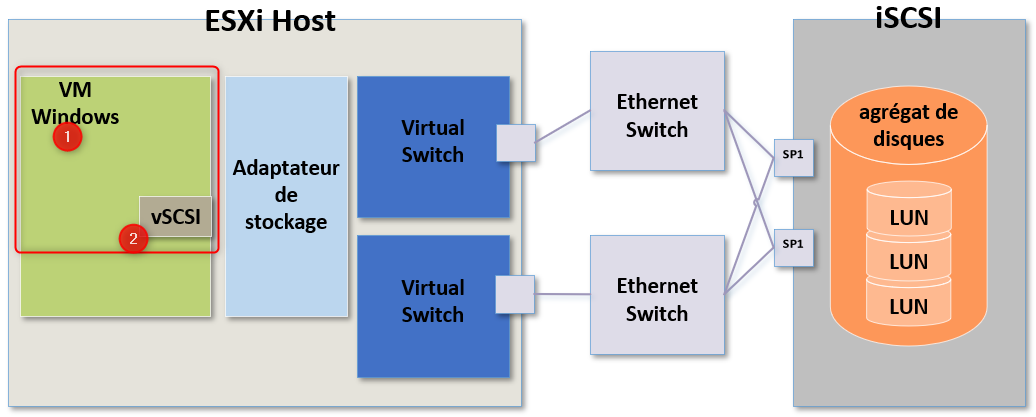
Lorsqu'une VM génère une commande SCSI, cette commande est relayée vers l'adaptateur de stockage de l'hôte ESXi.
Ici nous utilisons l'iSCSI et l'adaptateur de stockage utilisé pourrait très bien être un initiateur iSCSI physique dédié, un initiateur iSCSI logiciel ou un initiateur iSCSI physique dépendant.
Dans mon exemple on va partir du principe qu'il s'agit d'un initiateur iSCSI logiciel.
Le rôle de l'adaptateur de stockage consiste à recevoir les commandes SCSI dans leur format brut (raw) depuis la machine virtuelle puis de les préparer (ou convertir) en paquets SCSI pour qu'ils puissent traverser le réseau physique.
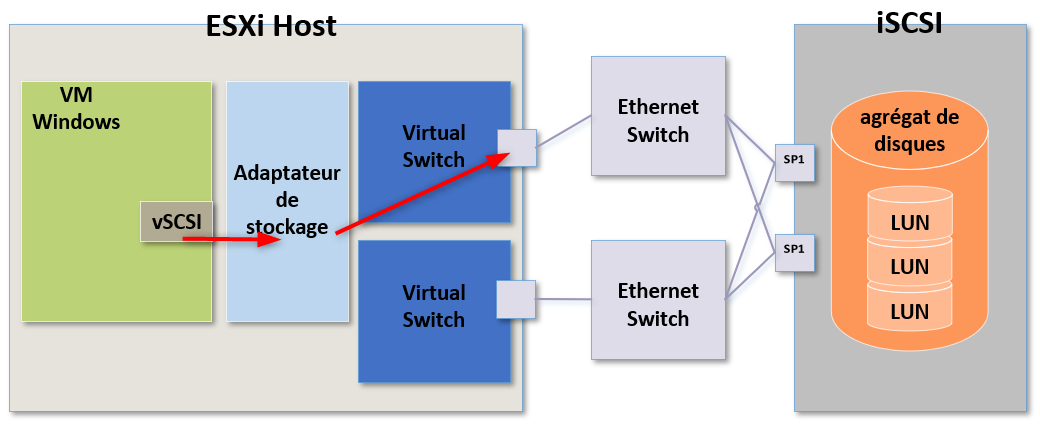
Comment pourrions nous dépanner un potentiel problème ici ?
Il faut savoir que l'adaptateur de stockage ne fonctionnera que s'il existe suffisamment de ressources CPU sur l'ESXi.
Je rappel que dans mon exemple il s'agit d'un initiateur iSCSI logiciel et qu'à ce titre il s'agit d'un composant logiciel de l'ESXi. d'ailleurs, il en est de même pour les vSwitch et les VMKernel Ports. Tous les élements logiciels de l'ESXi fonctionneront correctement si l'hôte possède assez de ressources CPU pour cela.
Si j'utilise du stockage iSCSI, je peux utiliser deux vSwitch différents sur lesquels j'aurai créé un VMKernel Port et faire en sorte que le trafic utilise ces deux VMK au travers de deux switches physiques.
Ainsi je m'assure d'avoir du load balancing et de la redondance en cas de panne.
Le trafic sortira par ces deux adaptateurs physiques différents et en cas de panne d'un switch physique je m'assure que le trafic continuera de passer sur le réseau.
Donc si j'ai un problème de performance en local sur un ESXi, je vais regarder en premier les ressources CPU de l'ESXi puis je vais regarder les connexions réseau physiques de cet hôte et m'assurer que tout est fonctionnel.
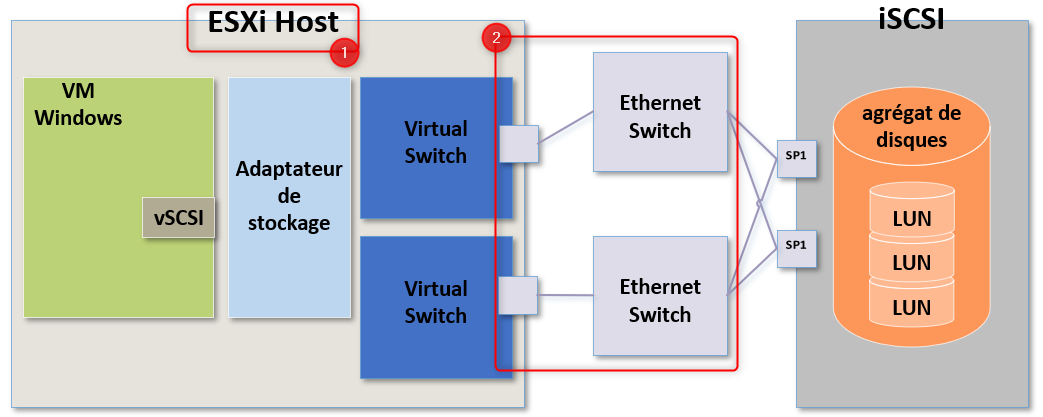
Si après vérifications nous ne rencontrons pas de problème de ce côté là, nous pourrons alors vérifier le réseau lui-même.
Les ressources des switches physiques sont-elles surchargées ? Y'a t-il simplement trop de trafic réseau sur ces swicthes et ils n'arrivent pas à suivre ?
On peut également vérifier si une des connexions au périphérique de stockage n'est pas tombée ou se demander s'il n'y a pas un problème réseau qui entrainerai de la latence.
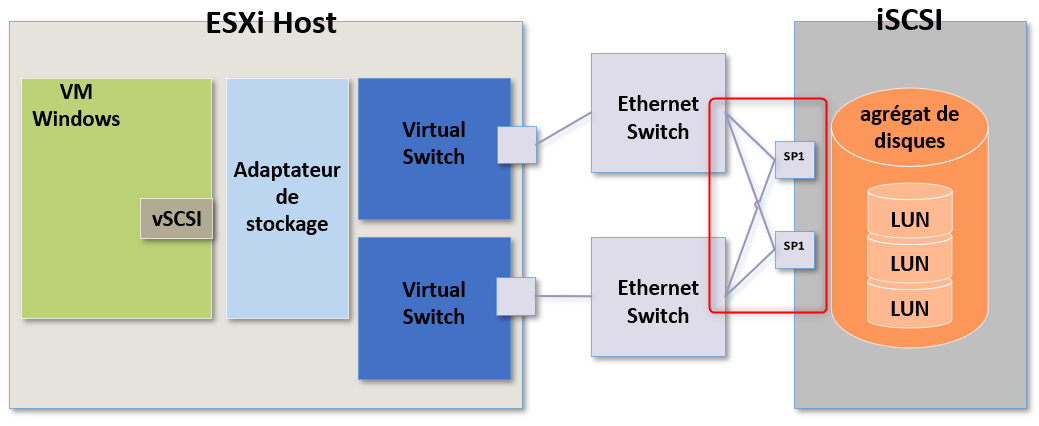
Si tout est fonctionnel dans ce cas je chercherai du côté du périphérique de stockage.
Tout comme pour le stockage via NFS, si un problème est présent sur le périphérique de stockage alors nous aurions probablement des problèmes sur plusieurs ESXi.
Si tel est le cas, inutile de faire les étapes précédente. Il faut se concentrer sur le périphérique de stockage.
Si les ressources CPU du périphérique de stockage sont saturés, cela entrainera toutes sortes de latences voir même des pertes ou des abandons de paquets.
Inutile de préciser que des paquets perdus ou abandonnés n'est pas vraiment une bonne nouvelle...
Encore une fois nous pourrions voir ces pertes ou ces abandons de paquets en utilisant esxtop et en regardant le résultat de %DRPTX et %DRPRX
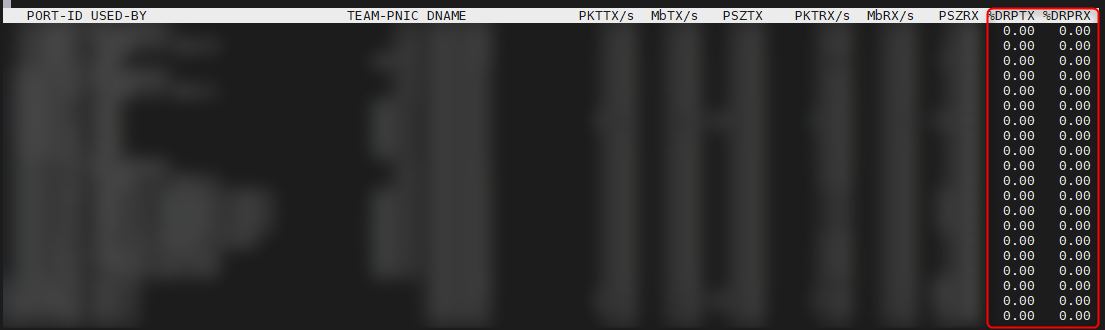
Nous pourrions également avoir des latences car le périphérique de stockage ne serai pas en mesure de traiter la quantitée d'I/O générée par nos serveurs ou encore le fait que nos disques ne soient pas assez rapides par exemple.
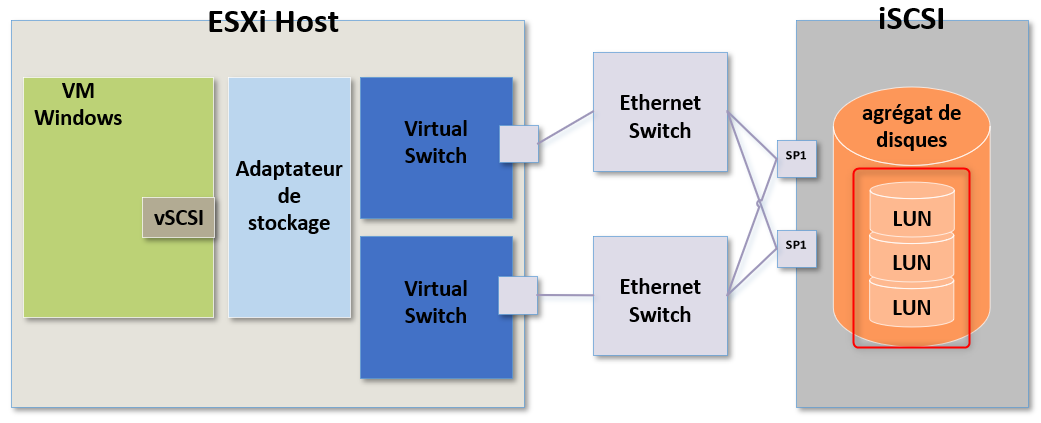
la clé pour résoudre et identifier des problèmes liés au stockage est vraiment de connaître l'architecture réseau qui lui est dédiée.
Cela nous permettra de facilement identifier la cause des problèmes pour y palier rapidement
Chapitre suivant : 2- VMFS et NFS Datastores dans vSphere 7