¶ Introduction
Dans cette documentation nous allons voir ensemble comment créer un cluster Proxmox avec trois nœuds.
Le but étant de mettre en place un cluster fiable et tolérant aux pannes.
Un cluster Proxmox repose sur le moteur Corosync, qui assure :
- La communication entre les nœuds.
- La gestion du quorum.
- La détection des pannes.
Nous mettrons également en place la haute disponibilité (HA) afin que les machines virtuelles puissent redémarrer automatiquement en cas de défaillance d’un nœud.
L'environnement Proxmox que j'utilise pour faire cette documentation est un environneent virtuel.
C'est à dire que les serveurs Proxmox que je vais utiliser sont des VMs cependant la procédure reste identique avec du matériel physique.
¶ Prérequis
- Trois serveurs (physiques ou VMs)
- Même version de Proxmox VE sur les trois nœuds
- Avoir accès à l'interface graphique de Proxmox.
- Avoir accès en SSH aux serveurs Proxmox.
- Un compte ayant suffisament de droits pour effectuer les manipulations.
- Une connectivité réseau stable entre les deux nœuds
- De préférence une latence faible (idéalement < 5 ms surtout pour de la prod)
- Débit recommandé : 1 Gbps minimum (10 Gbps idéal)
- Nom d’hôte correctement défini
- Résolution DNS ou /etc/hosts fonctionnelle (important)
¶ QDevice
Avant de commencer la configuration nous allons parler un peu du QDevice.
Dans beaucoup de labs ou de petites infrastructures, il n'est pas rare de trouvever un ou plusieurs Cluster avec seulement deux nœuds pour lesquels il est vivement conseillé de mettre en place un QDevice.
J'ai d'ailleurs fais une documentation qui traite du sujet.
Cependant dans cette documentation nous allons créer un cluster avec 3 nœuds.
La question qui se pose est donc assez simple : Faut-il configurer un QDevice dans un cluster 3 nœuds ?
La réponse est tout aussi simple : Dans un cluster à trois nœuds l’ajout d’un QDevice n’est pas nécessaire.
En effet, chaque nœud possède un vote, ce qui donne un total de trois votes.
Le quorum, qui correspond à la majorité nécessaire pour que le cluster fonctionne, est donc de deux votes.
Cela signifie concrètement que si un nœud tombe en panne, les deux nœuds restants continuent de fonctionner normalement, car ils conservent la majorité.
Il existe donc déjà un mécanisme d’arbitrage naturel et le risque de split-brain est fortement réduit
Je ne traiterai donc pas ici de la configuration d'un QDevice car ce n'est pas nécessaire.
¶ Configuration du réseau
¶ Architecture réseau recommandée
Idéalement il faut à minima deux interfaces réseau sur les serveurs Proxmox :
- 1 interface pour le management
- 1 interface dédiée au cluster (Corosync)
Exemple :
| Usage | Interface | IP |
|---|---|---|
| Management | vmbr0 | 192.168.60.x |
| Cluster | vmbr1 | 192.168.70.x |
Cette configuration sera a réaliser sur chacun des nœuds qui composeront le Cluster.
¶ Configuration des interfaces
Voici un exemple de la configuration réseau nécessaire pour créer le Cluster.
On y retrouvera nos deux cartes réseau ainsi que les subnets dédiés à chacune d'elles.
Cette configuration est à mettre dans /etc/network/interfaces et sera a faire sur les trois serveurs en prennant évidemment soin de ne pas utiliser les mêmes adresses.
auto lo
iface lo inet loopback
iface ens192 inet manual
iface ens224 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.60.1/24
gateway 192.168.60.254
bridge-ports ens192
bridge-stp off
bridge-fd 0
auto vmbr1
iface vmbr1 inet static
address 192.168.70.1/24
bridge-ports ens224
bridge-stp off
bridge-fd 0
¶ Configuration du Cluster
¶ En CLI
¶ Configuration
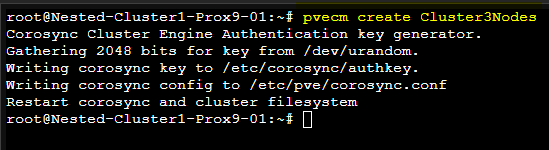
Pour créer le Cluster en utiliant les lignes de commande (CLI) il faudra effectuer la commande suivante depuis le premier serveur Proxmox:
# Sur le premier serveur Proxmox
pvecm create Cluster-Name
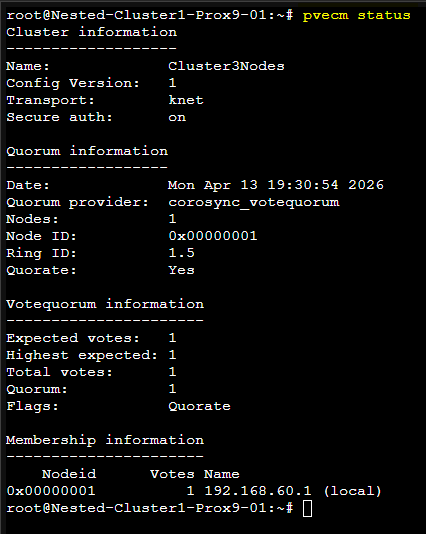
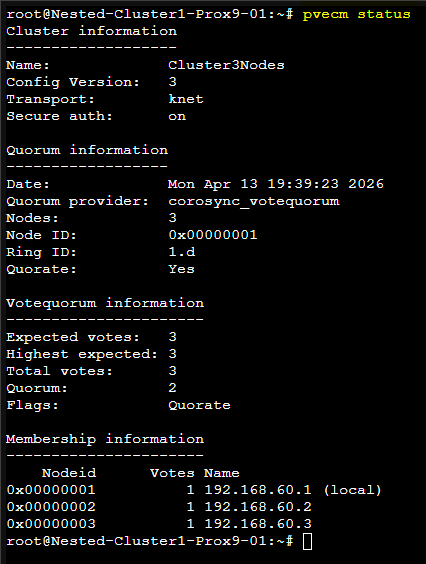
Une fois la commande passée on peut vérifier que le Cluster est correctement créé à l'aide de la commande suivante : pvecm status
Le résultat sera comme ceci :
Le cluster étant créé, il faut à présent y ajouter les deux autres serveurs :
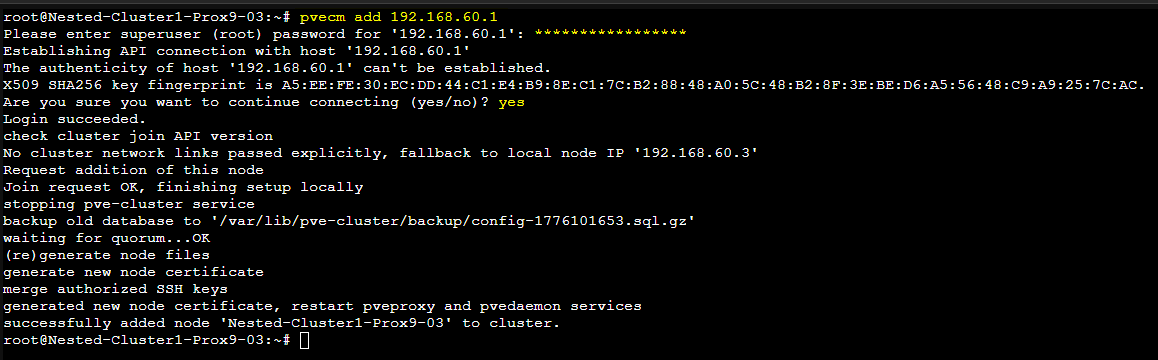
# Sur le second serveur Proxmox
pvecm add 192.168.60.1 # adresse IP du premier serveur PVE
# Sur le troisème serveur Proxmox
pvecm add 192.168.60.1 # adresse IP du premier serveur PVE
Il faudra entrer le password du compte root du premier serveur Proxmox puis valider en tapant "yes"
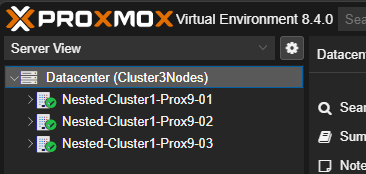
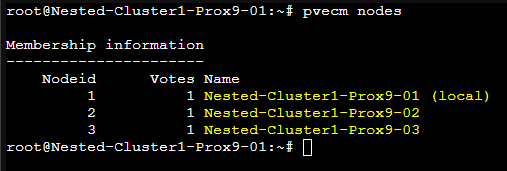
Après avoir ajouté les deux autres serveurs Proxmox au Cluster, ils seront tous visibles dans le Datacenter depuis n'importe quelle interface graphique.
Il sera également possible de vérifier le Cluster avec les commandes suivantes :
pvecm nodes
pvecm status
¶ Modification du lien Corosync
Nous venons créer un Cluster et d'y ajouter nos 3 nœuds cependant le réseau utilisé ne correspond pas à celui que nous avons configuré et qui sera dédié à Corosync.
Pour utiliser le réseau dédié nous allons devoir faire quelques modifications.
- Editer le fichier
/etc/pve/corosync.conf
Dans la partie "nodelist", modifier l'adresse ip par celle du réseau dédié.
AVANT
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.60.1
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.60.2
}
node {
name: Nested-Cluster1-Prox9-03
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.60.3
}
}
APRES
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.70.1 # <== ICI
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.70.2 # <== ICI
}
node {
name: Nested-Cluster1-Prox9-03
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.70.3 # <== ICI
}
}
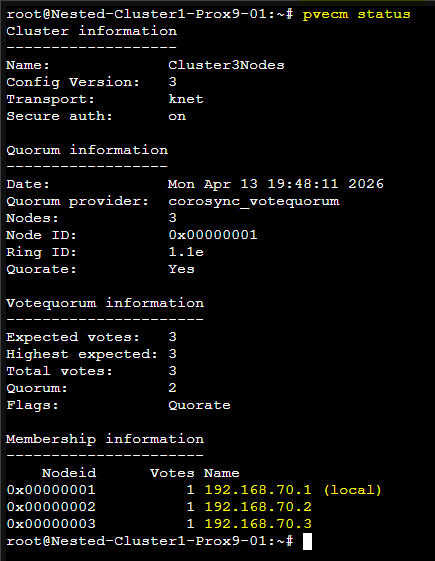
ATTENTION : Pour la modification soit prise en compte il faudra redémarrer les deux PVE.
¶ Vérifications
Nous pouvons vérifier que la modification a bien été prise en compte en utilisant à nouveau la commande pvecm status
¶ En mode graphique
¶ Sur le premier serveur Proxmox.
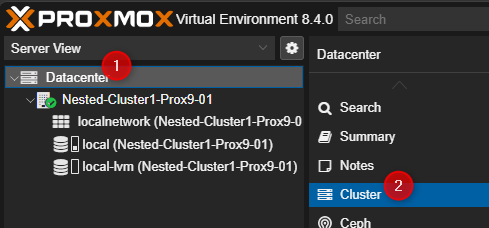
- Cliquer sur Dataceter puis cliquer sur Cluster.
- Dans la partie de droite cliquer sur "Create Cluster".
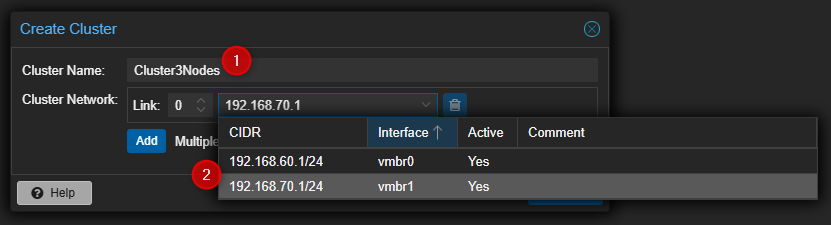
- Entrer un nom pour le Cluster et sélectionner l'interface qui sera utilisée pour les communications du Cluster.
- Cliquer sur "Create" pour valider la création.
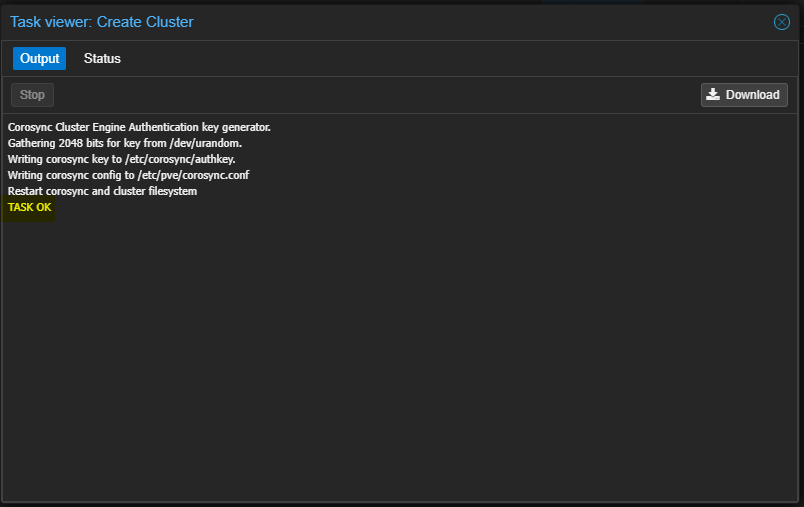
- Attendre la fin de la tâche de création.
- Le Cluster sera visible dans la partie de droite.
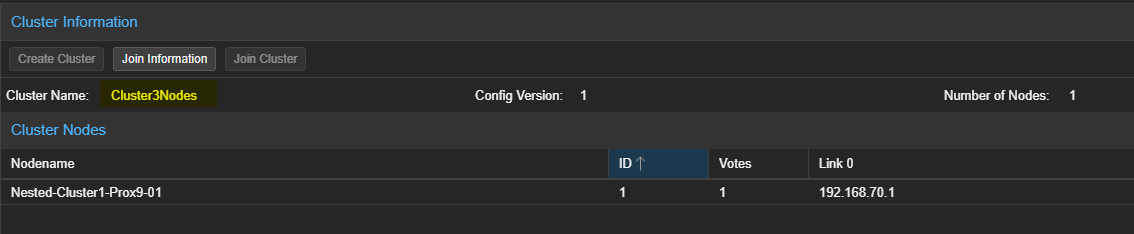
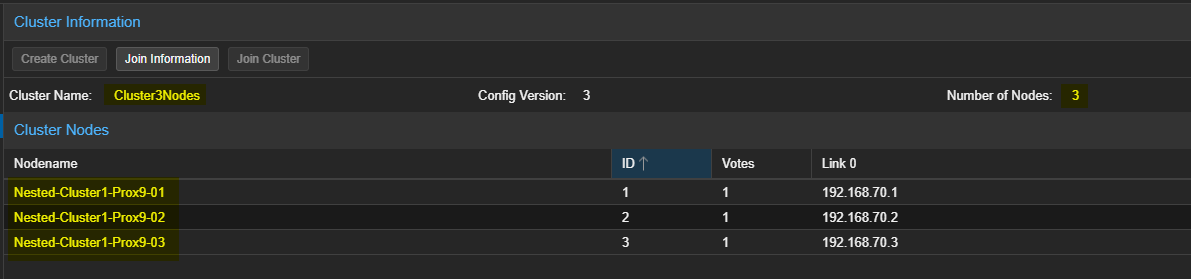
- Récupérer les informations permettant de joindre le Cluster.
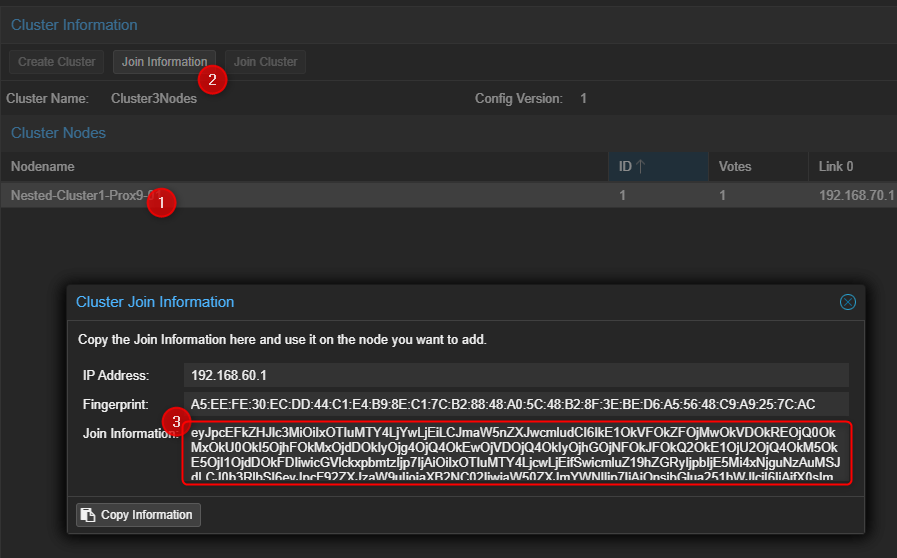
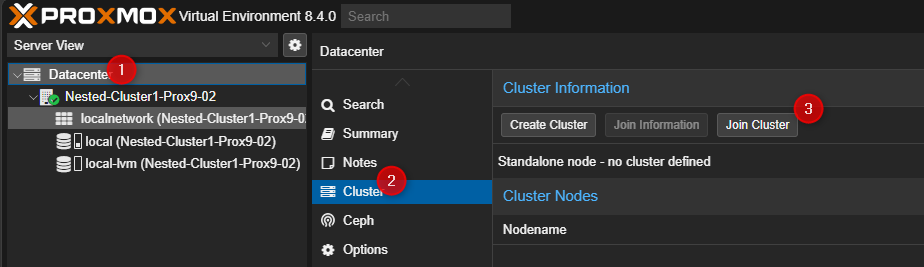
¶ Sur le second et le troisième serveur Proxmox.
- Cliquer sur Dataceter puis sur Cluster et pour terminer sur "Join Cluster" dans la partie de droite.
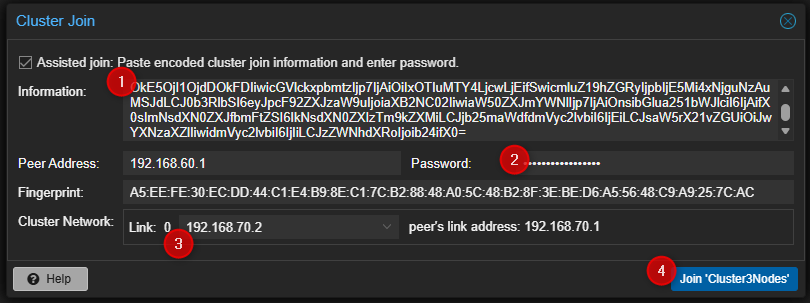
- Entrer les liens d'accès au cluster, le password du compte root du premier serveur PVE, sélectionner l'interface qui sera utilisée pour le cluster puis cliquer sur "Join" en bas à droite.
- Attendre la fin de la tâche puis vérifier que le serveur a bien été join au Cluster.
¶ Activation de la haute disponibilité (HA)
- Se connecter en SSH sur chacun des nœuds puis taper les commandes suivantes :
systemctl enable pve-ha-lrm
systemctl enable pve-ha-crm
systemctl start pve-ha-lrm
systemctl start pve-ha-crm
Ces services sont indispensables au fonctionnement du HA.
Le service pve-ha-crm prend les décisions globales. Il analyse l’état du cluster et décide où les machines doivent être exécutées.
Le service pve-ha-lrm, quant à lui, exécute les actions localement sur chaque nœud.
Ces deux services communiquent via Corosync.
¶ Configuration du HA
¶ Fichiers de configuration
Tous les fichiers du HA sont dans le répertoire /etc/pve/ha/
- Fichier resources.cfg : /etc/pve/ha/resources.cfg
Ce fichier définit :- Les VM gérées en HA
- Leur comportement
- Fichier manager_status : /etc/pve/ha/manager_status
Ce fichier contient l’état interne du cluster HA (Il ne pas modifier manuellement)
¶ Ajout d’une VM en HA
Je n'ai pas créé de VM pour cette documentation, je ne ferai donc pas de carpture d'écran.
Je me contenterai de donner les commandes en exemple
- Ajout du HA sur une VM
ha-manager add vm:100
- Vérification du HA sur une VM
ha-manager status
- Modification des paramètres
ha-manager set vm:100 --max_restart 5 --max_relocate 2
¶ Test de fonctionnement
¶ Simulation d’une panne
Il est possible de simuler une panne en arrêtant un nœud :
shutdown now
¶ Comportement attendu
Lorsque le nœud s’arrête :
- Corosync détecte la perte
- Le quorum reste valide (2 nœuds actifs)
- Le HA redémarre les VM sur un autre nœud