¶ Préambule
Dans cette section, nous allons parler de vSphere High Availability.
Il existe de très nombreux tutoriels et de très nombreuses formations qui couvrent ce sujet de manière assez poussée.
C'est pourquoi nous allons aborder ici uniquement la partie théorique de vSphere High Availability.
Pour une formation plus détaillée de vSphere High Availability, je recommande dans ce cas de consulter l'une de ces formations.
¶ Création d'un Cluster HA dans vSphere 7
Avant de commencer, il est important de comprendre qu'un Cluster vSphere High Availability n'est en aucun de la haute disponibilité liée à vCenter, il s'agit d'une feature totalement différentes.
vSphere High Availability permet d'avoir de la haute disponibilité sur l'ensemble des VMs et ce n'est pas spécifiquement lié directement à vCenter.
¶ Prérequis
- Avoir un serveur vCenter
- Soit avoir un Cluster d'ESXi dans vCenter contenant au moins deux ESXi
- Soit avoir au minimum deux ESXi non gérés par vCenter que l'on souhaite ajouter à un Cluster
¶ Création du cluster HA
Pour cette documentation, nous allons commencer par créer un Cluster dans vCenter (si vous en avez déjà un alors cette étape ne sera pas nécessaire).
Pour cela nous allons faire un clique droit sur le "Datacenter" puis choisir "nouveau cluster"
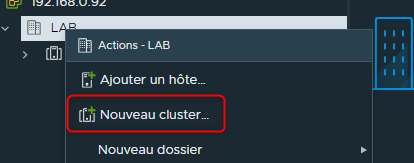
Nommer le Cluster puis cliquer sur "suivant"
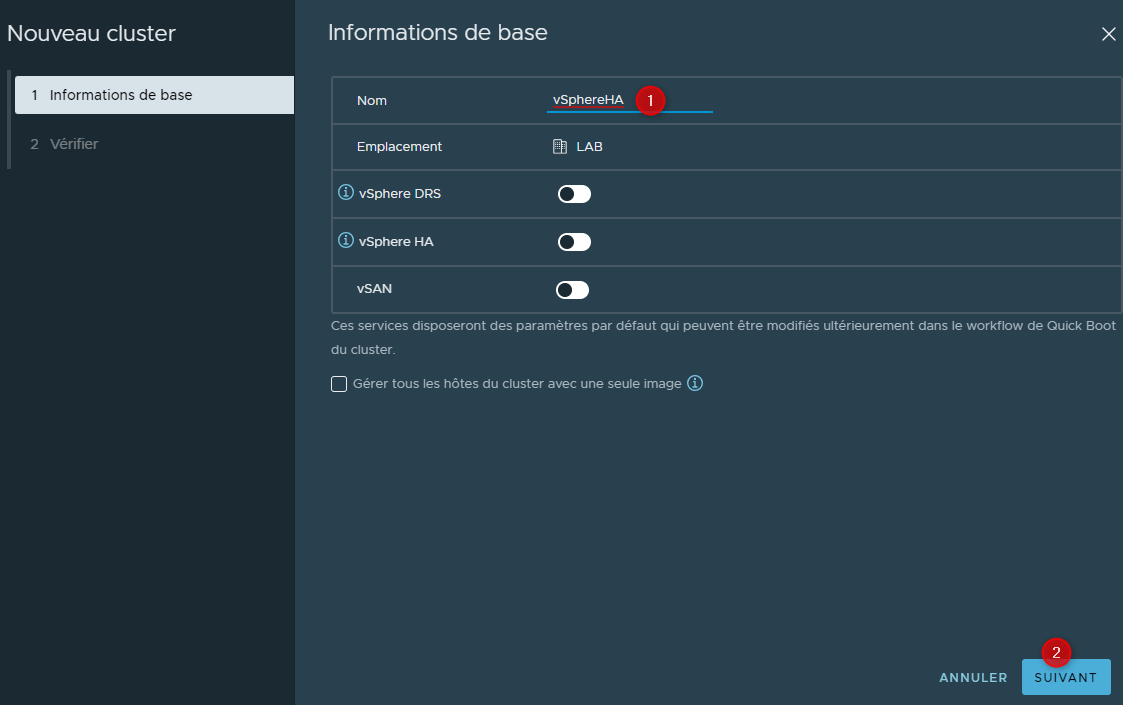
Vérifier les informations puis cliquer sur "Terminer"
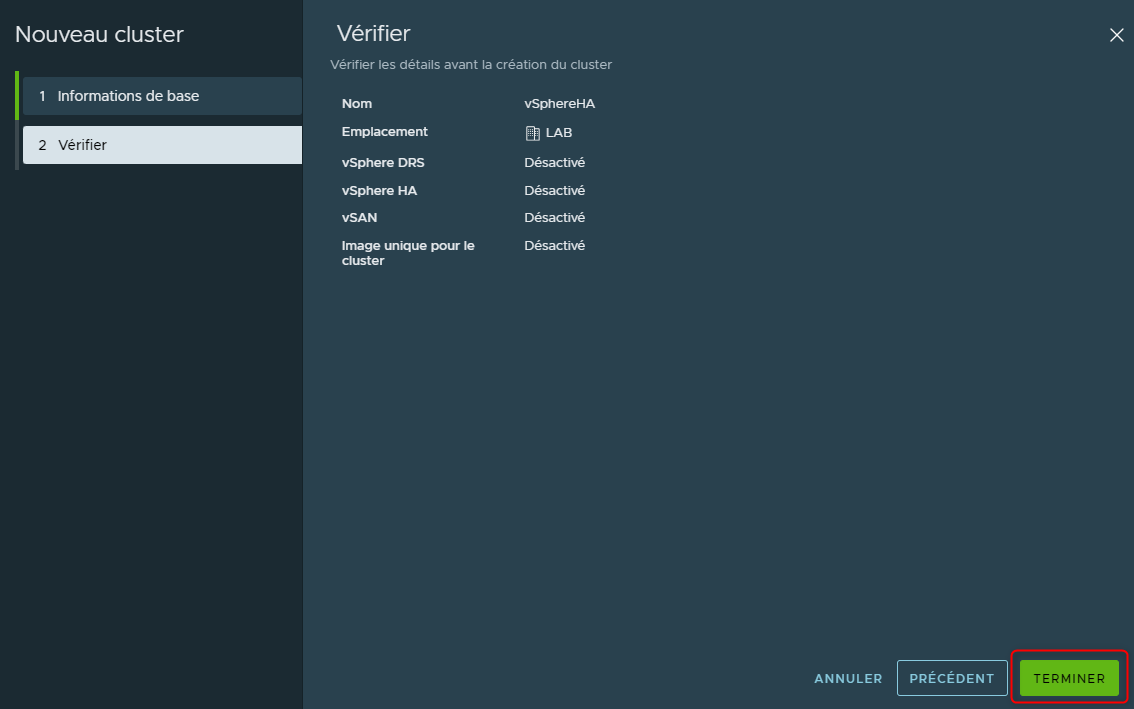
Le Cluster sera visible dans la liste des Cluster associé au "Datacenter"
Une fois que l'on a créé le Cluster on va y ajouter des ESXi.
On a deux possibilités, soit on peut ajouter des hôtes soit on a déjà des hôtes dans un Cluster existant que l'on va déplacer dans notre nouveau Cluster.
¶ Déplacer des ESXi
- Commencer par passer les ESXi en mode maintenance : clique droit sur l'ESXi, "Mode maintenance" puis "Passer en mode maintenance"
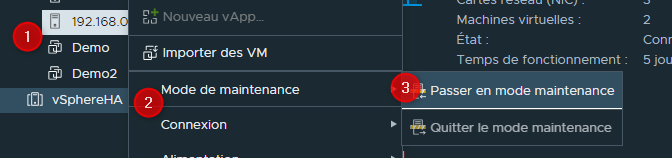
- Sélectionner un ESXi et le faire glisster depuis son Cluster actuel vers le Cluster ciblé
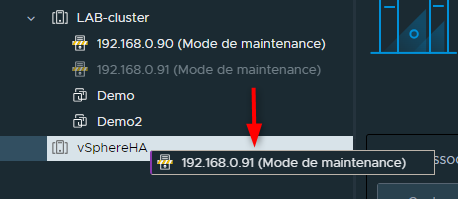
- Sortir les ESXi du mode maintenance : clique droit sur l'ESXi, "Mode maintenance" puis "Quitter le mode maintenance"

- Les ESXi sont à présent dans le nouveau Cluster
¶ Ajouter des hôtes non gérés par vCenter
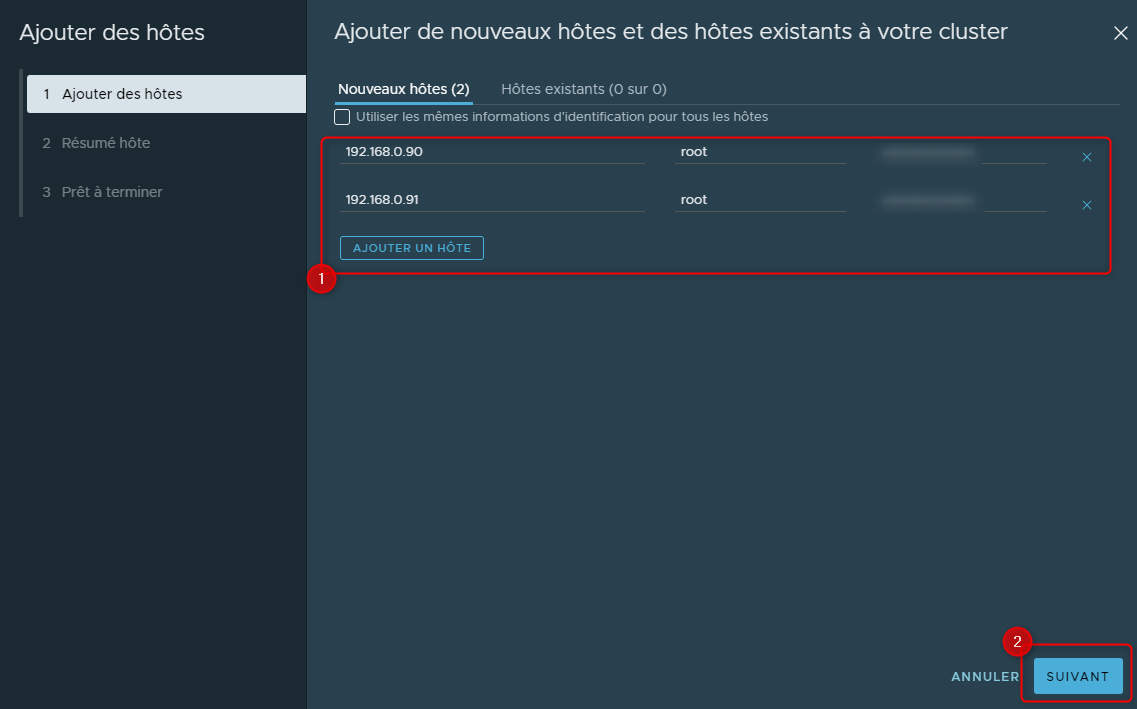
Faire un clique droit sur le Cluster et sélectionner "Ajouter des hôtes"

Entrer soit le FQDN soit l'IP de l'esxi puis le login et le password du compte root puis cliquer sur suivant
En cliquant sur "Ajouter un hôte" il sera possible de cibler un ESXi supplémentaire pour en ajouter plusieurs d'un coup
Vérifier le résumé puis cliquer sur "Suivant"
Confirmer l'ajout des hôtes en cliquant sur "Terminer"
Après un très court instant les ESXi seront ajoutés dans le Cluster et managés par vCenter
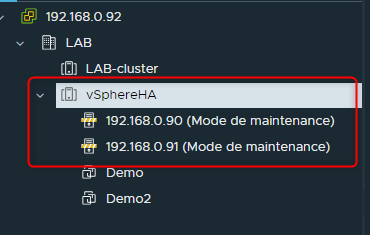
¶ Configuration de vSphere HA
A présent que nous avons un Cluster contenant au moins deux ESXi, nous allons pouvoir configurer le vSphere HA.
Cliquer sur le Cluster puis cliquer sur "Configurer" et en fin cliquer sur "Disponibilité vSphere (vSphere Availibility en anglais)"
Par défaut vSphere HA est désactivé.
Pour l'activer, cliquer sur "Modifier en haut à droite"

La première chose à faire est donc d'activer vSphere HA
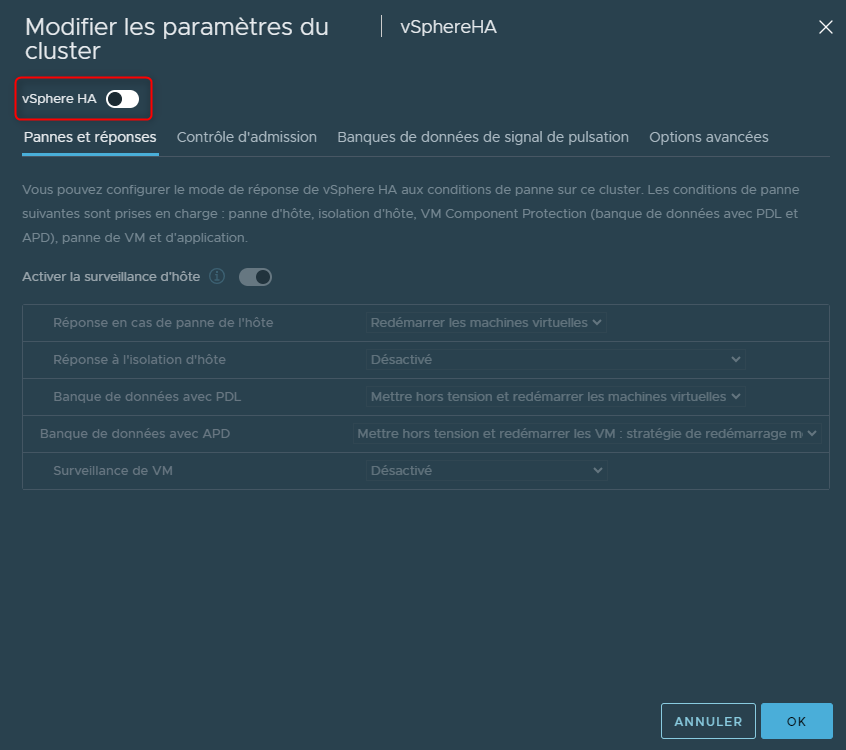
L'activation de vSphere HA va automatiquement activer "la surveillance d'hôte"
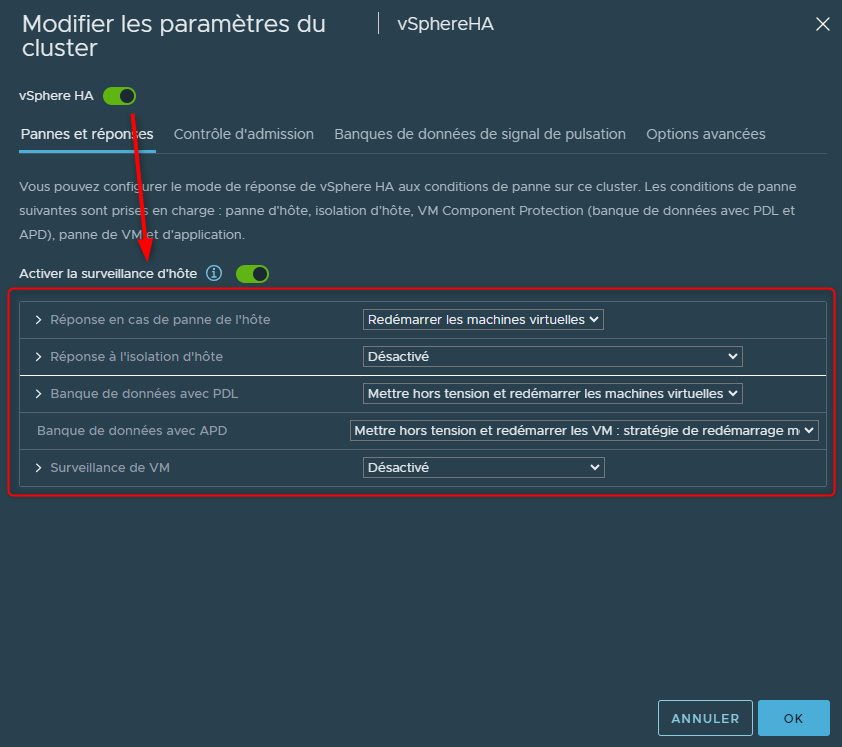
Cette option, qui peut être désactiver sans désactiver vSphere HA, va permettre de monitorer directement les ESXi pour des choses telles que des pannes ou l'isolement de l'hôte.
Lorsque l'on configure vSphere HA sur un Cluster, c'est vraiment une option que l'on souhaite activer puisqu'elle nous permettra de configurer plusieurs éléments très importants.
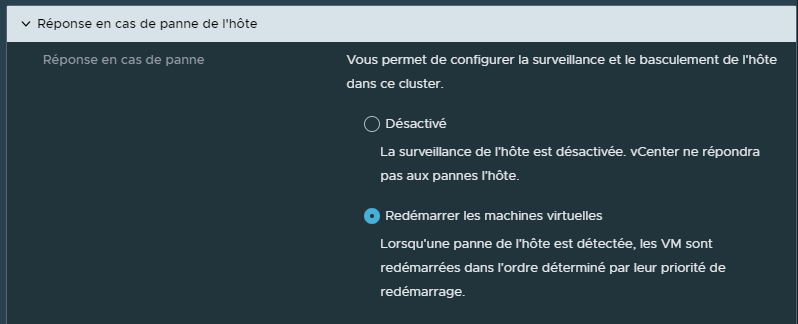
¶ Réponse en cas de panne d'hôte :
Cette option permet de déterminter les actions à faire sur les VMs en cas de panne d'un hôte.
Est ce que l'on souhaite ne rien faire ou est ce que l'on souhaite que les VMs hébergées par l'hôte en panne redémarrent sur un autre ESXi?
Par défaut cette option est activée
Il sera également possible de configurer la priorité de redémarrage des VMs.
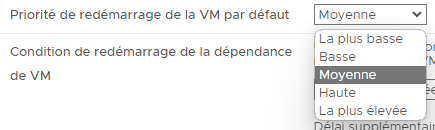
Ces priorités vont permettre, en cas de panne, de déteriner quelles machines virtuelles devront redémarrer les premieres.
Par défaut toutes les machines virtuelles ont une priorité positionnée sur "moyenne" signifiant qu'aucune d'entre elles ne sera prioritaire sur les autres et qu'elles seront toutes égales les unes par rapport aux autres.
Dans l'éventualité où l'on aurai des VMs dont la priorité serai plus haute que d'autres, ces VMs vont alors redémarrer les premières puis le prochain groupe de VMs (toujours selon les priorités définies sur les VMs) redémarrera lorsque les "Conditions de redémarrage" seront remplies.
Que signifit la notion de "Condition de redémarrage" ?
Il s'agit des conditions définies permettant d'affirmer que les VMs ayant une priorité plus élevée que les autres sont bien démarrées et qu'il sera alors possible de démarrer les suivantes.

Par exemple, est-ce lorsque les ressources sont allouées pour tous les VMs dont la priorité est elevée ?
Est-ce lorsque ces VMs sont réellement sous tension ?
Est-ce lorsque ces VMS envoient réellement des pulsations d'invités via les VMware Tools ?
Le redémarrage va commencer par les VMs dont la priorité est elevée puis passer aux VMs suivantes et ainsi de suite pour terminer par les VMs dont la priorité est la plus basse.
Il sera également possible de définir un délai pour le redémarrage des Vms avec une priorité inférieure à celles en cours de redémarrage.
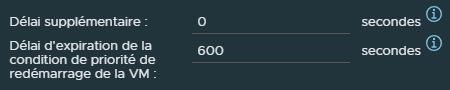
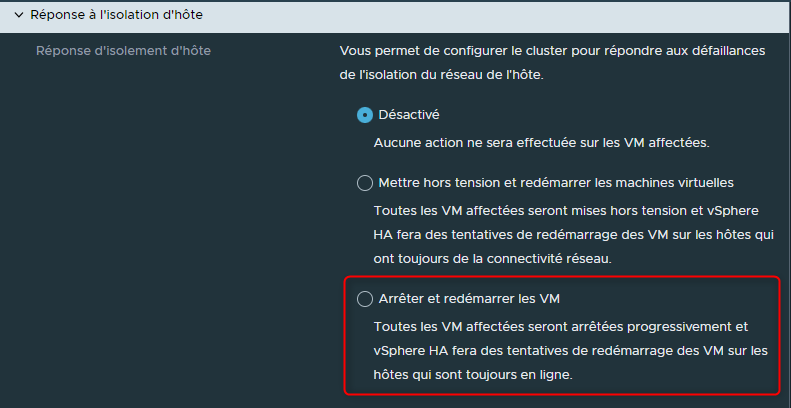
¶ Réponse à l'isolation d'hôte
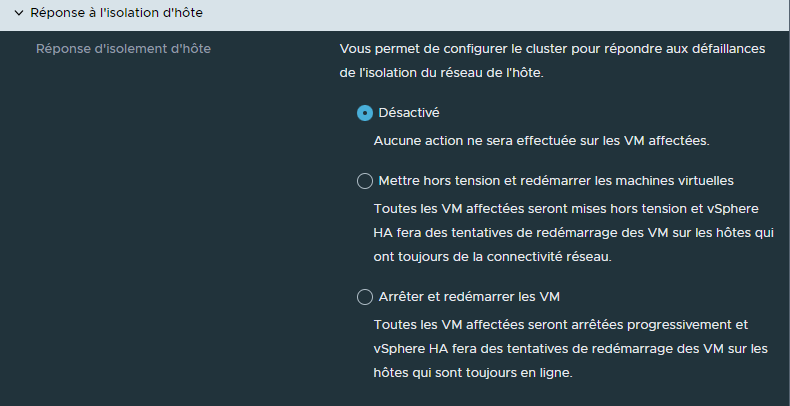
"Réponse à l'isolation d'hôte" permet de déterminer ce qui doit être fait si un ESXi semble toujours fonctionnel, dans le sens où il a toujours accès au stockage et qu'il est toujours sous tension, mais isolé du réseau.
Doit-on laisser les VMs de cette hôte seules parce que l'hôte est toujours en cours d'exécution?
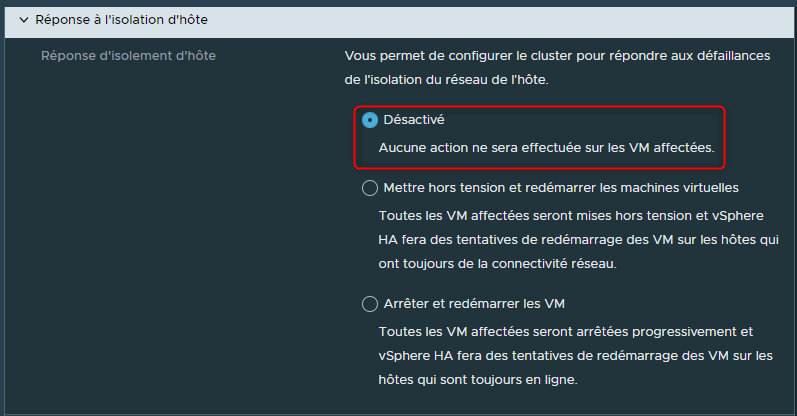
Doit-on éteindre de manière "brutale" les Vms de cet hôte et les redémarrer sur d'autres hôtes qui ont toujours de la connectivité réseau ?
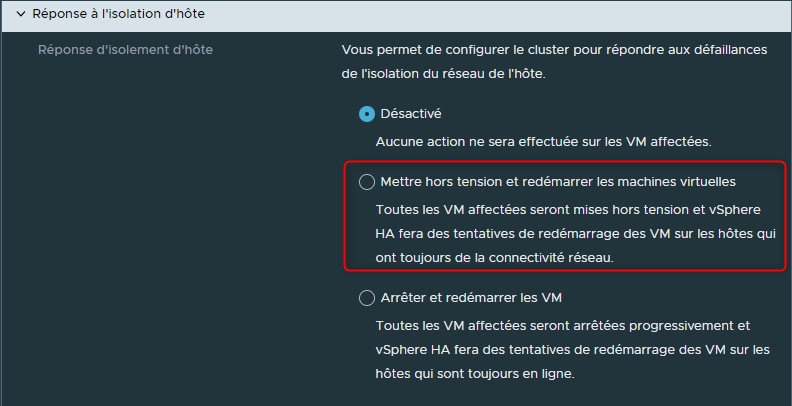
Doit-on arrêter proprement les VMs de cet hôte et les redémarrer sur d'autres hôtes ?
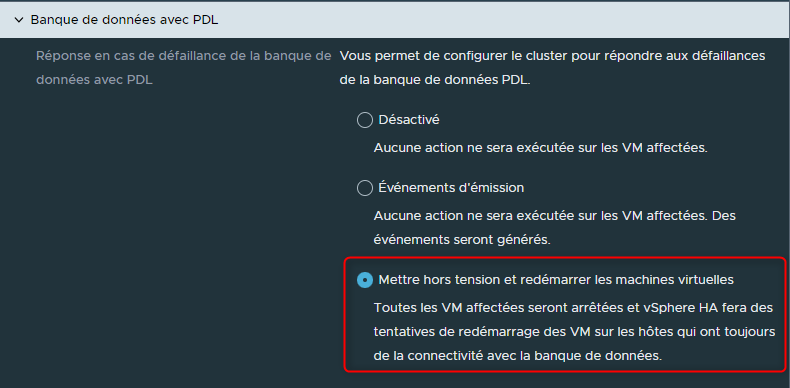
¶ Banque de données avec PDL (Permanent Device Loss)
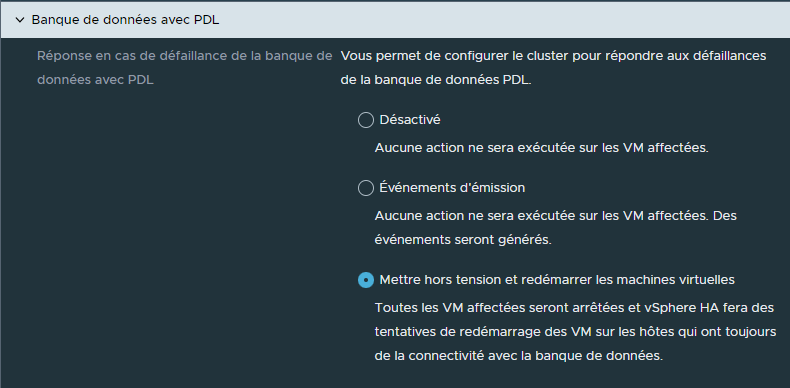
Dans le cas où un ESXi perdrait l'accès à une banque de données, "Banque de données avec PDL permettra de configurer un comportement à adopter pour les VMs se trouvant sur cet hôte et dont le stockage se trouve sur cette banque de données.
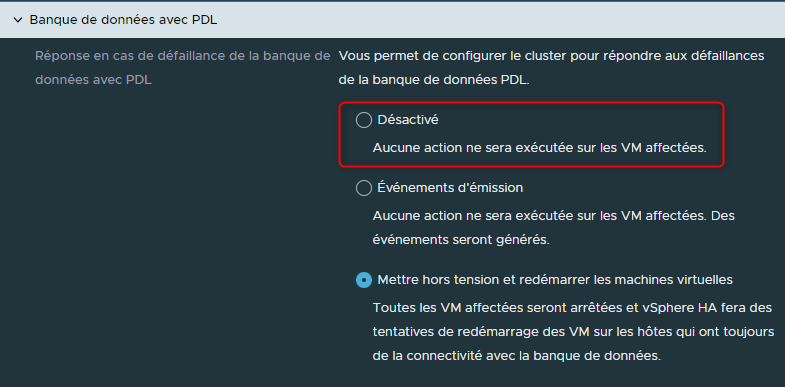
Devons-nous ne rien faire et laisser les VMs en l'état sachant que des VMs qui n'ont plus d'accès à leurs disques durs vont forcément planter ?
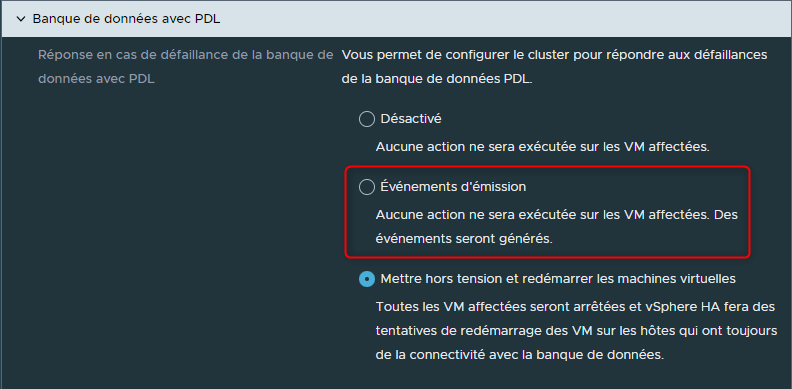
Comme le cas précédent, devons-nous ne rien faire sur les VMs mais simplement générer une alerte ?
Devons-nous arrêter proprement les VMs puis les redémarrer automatiquement sur des hôtes qui ont toujours accès à cette banque de données, évitant que les VMs ne plantent et soient inaccessibles ?
¶ Banque de données avec APD (All-Paths-Down)
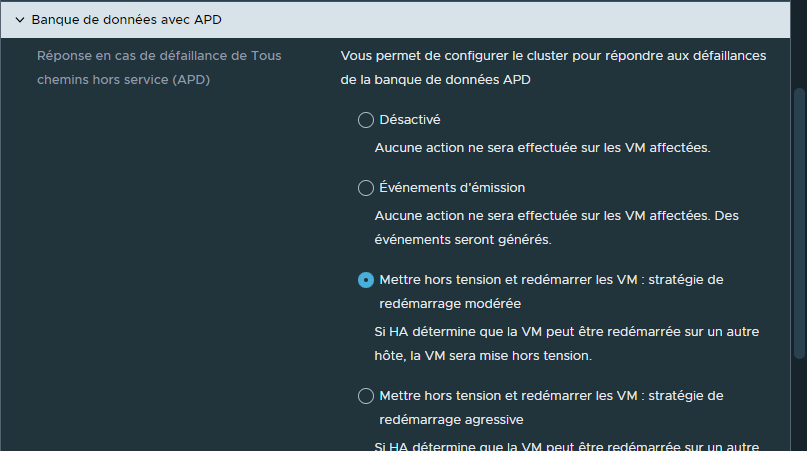
L'option "Banque de données avec APD" est assez similaire à l'option "Banque de données avec PDL".
Il s'agit ici de déterminer ce qui devra être effectuer sur le VMs dans le cas où un ESXi perd la connexion avec l'ensemble des datastores.
Devons-nous ne rien faire ?
Devons-nous générer une alerte et ne rien faire pour les VMS ?
Devons-nous arrêter les Vms puis les redémarrer sur un autre hôte, dans l'hypothèse où elles peuvent être redémarrées sur un autre hôte ?
Devons-nous arrêter de manière agressive les VMs et le redémarrer sur un autre hôte même si vSphere HA ne parvient pas à détecter les ressources nécessaires au reboot sur un autre hôte (dans ce cas les VMs seront uniquement arrêtées) ?
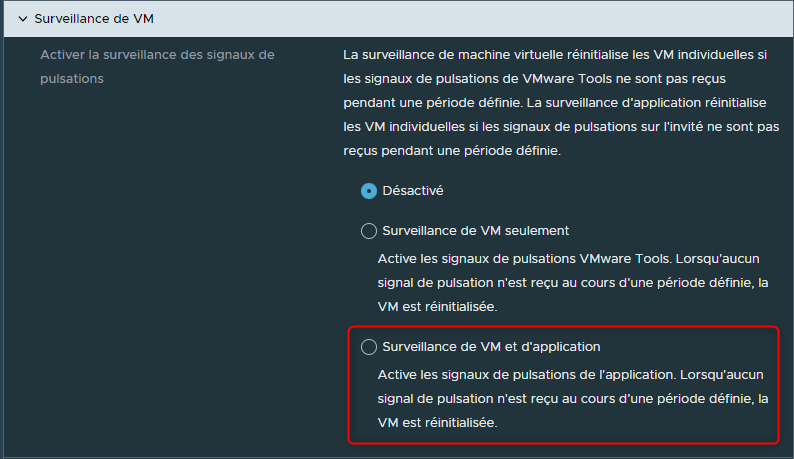
¶ Surveillance de VM

Cette option permet d'activer la surveillance de chacune des VMs individuellement en utilisant les VMWare Tools.
Par exemple nous allons pouvoir déterminer des actions à effectuer si une VM cesse d'envoyer des signaux heartbeat via les VMWare Tools.
Devons-nous ne rien faire ?
Devons-nous réinitialiser la VM sur le même ESXi si aucun signal de heartbeat n'est reçu pendant une période définie ?
Devons-nous activer les signaux de heartbeat sur les applications de la VMs afin de les surveiller et de réinitialiser la VM si aucun signal de heartbeat concernant les applications n'est reçu ?
¶ Configurer le Contrôle d'admission
Pour accéder au contrôle d'admission, il faudra avoir activé vSphere HA puis dans son menu sélectionner "contrôle d'admission"
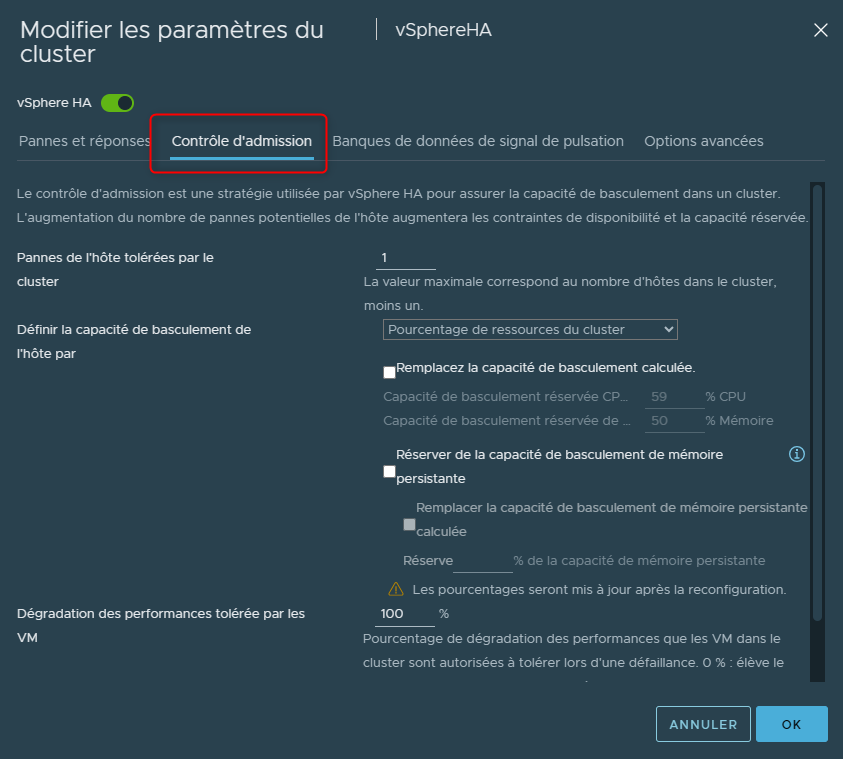
L'objectif du contrôle d’admission est de s’assurer qu’il y ai suffisamment de ressources disponibles pour les VMs d'un Cluster lorsqu'un de ses hôtes ne fonctionne plus.
L'option "Pourcentage de ressources du Cluster" est l'option qui sera activée par défaut en même temps que vSphere HA. Il s'agit également de l'option la plus recommandée.
¶ Pourcentage de ressources du Cluster
Prenons par exemple un Cluster composé de 4 serveurs.
Si l'un d'entre eux ne fonctionne plus, il est impératif que les 3 autres serveurs aient suffisamment de ressources pour supporter la charge des différentes VMs qui étaient sur l'hôte deffectueux.
L'objectif ici est donc de réserver certaines de ces ressources pour garantir qu'en cas de panne d'un hôte, nous ayons suffisamment de ressources pour tolérer la panne.
- La première option du contrôle d’admission correspond au nombre d'hôtes dont nous voulons tolérer la panne.

- La seconde option correspond à la manière dont le Cluster va effectuer la réservation des ressources.
Par défaut, il s'agit en réalité d'un pourcentage des ressources CPU et RAM calculé sur l'ensemble du Cluster.
Ce pourcentage est configuré automatiquement en fonction du nombre d'hôtes dans le Cluster mais également en fonction du nombre d'hôtes que nous avons indiqué dans la première option.
Par exemple si l'on avait un Cluster composé de 10 hôtes nous pourrions définir le nombre d'hôtes en panne sur 3.
Alors le Cluster, via le contrôle d'admission, réserverait sur l'ensemble des hôtes le pourcentage correspondant aux ressources nécessaires pour accomplir cette tolérence de panne.
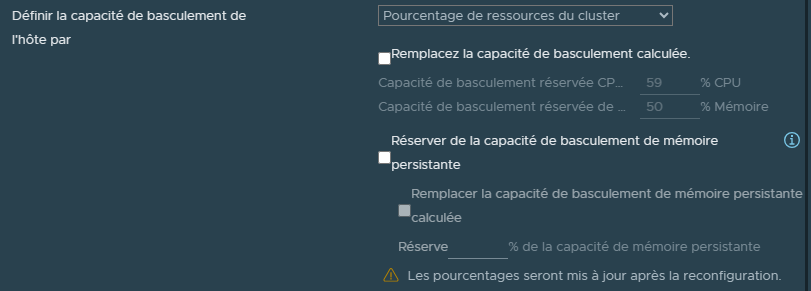
Nous pouvons également définir nous même le pourcentage de ressources à réserver en cas de panne.
Il suffira de cocher la case "Remplacez la capacoté de basculement calculée" et de définir un pourcentage de CPU et un pourcentage de RAm à réserver (attention toute fois à ne pas se tromper).
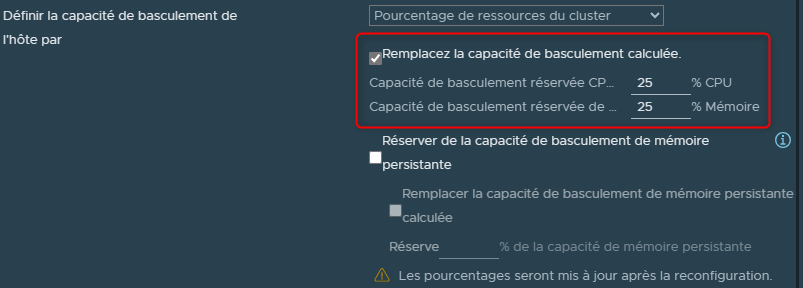
Attention il est essentiel et impératif de comprendre ici la manière dont la réservation des ressources sera calculée car elle ne va pas concerner l'ensemble des VMs du Cluster.
En effet, ce calcul sera basé sur les réservations misent en place sur les machines virtuelles.
Donc si l'on possède un Cluster rempli de VMs sur lesquelles aucune réservation n'est définie, ce que l'on vient de voir ne sera d'aucune utilité et ne nous aidera pas à tolérer la panne d'un ou plusieurs hôtes.
Autrement dit, aucune réservation de ressources ne sera effectuée en cas de panne puisqu'aucune réservation n'a été défini sur les VMs.
C'est ici qu'intervient alors la troisième option appelée "Dégradation des performances tolérée par les VM"
- La troisième option, Dégradation des performances tolérée par les VM.
Ce que l'on souhaite effectuer avec cette option est de s'assurer que nos VMs n'ayant pas de réservations de ressources se porteront bien malgré la panne d'un hôte.
Nous allons donc pouvoir ici définir un seuil de pourcentage de dégradation de performance que les VMs vont tolérées en cas de pannes dans le Cluster.
Ainsi, les ressources globales d'un Cluster seront mieux gérées pour permettre des performances acceptables après une panne d'un hôte.
C'est une option importante à comprendre car si nous avons par exemple l'ensemble des hôtes d'un Cluster qui consomment 80% de leur ressources CPU et RAM, nous allons avoir de sérieux problèmes sur nos VMs sans réservations en cas de panne d'un hôte.
¶ Hôtes de basculement dédiés
Une autre méthode permettant de s'assurer que l'on ai suffisamment de ressources disponibles consiste en l'utilisation d'hôtes dédiées.
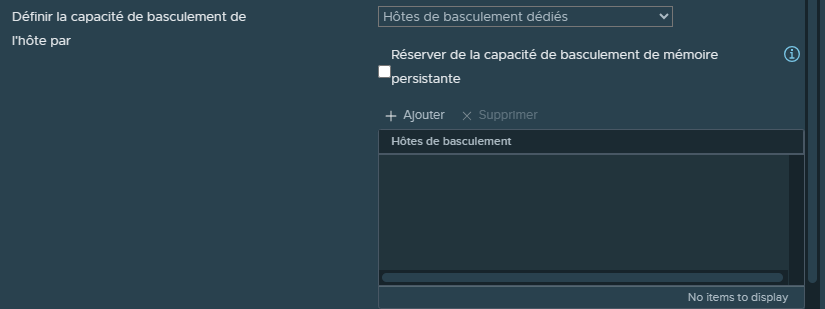
Il s'agit d'hôtes dans un Cluster qui ne feront rien d'autres qu'attendre qu'une panne se produise afin d'héberger les VMs qui étaient sur le ou les hôtes impactés.
Ces hôtes dédiés ne seront en aucun cas utilisés pour héberger des VMs dans des circonstances normales.
Cette méthode n'est pas forcément conseillée puisqu'elle va monopoliser un ou plusieurs hôtes pour rien si aucune panne ne survient, ce qui peu tout de même représenter un coût financier non négligeable (achat des serveurs, des licences, l'électricité, etc).
¶ Stratégie d'emplacements (VM sous tension)
Cette fonctionnalité va être également basée sur les réservations de ressources de nos VMs afin de définir un nombre d'emplacements disponibles pour faire tourner un maximum de VMs.
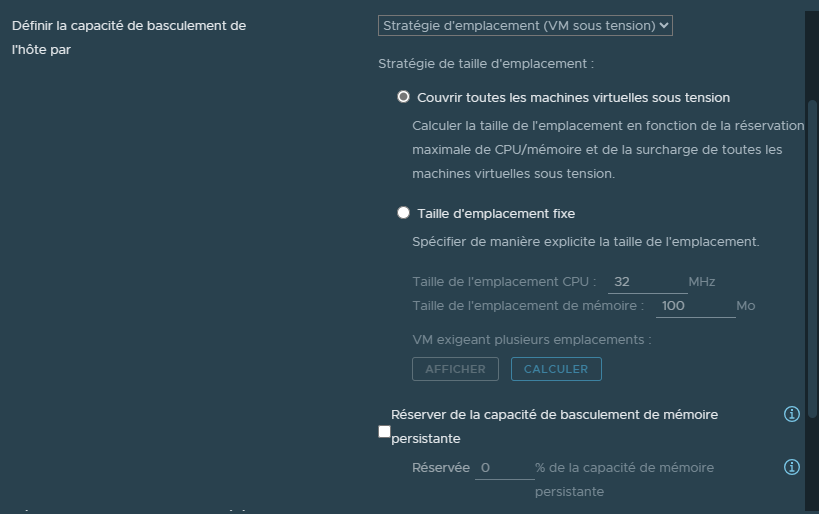
¶ Couvrir toutes les machines virtuelles sous tension
L'option "Couvrir toutes les machines virtuelles sous tension" va examiner la machine virtuelle possédant la plus grande réservation de CPU et de RAM afin d'en faire une "VM de référence".
A partir de celle-ci et en prenant en compte les ressources disponibles du Cluster, cette option va déterminer un nombre d'emplacements possibles qui correspondent chacun à la réservation de CPU et de RAM de notre VM de référence.
Ce nombre d'emplacements sera alors équivalant au nombre de VMs autorisées à s'exécuter dans le Cluster, avec comme principe une VM par emplacement.
Si nous avons plus de VMs que d'emplacement alors certaines d'entre elles ne sont pas autorisées à démarrer et resterons éteintes suite à la panne de leur hôte.
¶ Taille d'emplacement fixe
L'option "Taille d'emplacement fixe" va nous permettre de définir nous même la taille des emplacements.
En définissant une consommation de CPU en Mhz ainsi qu'une consommation de RAM, il sera alors possible de déterminer exactement combien de machines virtuelles pourrons s'exécuter dans le cluster.
Attention cette option peut être compliquée et délicate à gérer puisqu'il ne faut pas se tromper dans le calcule des ressources allouées aux VMs pour définir les emplacements.
De manière générale, utiliser la "Stratégie d'emplacements" n'est pas vraiment conseillé.
Il est très facile de se retrouver dans des situations où l'on manquera d'emplacements disponibles ou alors avec des emplacements mals dimensionnés.
Par exemple des emplacements ayant des ressources trop grandes seront moins nombreux ce qui impliquera alors la possibilité de relancer moins de VMs.
De la même manière des emplacements dont les ressources sont trop petites empêcheront certaines VMs nécessitant plus de ressources que celles disponibles dans l'emplacement de démarrer. Ceci même si le nombre d'emplacements est suffisant par rapport au nombre de VMs à redémarrer.
¶ Désactivé
Comme le nom l'indique, le contrôle d'admission est désactivé et n'interviendra pas en cas de panne d'un hôte.
¶ Configurer les Datastore pour le Heartbeat
Dans cette section de la documentation nous allons voir comment configurer nos "Datastore pour le Heartbeat".
L'objectif de l'utilisation des Datastores pour le Heartbeat est de permettre aux différents hôtes d'un Cluster de déterminer si un hôte qui n'envoi plus de signaux "Heartbeat" sur le réseau "Heartbeat" (management) est toujours Up et fonctionnel ou au contraire s'il n'est plus en capacité d'héberger des VMs.
Par défaut les signaux sont envoyés toutes les secondes.
Pour utiliser et configurer les Datastore pour le Heartbeat il faudra avoir activé vSphere HA puis cliquer sur "Banques de données de signal de pulsation" (Merci la version française, un nom pareil ça ne s'invente pas  ).
).

Le fonctionnement est simple.
Lorsqu'un hôte se trouve isolé du réseau "Heartbeat" et n'est plus en capacité d'émettre ou de recevoir des signaux, il va alors utiliser le ou les Datastore pour le Heartbeat.
Pour se faire il va maintenir un fichier qui sera verrouillé sur le ou les datastores configurés.
Les autres hôtes du Cluster ayant accès à ce ou ces datastores pourront ainsi vérifier la présence du fichier et si celui-ci est bien verrouillé.
S'il est présent et verrouillé dans ce cas cela voudra dire que l'hôte est isolé du réseau "Heartbeat" mais toujours dans un état Up et capable d'héberger ses VMs.
Dans le cas contraire cela voudra dire que l'hôte est en panne et que les VMs qu'il héberge ne sont plus en capacité de tourner.
Nous avons trois possibilités de configuration :
-
Sélectionner automatiquement les banques de données accessibles depuis les hôtes.
Cette configuration permet de laisser vSphere HA définir lui même les datastores à utiliser. -
Utiliser uniquement les banques de données de la liste spécifiée.
Cette configuration permet de définir de manière stricte une liste de datastores à utiliser en les sélectionnant nous même. -
Utiliser les banques de données de la liste spécifiée, puis compléter automatiquement si nécessaire.
Cette configuration permet de définir une liste de datastores à utiliser en les sélectionnant nous même mais tout en laissant à vSphere HA la possibilité d'agrandire cette liste avec d'autres datastores si nécessaire.
La dernière option est de loin la meilleure puisque si l'un des datastores que nous avons sélectionné tombe en panne alors vSphere HA en sélectionnera automatiquement un autre parmis ceux disponibles. De la même manière, si AUCUN des datastores que nous avons défini n'est disponible, vSphere HA sélectionnera automatiquement n'importe quels autres datastores pour effectuer la vérification du "Heartbeat".