¶ Introduction
Dans cette documentation nous allons voir ensemble comment mettre à jour proprement un cluster Proxmox de trois nœuds dans lequel la haute disponibilité est activée (HA).
L'objectif ici est de comprendre l’ordre des opérations, les précautions à prendre et le comportement du cluster pendant la maintenance, notamment grâce à Corosync et au mécanisme de HA.
L'environnement Proxmox que j'utilise pour faire cette documentation est un environneent virtuel.
C'est à dire que les serveurs Proxmox que je vais utiliser sont des VMs cependant la procédure reste identique avec du matériel physique.
¶ Environnement de départ
L'environnement de départ qui sera utilisé pour cette documentation est composé de :
- Un Cluster de 3 nœuds.
- Un HA activé et fonctionnel.
- Aucun QDevice (ce qui est normal dans un cluster 3 nœuds).
Pour rappel, dans cette architecture le quorum est naturellement assuré.
Cela permet de mettre à jour les nœuds un par un sans interruption globale du cluster, à condition de respecter une procédure stricte.
Attention : Je pars du principe que le Cluster est déjà configuré, je ne présenterai pas ici comment le faire.
Pour effectuer les différentes manipulations il est important d'avoir :
- Un accès à l'interface graphique de Proxmox.
- Un accès en SSH aux serveurs Proxmox.
- Un compte ayant suffisament de droits pour effectuer les manipulations.
- Une connectivité réseau stable entre les deux nœuds.
- De préférence une latence faible (idéalement < 5 ms surtout pour de la prod).
¶ Prérequis
¶ Vérification de l’état du cluster
Avant de commencer la mise à jour nous allons dans un premier temps vérifier que le cluster est en bonne santé.
Pour cela, taper la commande suivante :
pvecm status
Cette commande interroge Corosync et affiche :
- le nombre de nœuds.
- le quorum.
- l’état global du cluster.
Le résultat doit impérativement retourner tous les nœuds en ligne et un quorum valide.
Il doit être similaire à celui-ci :
Cluster information
-------------------
Name: cluster-prod
Config Version: 5
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Mon Apr 13 10:15:00 2026
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 0x00000001
Ring ID: 1.123
Quorum: 2
Active: 3
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
1 1 pve1 (local)
2 1 pve2
3 1 pve3
¶ Cluster information
Name: cluster-prod
Transport: knet
- Name correspond au nom du cluster qui a été défini lors de sa création.
- Transport: knet indique que le cluster utilise le protocole réseau moderne de Corosync, plus fiable et performant.
¶ Quorum information
Nodes: 3
Quorum: 2
Active: 3
Cette partie est la plus critique.
- Nodes: 3 : nombre total de nœuds configurés.
- Quorum: 2 : nombre minimum de votes nécessaires.
- Active: 3 : nombre de nœuds actuellement actifs.
Ici le cluster est en parfaite santé car tous les nœuds sont présents et le nombre de nœuds actifs est supérieur au quorum.
¶ Votequorum information
Expected votes: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Cette section confirme le fonctionnement du mécanisme de vote.
- Expected votes : nombre de votes attendus.
- Total votes : nombre de votes réellement disponibles.
- Quorum : seuil minimum.
- "Flags: Quorate" : indique l'état du cluster.
Le fait que "**Flags" soit défini sur "Quorate" signifie que le cluster est autorisé à fonctionner et à prendre des décisions.
Si Non-quorate est visible, alors le cluster est bloqué et ne fonctionne pas correctement.
¶ Membership information
Nodeid Votes Name
1 1 pve1 (local)
2 1 pve2
3 1 pve3
Cette section liste tous les nœuds du cluster.
- Chaque nœud possède :
- un ID unique
- un nombre de votes (généralement 1)
- un nom
- (local) indique le nœud sur lequel la commande est exécutée.
Cette section permet de vérifier rapidement que tous les nœuds sont présents et qu’aucun nœud n’est hors ligne.
¶ Vérifier l’état du HA
Nous allons en suite vérifier l'état de santé du HA à l'aide de la commande suivante :
ha-manager status
Cette commande interroge le système de haute disponibilité de Proxmox.
Celui-ci repose sur plusieurs composants internes qui communiquent via Corosync.
Le résultat attendu doit être similaire à celui-ci :
quorum OK
master pve1 (active, Fri Apr 14 10:20:15 2026)
lrm pve1 (active, Fri Apr 14 10:20:14 2026)
lrm pve2 (active, Fri Apr 14 10:20:13 2026)
lrm pve3 (active, Fri Apr 14 10:20:12 2026)
service vm:100 (pve1, started)
service vm:101 (pve2, started)
service vm:102 (pve3, started)
¶ État du quorum HA
quorum OK
Cette ligne indique que le cluster est dans un état valide du point de vue du HA.
Cela signifie que :
- le cluster dispose du quorum.
- les décisions HA peuvent être prises.
- les actions automatiques (restart, migration) sont autorisées.
Si cette ligne indique autre chose comme par exemple quorum lost alors le HA ne fonctionnera pas correctement.
¶ Nœud master (CRM)
master pve1 (active, Fri Apr 14 10:20:15 2026)
Le master correspond au nœud qui exécute le CRM (Cluster Resource Manager).
Son rôle est de :
- prendre les décisions globales
- déterminer où les VM doivent être exécutées
- orchestrer les redémarrages en cas de panne
ATTENTION : le master peut changer automatiquement en cas de panne.
¶ LRM (Local Resource Manager)
lrm pve1 (active, Fri Apr 14 10:20:14 2026)
lrm pve2 (active, Fri Apr 14 10:20:13 2026)
lrm pve3 (active, Fri Apr 14 10:20:12 2026)
Chaque nœud possède un LRM.
Le LRM est responsable de :
- exécuter les actions localement
- démarrer ou arrêter les VM
- appliquer les décisions du CRM
¶ Services HA (machines virtuelles)
service vm:100 (pve1, started)
service vm:101 (pve2, started)
service vm:102 (pve3, started)
Cette section liste les ressources gérées par le HA.
Chaque ligne contient :
- l’identifiant de la VM (vm:100)
- le nœud sur lequel elle tourne
- son état
L’état "started" signifie :
- la VM est en cours d’exécution
- elle est conforme à la politique HA
¶ Mise en maintenance d’un nœud
Avant de mettre à jour un nœud, il est indispensable de s’assurer qu’il ne va pas impacter les services en production.
L’objectif est de vider ce nœud de ses charges de travail, c’est-à-dire des machines virtuelles qu’il héberge.
ATTENTION : L'environnement que j'utilise pour faire cette documentation est virtuel.
Je n'ai pas créé de VMs pour cette documentation, je ne ferai donc pas de carpture d'écran.
Je me contenterai de donner les commandes en exemple.
¶ Migration des machines virtuelles
- Migrer les VMs vers les autres nœuds du cluster en utiliant cette commande :
qm migrate <vmid> <node>
Cette commande permet de déplacer une machine virtuelle vers un autre nœud.
Selon la configuration du stockage cette migration peut être faite :
- à chaud (sans interruption).
- à froid et nécessiter un arrêt de la VM.
Il est important de vérifier que toutes les VM ont bien été déplacées avant de continuer.
¶ Mise en mode maintenance via HA
lorsque le serveur ne porte plus de VM il faut indiquer au HA de ne plus utiliser ce nœud.
Pour cela nous utiliserons la commande suivante :
ha-manager crm-command node-maintenance enable <node>

Cette commande modifie l’état du nœud dans la configuration HA.
Concrètement, cela signifie que :
- aucune VM ne sera redémarrée dessus.
- le cluster ne le considérera plus comme disponible pour héberger des ressources.
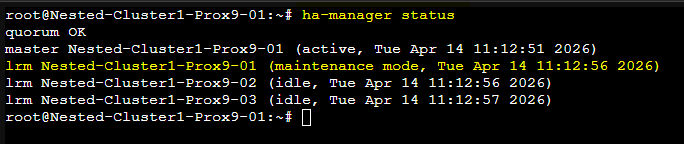
On peut vérifier l'état du nœud et confirmer qu'il est en mode maintenance avec la commande suivante :
ha-manager status
¶ Mise à jour du nœud
¶ Mise à jour des paquets
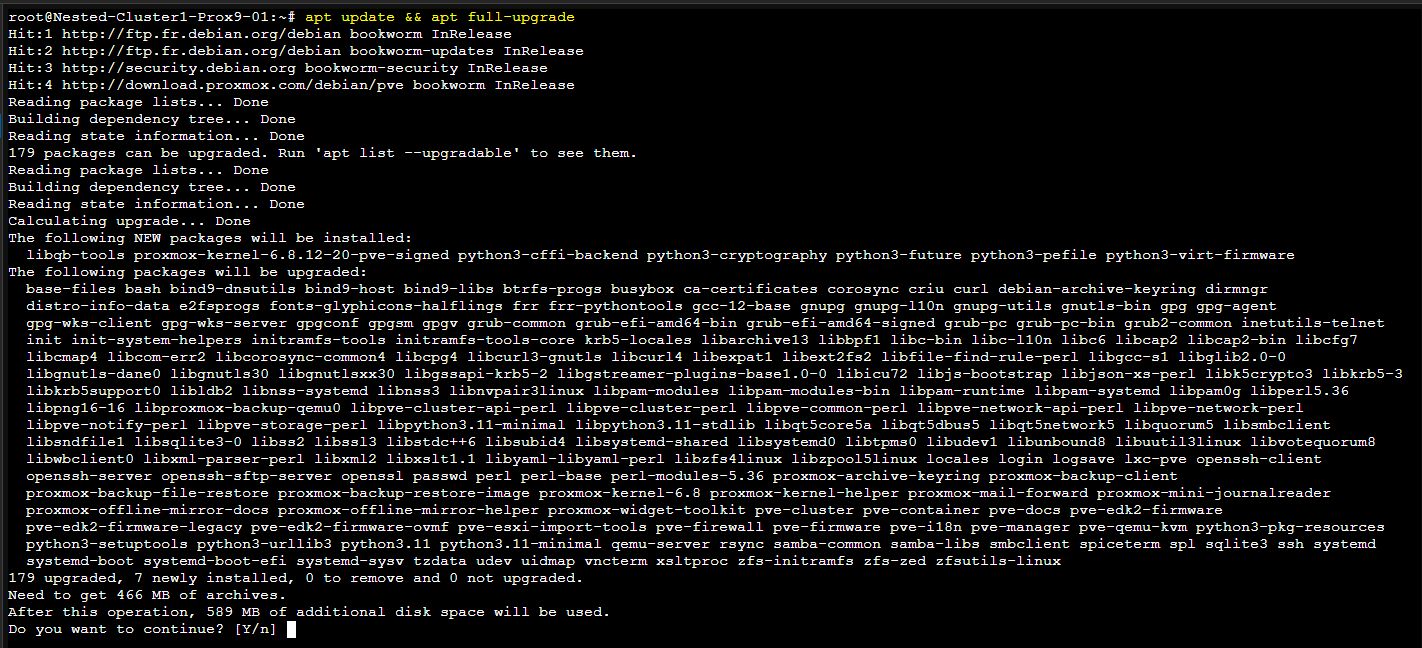
- Mettre à jour les packages avec les commande suivantes :
apt update && apt full-upgrade
La commande apt full-upgrade est particulièrement importante.
Contrairement à apt upgrade, elle permet :
- d’installer de nouveaux paquets si nécessaire
- de supprimer des paquets obsolètes
- de gérer les dépendances complexes
Cela garantit une mise à jour complète du système.
- Valider par "y" lorsque c'est demandé.
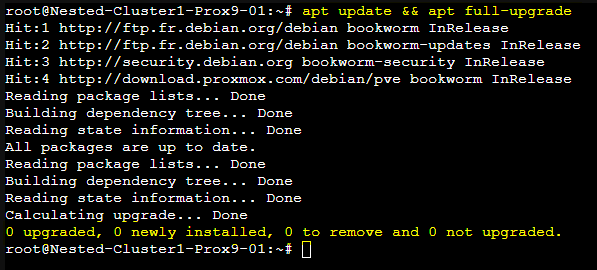
- Puis attendre la fin des mises à jour.

- On peut vérifier que tout est à jour en retapant les commandes.
¶ Redémarrage du nœud
- Redémarrer le serveur
reboot
Cela permettra de charger :
- le nouveau kernel
- les nouveaux services
AVANT
APRES
¶ Remise en production du nœud
Après avoir fait les mise sà jour et le reboot du serveur il faut le remettre en production.
Pour cela nous allons utiliser la commande suivante :
ha-manager crm-command disable-maintenance disable <node>
Cela permet au cluster de réutiliser ce nœud pour héberger des VM.

Vérifier à nouveau le statut du nœud :
ha-manager status
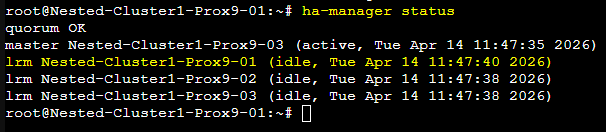
ATTENTION : Lorsque l'intervention sur le premier serveur est terminée, il faudra la refaire sur chacun des serveurs du Cluster pour que l'ensemble soit à jour dans la même version.
¶ Tips
Pendant toute la procédure, il faut être particulièrement attentif à plusieurs points.
Il ne faut JAMAIS :
- mettre à jour plusieurs nœuds simultanément.
- ignorer les alertes du cluster.
Corosync joue un rôle critique. Toute interruption multiple peut provoquer une perte de quorum et bloquer le cluster.