¶ Introduction
Dans cette documentation nous allons voir ensemble comment mettre en place une infrastructure HCI (Hyper-Converged Infrastructure) basée sur un cluster Proxmox VE composé de trois nœuds utilisant un stockage Ceph.
L'environnement Proxmox que j'utilise pour faire cette documentation est un environneent virtuel.
C'est à dire que les serveurs Proxmox que je vais utiliser sont des VMs cependant la procédure reste identique avec du matériel physique.
¶ Objectifs
L'objectif de cette documentation est de montrer les différentes étapes de la préparation des serveurs jusqu’à la mise en place afin d'obtenir :
- un cluster Proxmox centralisé.
- un stockage partagé et répliqué entre les nœuds.
- des migrations live des VMs.
- de la haute disponibilité (HA).
- une infrastructure capable de survivre à la perte d’un serveur.
¶ Comprendre l’architecture
¶ Vue d'ensemble
Avant de commencer l’installation, il est important de comprendre l’architecture que nous allons mettre en place.
Dans une architecture HCI basée sur Ceph :
- chaque serveur participe aux calculs.
- chaque serveur participe au stockage.
- les données sont répliquées automatiquement entre les nœuds.
Cela signifie qu’il n’est plus nécessaire d’utiliser un SAN externe, une baie de stockage dédiée ou un NAS centralisé.
Chaque nœud devient donc à la fois :
- un hyperviseur.
- un nœud de stockage.
- un membre du cluster.
¶ L'architecture
Afin de respecter les bonnes pratiques je vais séparer les réseaux que j'utiliserai.
En effet, il est particulièrement recommandé d'avoir un réseau dédié pour Corosync qui gère le cluster dans Proxmox VE mais également pour Ceph dont le trafic génère énormément d’échanges sur le réseau.
Voici la configuration des serveurs que je vais utiliser :
| Nœuds | Hostname | IP Management | IP Cluster (Corosync) | IP Ceph | CPU | RAM |
|---|---|---|---|---|---|---|
| Node 1 | Nested-Cluster1-Prox9-01 | 192.168.60.1 | 192.168.70.1 | 192.168.90.1 | 6 | 12Go |
| Node 2 | Nested-Cluster1-Prox9-02 | 192.168.60.2 | 192.168.70.2 | 192.168.90.2 | 6 | 12Go |
| Node 3 | Nested-Cluster1-Prox9-03 | 192.168.60.3 | 192.168.70.3 | 192.168.90.3 | 6 | 12Go |
Réseau de Management :
- l’administration web Proxmox.
Réseau du Cluster (Corosync) :
- la communication du cluster.
- le quorum.
- les migrations live.
Réseau pour Ceph :
- la réplication Ceph.
- la synchronisation des données.
- les échanges entre OSD.
ATTENTION : En prod il serait tout à fait possible de séparer un peu plus les flux et de définir des réseaux dédiés selon les utilisations.
¶ Prérequis
- Trois serveurs Proxmox (physiques ou VMs).
- Même version de Proxmox VE sur les trois nœuds.
- Avoir accès à l'interface graphique et au SSH de Proxmox.
- Une connectivité réseau stable entre les deux nœuds.
- De préférence une latence faible (idéalement < 5 ms surtout pour de la prod).
- Débit recommandé : 1 Gbps minimum (10 Gbps idéal).
- Nom d’hôte correctement défini.
- Résolution DNS ou /etc/hosts fonctionnelle (important).
- Un compte ayant suffisament de droits pour effectuer les manipulations.
- Avoir plusieurs disques sur les seveurs pour la mise en place de Ceph.
- Avoir de préférence des réseaux dédiés aux différents services.
ATTENTION : Je ne montrerai pas comment faire l'installation des serveurs Proxmox. Je pars du principe que les deux serveurs sont déjà installés.
¶ QDevice
Avant de commencer la configuration nous allons parler un peu du QDevice.
Dans beaucoup de labs ou de petites infrastructures, il n'est pas rare de trouvever un ou plusieurs Cluster avec seulement deux nœuds pour lesquels il est vivement conseillé de mettre en place un QDevice.
J'ai d'ailleurs fais une documentation qui traite du sujet.
Cependant dans cette documentation nous allons créer un cluster avec 3 nœuds.
La question qui se pose est donc assez simple : Faut-il configurer un QDevice dans un cluster 3 nœuds ?
La réponse est tout aussi simple : Dans un cluster à trois nœuds l’ajout d’un QDevice n’est pas nécessaire.
En effet, chaque nœud possède un vote, ce qui donne un total de trois votes.
Le quorum, qui correspond à la majorité nécessaire pour que le cluster fonctionne, est donc de deux votes.
Cela signifie concrètement que si un nœud tombe en panne, les deux nœuds restants continuent de fonctionner normalement, car ils conservent la majorité.
Il existe donc déjà un mécanisme d’arbitrage naturel et le risque de split-brain est fortement réduit
Je ne traiterai donc pas ici de la configuration d'un QDevice car ce n'est pas nécessaire.
¶ Configuration du réseau
¶ Architecture réseau recommandée
Idéalement il faut à minima deux interfaces réseau sur les serveurs Proxmox :
- 1 interface pour le management
- 1 interface dédiée au cluster (Corosync)
- 1 interface dédiée à Ceph
Exemple :
| Usage | Interface | IP |
|---|---|---|
| Management | vmbr0 | 192.168.60.x |
| Cluster | vmbr1 | 192.168.70.x |
| Cluster | vmbr2 | 192.168.90.x |
¶ Configuration des interfaces
Voici un exemple de la configuration réseau nécessaire pour créer le Cluster.
On y retrouvera nos trois cartes réseau ainsi que les subnets dédiés à chacune d'elles.
Cette configuration est à mettre dans /etc/network/interfaces et sera a faire sur les trois serveurs en prennant évidemment soin de ne pas utiliser les mêmes adresses sur les trois nœuds.
auto lo
iface lo inet loopback
iface nic0 inet manual
iface ens224 inet manual
iface ens256 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.60.1/24
gateway 192.168.60.254
bridge-ports nic0
bridge-stp off
bridge-fd 0
auto vmbr1
iface vmbr1 inet static
address 192.168.70.1/24
bridge-ports ens224
bridge-stp off
bridge-fd 0
auto vmbr2
iface vmbr2 inet static
address 192.168.90.1/24
bridge-ports ens256
bridge-stp off
bridge-fd 0
¶ Vérification des serveurs
Avant de commencer la configuration nous allons procéder à quelques vérifications sur nos trois serveurs Proxmox.
Il est impératif que les serveurs soient correctement configurés et qu'ils puissent communiquer ensemble sur le réseau.
Personnellement je vais le faire en SSH sur les serveurs mais il est tout à fait possible de le faire depuis le shell de l'interface graphique.
¶ Configuration des hostname
- Vérifier que le nom du serveur soit correctement configuré dans le fichier /etc/hostname.
Si ce n'est pas le cas modifier le fichier.
nano /etc/hostname

- Exemple de contenu
¶ Configuration du fichier hosts
- Vérifier que le fichier hosts soit correctement configuré.
Si ce n'est pas le cas modifier le fichier.
nano /etc/hosts

- Exemple de contenu

¶ Vérification réseau
Je vais utiliser deux réseaux pour avoir deux liens pour corosync.
Je vais donc vérifier que les deux serveurs puissent comminiquer sur ces deux réseaux.
- Sur le premier serveur :
# Fichier hosts
ping Nested-Cluster1-Prox9-02
ping Nested-Cluster1-Prox9-03
# Second réseau pour corosync
ping 192.168.70.2
ping 192.168.70.3
# Second réseau pour Ceph
ping 192.168.90.2
ping 192.168.90.3
- Sur le second serveur :
# Fichier hosts
ping Nested-Cluster1-Prox9-01
ping Nested-Cluster1-Prox9-03
# Second réseau pour corosync
ping 192.168.70.1
ping 192.168.70.3
# Second réseau pour Ceph
ping 192.168.90.1
ping 192.168.90.3
- Sur le troisème serveur :
# Fichier hosts
ping Nested-Cluster1-Prox9-01
ping Nested-Cluster1-Prox9-02
# Second réseau pour corosync
ping 192.168.70.1
ping 192.168.70.2
# Second réseau pour Ceph
ping 192.168.90.1
ping 192.168.90.2
ATTENTION : Le cluster Corosync dépend fortement de la résolution DNS/hosts et de la stabilité du réseau.
¶ Mise à jour des systèmes
- Nous allons effectuer les mises à jour sur chacun des serveurs.
apt update && apt full-upgrade
- Faire un reboot des serveurs après les mises à jour
reboot
¶ Création du cluster Proxmox
¶ En mode graphique
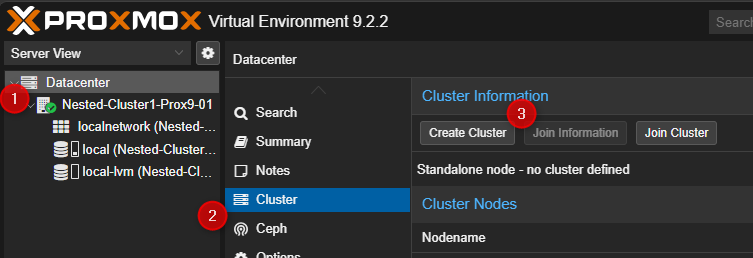
¶ Sur le premier serveur Proxmox.
- Cliquer sur Dataceter puis cliquer sur Cluster. Dans la partie de droite cliquer sur "Create Cluster".
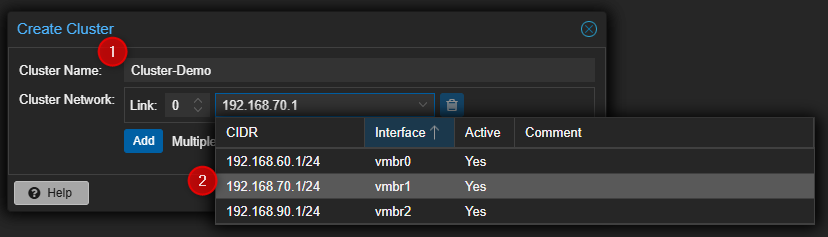
- Entrer un nom pour le Cluster et sélectionner l'interface qui sera utilisée pour les communications du Cluster.
- Cliquer sur "Create" pour valider la création.
- Attendre la fin de la tâche de création.
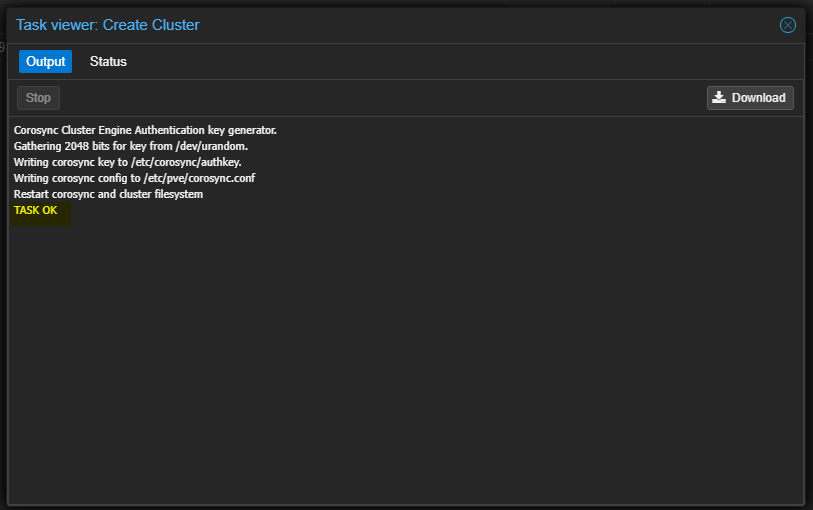
- Le Cluster sera visible dans la partie de droite.

- Récupérer les informations permettant de joindre le Cluster.
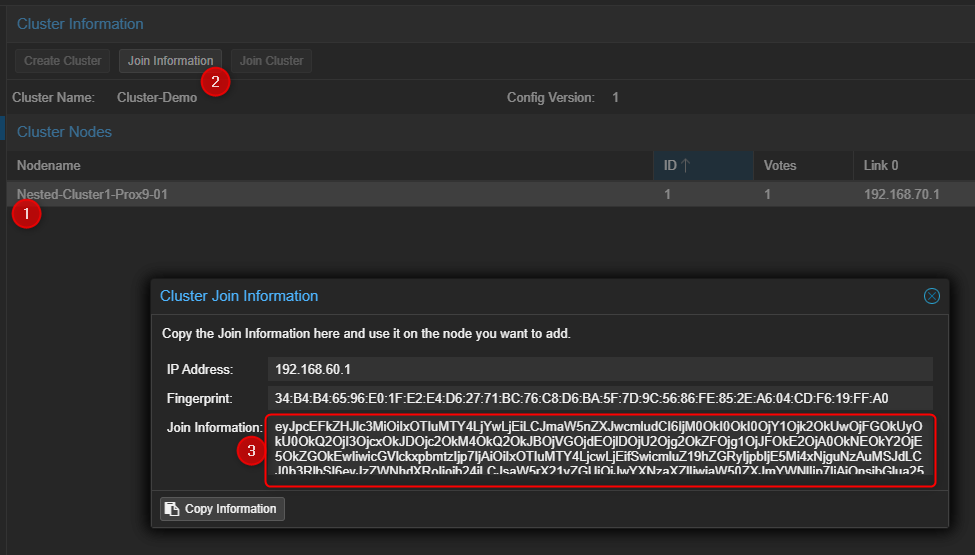
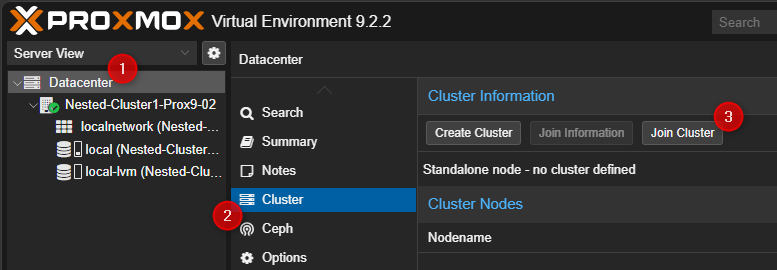
¶ Sur les autres serveur Proxmox.
- Cliquer sur Dataceter puis sur Cluster et pour terminer sur "Join Cluster" dans la partie de droite.
- Entrer les liens d'accès au cluster, le password du compte root du premier serveur PVE, sélectionner l'interface qui sera utilisée pour le cluster puis cliquer sur "Join" en bas à droite.
Depuis le deuxième serveur PVE :
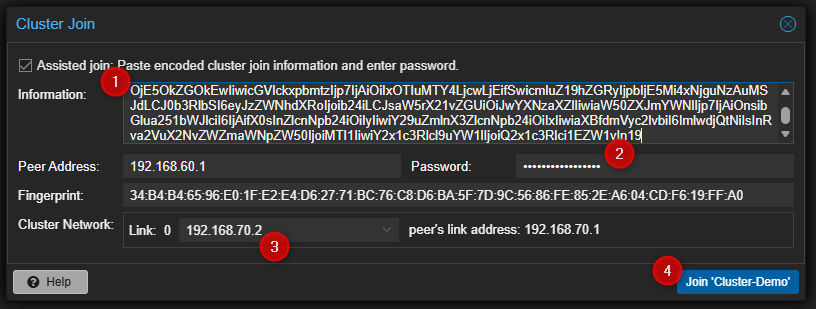
Depuis le troisième serveur PVE :
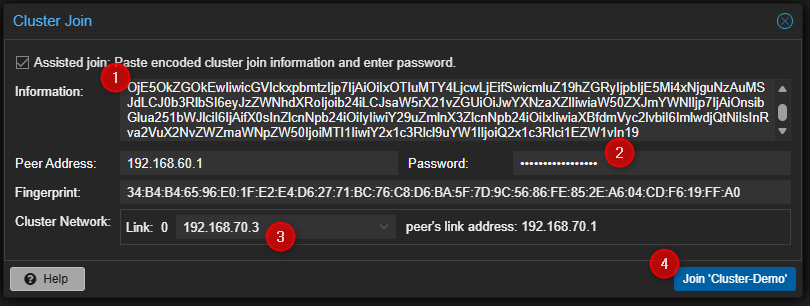
- Attendre la fin de la tâche puis vérifier que le serveur a bien été join au Cluster.
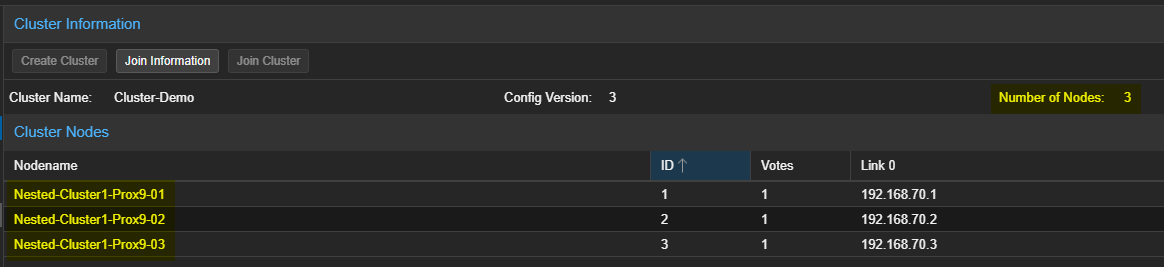
¶ En CLI
¶ Configuration
Pour créer le Cluster en utiliant les lignes de commande (CLI) il faudra effectuer les manipulations suivantes :
# Sur le premier serveur Proxmox
pvecm create Cluster-Demo
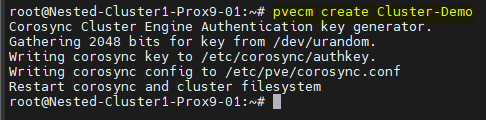
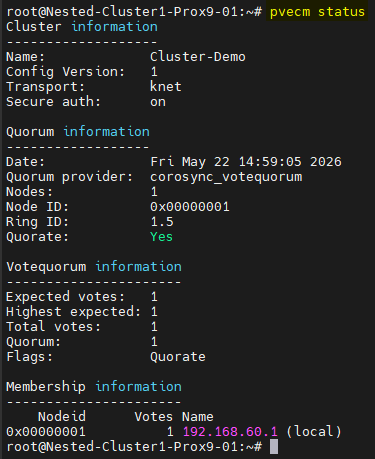
Une fois la commande passée on peut vérifier que le Cluster est correctement créé à l'aide de la commande suivante : pvecm status
Le résultat sera comme ceci :
Une fois le Cluster créé il faudra en suite ajouter les autres serveurs Proxmox.
# Sur les deux autres serveurs Proxmox
pvecm add 192.168.60.1 # adresse IP du premier serveur PVE
Lorsque ce sera demandé, entrer le password root du premier serveur et accepter les certificats.
Depuis le deuxième serveur PVE :
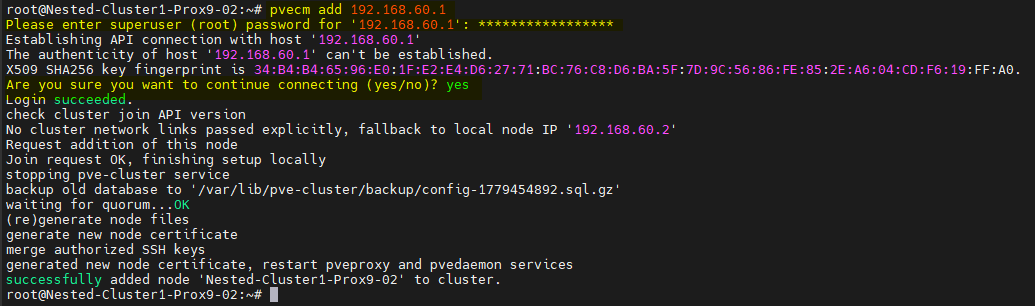
Depuis le troisième serveur PVE :
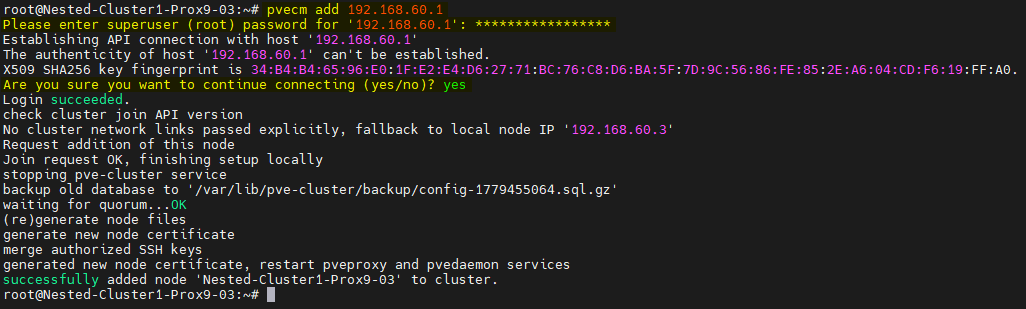
Après les avoir ajoutés au Cluster, les serveur seront visibles depuis leur interface graphique.
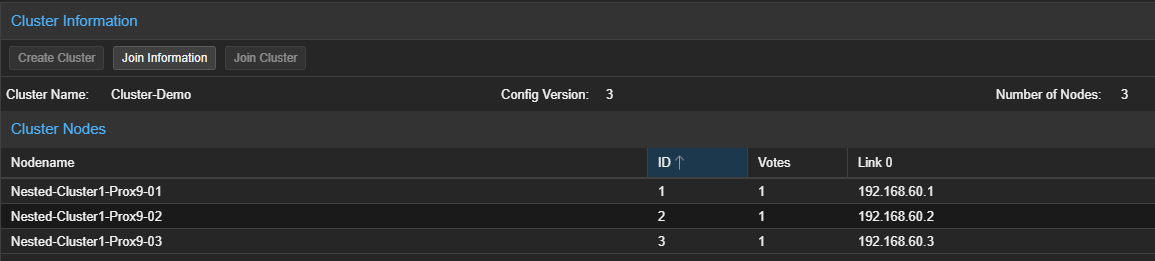
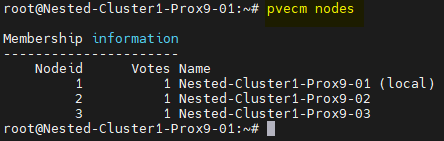
Il sera également possible de vérifier le Cluster avec les commandes suivantes :
pvecm nodes
pvecm status
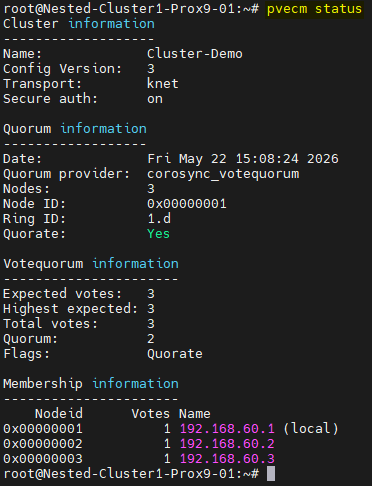
¶ Modification du lien Corosync
Nous venons créer un Cluster et d'ajouter le second nœud cependant le réseau utilisé ne correspond pas à celui que nous avons configuré et qui sera dédié à Corosync.
Pour utiliser le réseau dédié nous allons devoir faire quelques modifications.
- Editer le fichier
/etc/pve/corosync.conf
Dans la partie "nodelist", modifier l'adresse ip par celle du réseau dédié
AVANT
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.60.1
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.60.2
}
node {
name: Nested-Cluster1-Prox9-03
nodeid: 3
quorum_votes: 1
ring0_addr: 192.168.60.3
}
}
APRES
nodelist {
node {
name: Nested-Cluster1-Prox9-01
nodeid: 1
quorum_votes: 1
ring0_addr: 192.168.70.1 # <== ICI
}
node {
name: Nested-Cluster1-Prox9-02
nodeid: 2
quorum_votes: 1
ring0_addr: 192.168.70.2 # <== ICI
}
node {
name: Nested-Cluster1-Prox9-03
nodeid: 3
quorum_votes: 1
ring0_addr: 192.168.70.3 # <== ICI
}
}
ATTENTION : Pour que la modification soit prise en compte il faudra redémarrer le service corosync sur chacun des nœuds :
systemctl restart corosync
¶ Vérifications
Nous pouvons vérifier que la modification a bien été prise en compte en utilisant à nouveau la commande pvecm status
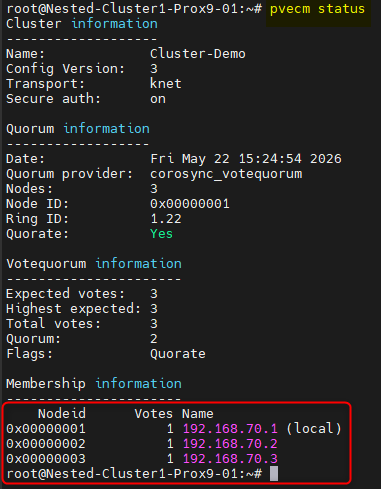
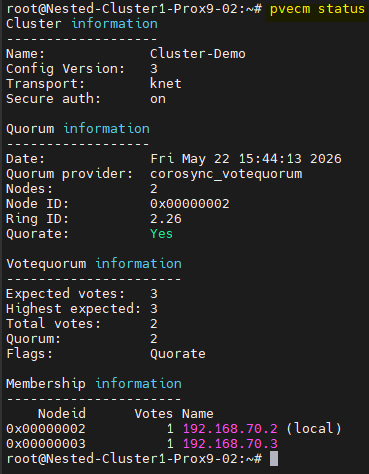
¶ Tests de fonctionnement du quorum
¶ Simulation de panne
Pour simuler une panne je vais éteindre le premier serveur Proxmox du Cluster.
shutdown now
Puis, depuis le second serveur Proxmox, je vais vérifier l'état du Cluster.
pvecm status
Rallumer le premier serveur Proxmox.
¶ Test de perte réseau
Pour tester le réseau et vérifier que tout fonctionne correctement en cas de panne nous allons simuler une coupure réseau vers un nœud.
Depuis le premier serveur Proxmox taper la commande suivante :
ip link set vmbr1 down
Si tout se passe correctement, le Cluster fonctionne toujours.
¶ Installation de Ceph
Cette étape permet d’installer Ceph sur les trois nœuds du cluster Proxmox VE afin de transformer l’infrastructure en plateforme HCI.
Dans une architecture HCI :
- Les hyperviseurs hébergent les VM ;
- Les mêmes nœuds hébergent également le stockage distribué Ceph.
Avant l’installation, il est important de comprendre les composants principaux.
| Composant | Rôle |
|---|---|
| MON | Maintient la carte du cluster et le quorum |
| MGR | Fournit les métriques et services d’administration |
| OSD | Stocke physiquement les données |
| Pool | Conteneur logique des données |
| RBD | Disque virtuel utilisé par Proxmox |
¶ Installation en mode graphique
¶ Installation
ATTENTION : Cette étape est à faire sur les trois serveurs du cluster AVANT de continuer
Depuis le premier serveur PVE :
- Cliquer sur Dataceter puis cliquer sur "Ceph". Dans la partie de droite cliquer sur "Install Ceph".
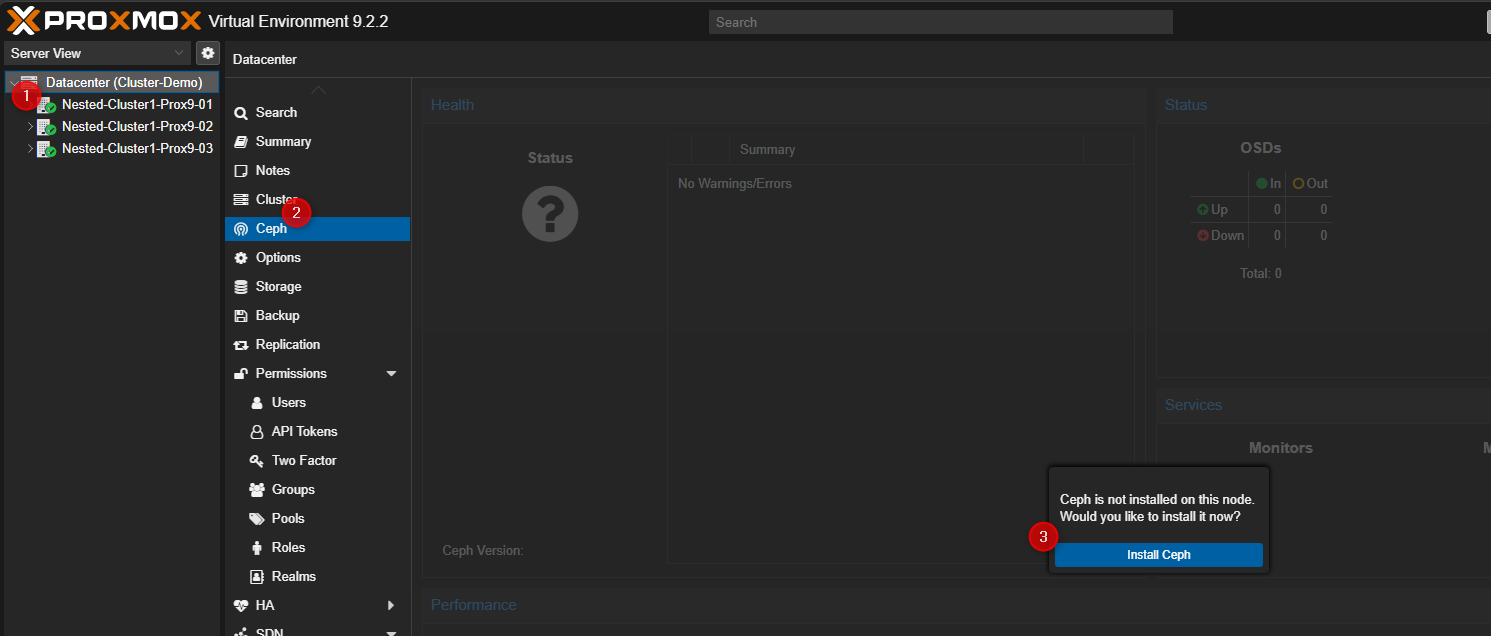
- Sélectionner la version à installer et la licence à utiliser.
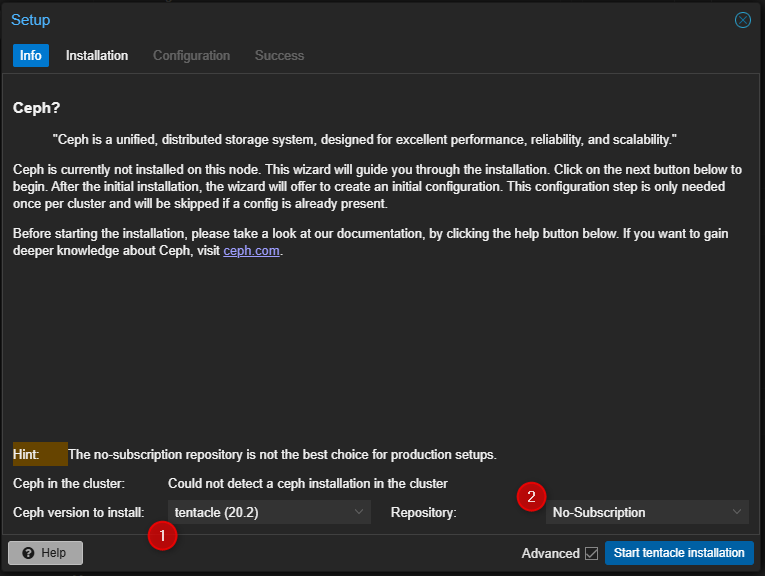
- Cliquer sur "Start Installation' pour passer à la première partie de la configuration d'un Cluster Ceph.
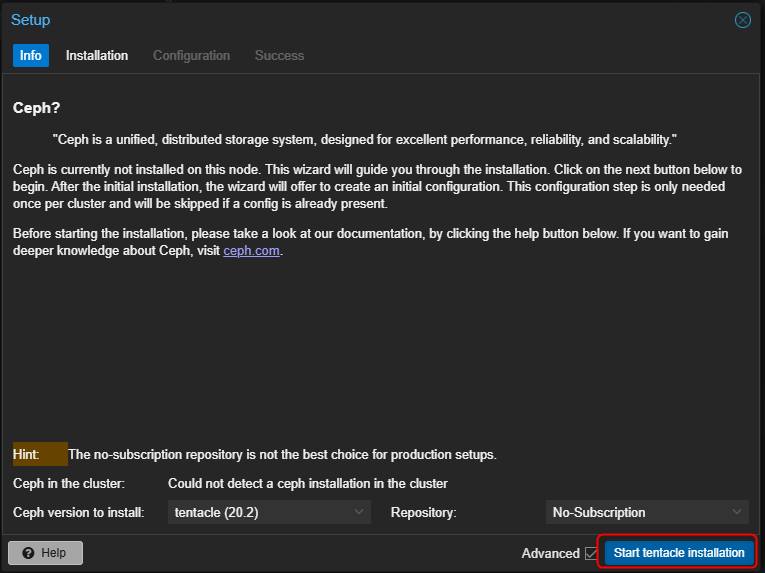
- Accepter l'installation des packages en validant par "y".
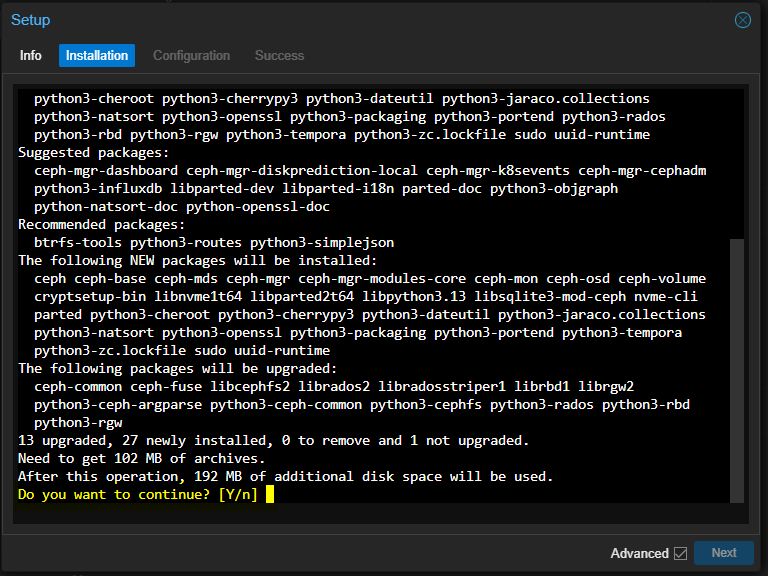
- Lorsque l'installation est terminée cliquer sur "Next"
- Séletionner le réseau qui sera utilisé par Ceph puis cliquer sur "Next"
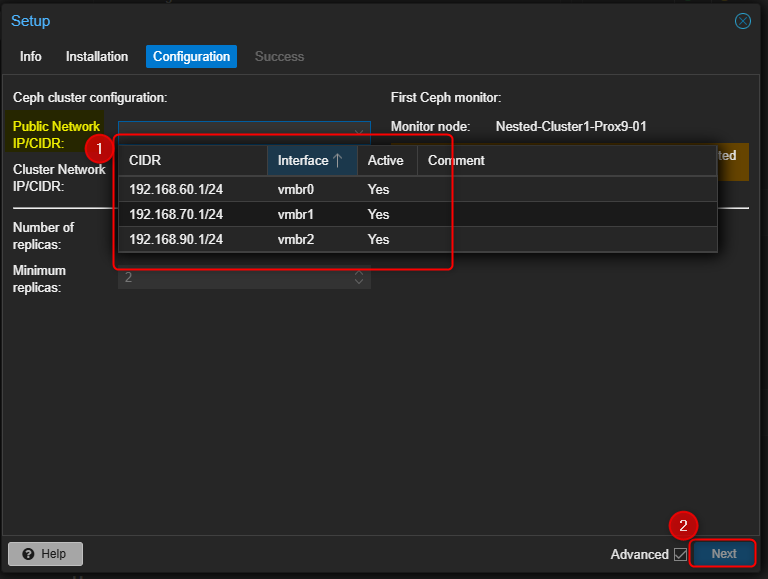
- Cliquer sur "Finish" pour terminer l'installation.
Depuis le deuxième et troisème serveur PVE :
- Cliquer sur Dataceter puis cliquer sur "Ceph". Dans la partie de droite cliquer sur "Install Ceph".
- Sélectionner la version à installer et la licence à utiliser.
- Accepter l'installation des packages en validant par "y".
- Lorsque l'installation des packages sera terminée, le cluster Ceph sera automatiquement détecté.
Il ne sera donc pas nécessaire de refaire la configuration. Cliquer sur "Next" pour continuer.
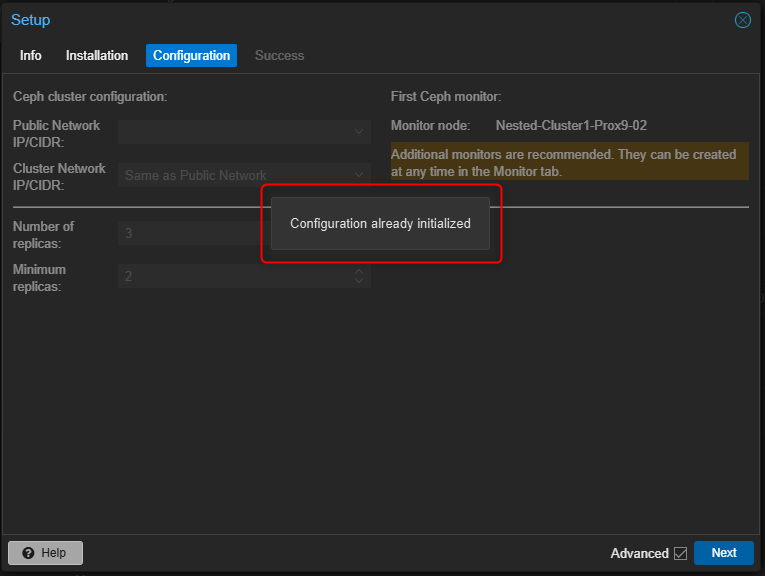
- Cliquer sur "Finish" pour terminer l'installation.
¶ Ajout des Monitors (MON)
Par défaut lors de l'installation de Ceph, le processus créé également un "MON" (Monitor).
Nous allons devoir cependant en créer d'autres pour que l'ensemble de nos serveurs possèdent ce rôle.
Pour rappel, les "MON" (Monitors) :
- Maintiennent la carte du cluster.
- Suivent l’état des OSD.
- Gèrent le quorum.
- Coordonnent le cluster.
- Assurent la copie des données et leur distribution.
| MON disponibles | État |
|---|---|
| 3/3 | OK |
| 2/3 | OK |
| 1/3 | Perte quorum |
Pour vérifier la présence du premier "MON", cliquer sur le premier serveur PVE puis sur "Monitor". Il sera visible dans la partie de droite, en haut.
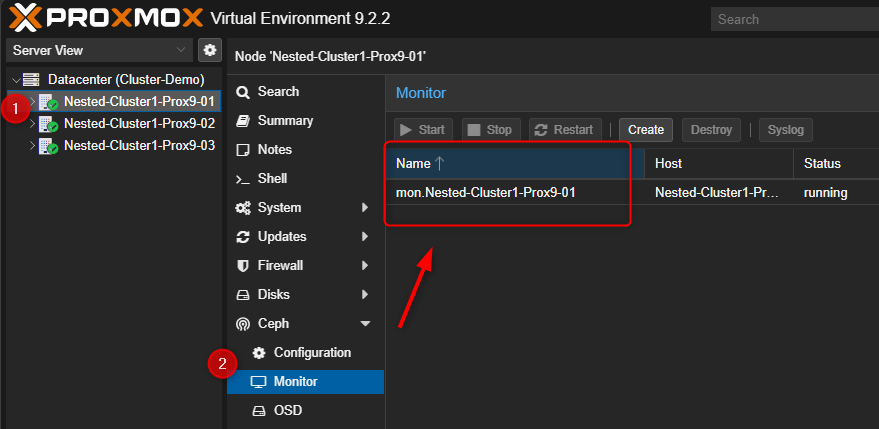
Pour créer d'autres "MON"
- Cliquer sur n'importe quel serveur PVE puis sur "Monitor". Dans la partie de droite en haut cliquer sur "Create"
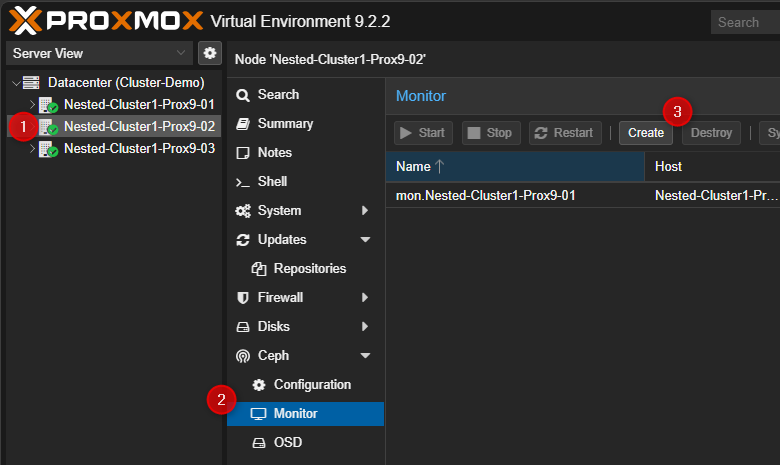
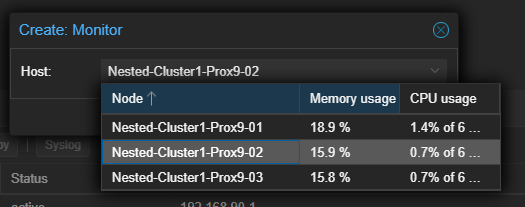
- Sélectionner un serveur dans la liste.
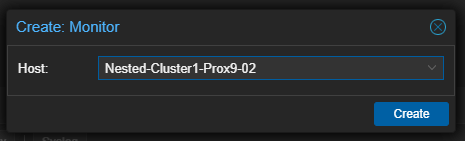
- Valider en cliquant sur "Create"
- Le second "MON" devient également visible dans la partie de droite en haut.
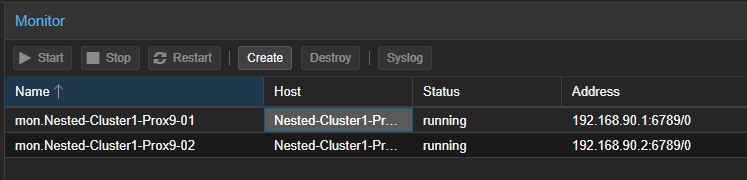
- Reproduire cette étape pour l'ajout du troisième "MON".
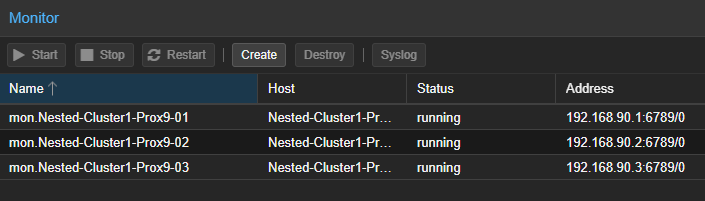
Il est possible de vérifier les "MON" à l'aide de la commande ceph mon stat.
¶ Ajout des Managers (MGR)
Comme pour les MON, lors de l'installation de Ceph le processus a installé un "Manager (MGR)".
Dans les versions récentes de Ceph, les "MGR" sont obligatoires et nous allons donc devoir l'installer sur nos serveurs.
Les "MGR" fournissent :
- statistiques
- dashboard
- API
- monitoring
- modules Ceph.
| Nombre | Usage |
|---|---|
| 1 | Minimum |
| 2 | Recommandé |
| 3 | Haute résilience |
Pour vérifier la présence du premier "MGR", cliquer sur le premier serveur PVE puis sur "Monitor". Il sera visible dans la partie de droite, en bas.
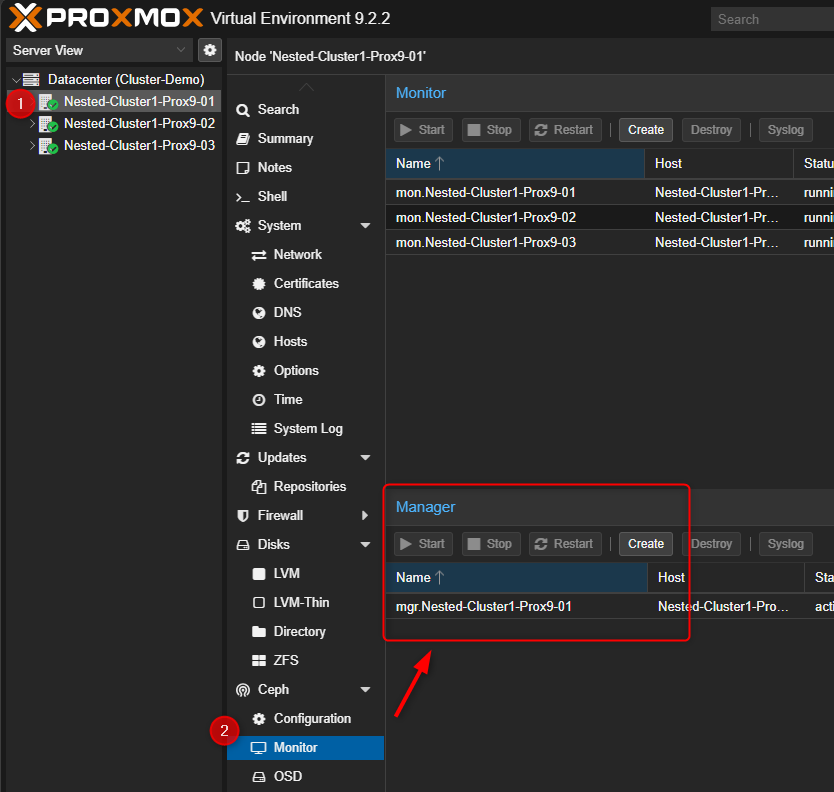
Pour créer d'autres "MGR"
- Cliquer sur n'importe quel serveur PVE puis sur "Monitor".
Dans la partie de droite en bas cliquer sur "Create"
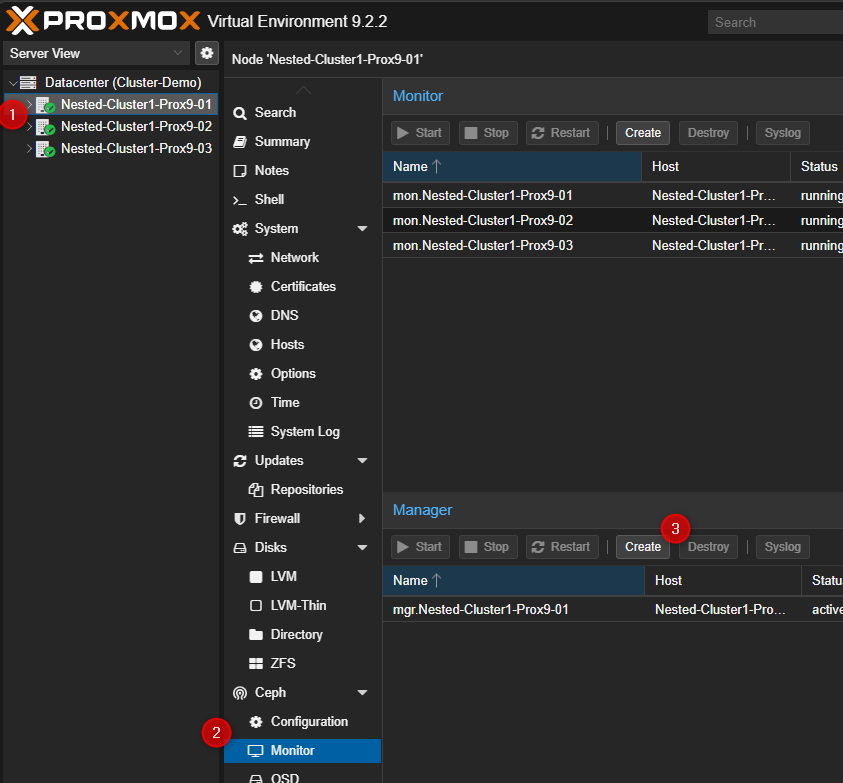
- Sélectionner un serveur dans la liste.
- Valider en cliquant sur "Create"
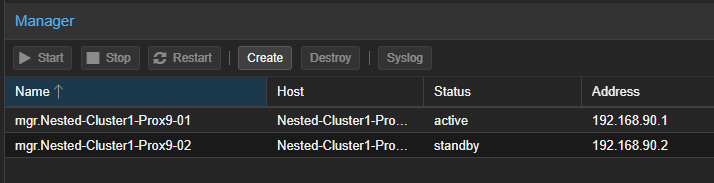
- Le second "MGR" devient également visible dans la partie de droite en haut.
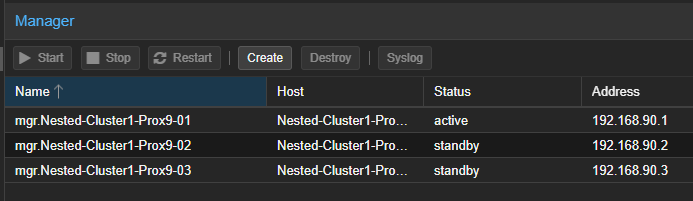
- Reproduire cette étape pour l'ajout du troisième "MGR".
Il est possible de vérifier les "MGR" à l'aide de la commande ceph mgr stat.
¶ Préparation des OSD
Les "OSD" (pour Object Storage Device) sont les composants les plus importants du Cluster Ceph puisqu'ils :
- stockent les données.
- répliquent les blocs.
- assurent la résilience.
Dans une configuration de Cluster Ceph, chacun des disques physiques de nos serveurs est un "OSD".
Lors de la création d'un "OSD", plusieurs paramètres sont possibles :
| Paramètres | Descriptions |
|---|---|
| Disk | Disque principal |
| DB Disk | Métadonnées BlueStore |
| WAL Disk | Journal |
| Encryption | Chiffrement LUKS |
Dans cette documentation, nous feront au plus simple.
Je ne vais pas chiffrer les données et laisser tout par défaut.
- Pour créer un "OSD", sélectionner un serveur PVE puis cliquer sur "OSD" puis en fin sur "Create OSD".
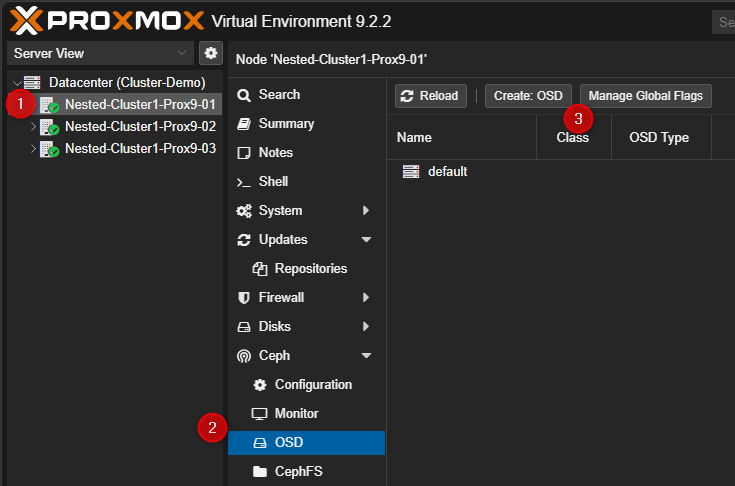
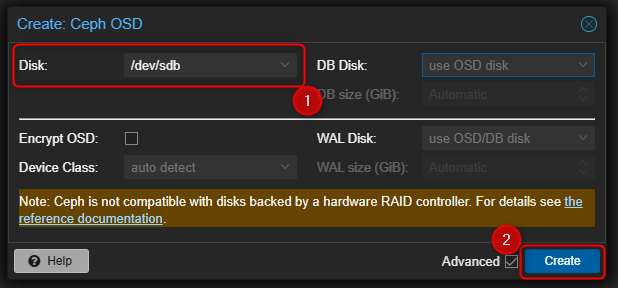
- Sélectionner un disque puis cliquer sur "Create".
Pour information seuls les disques non utilisés seront visibles dans la liste.
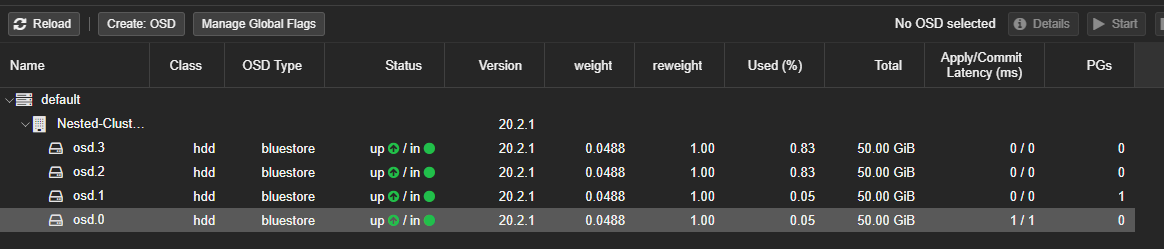
- L'OSD sera visible dans la liste

- Reproduire la création pour chacun des disques du serveur. Dans mon cas j'avais 4 disques, j'aurai donc 4 "OSD".
- Faire à nouveau cette étape mais cette fois-ci sur chacun des autres serveurs du Cluster.
Dans mon Cluster PVE j'ai 3 serveurs ayant chacun 4 disques. Je devrai donc voir 3 listes de 4 disques.
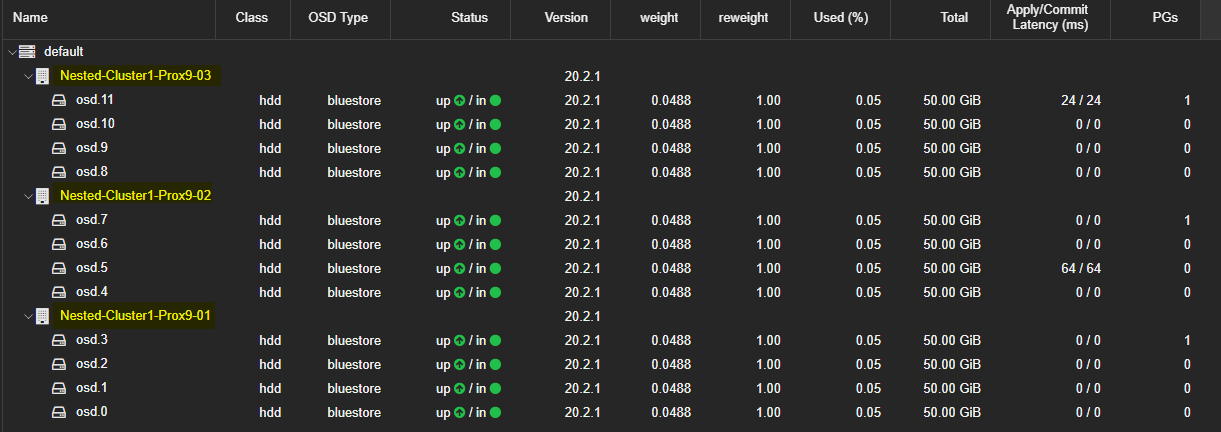
Il est possible de vérifier les "OSD" à l'aide de la commande ceph osd tree.
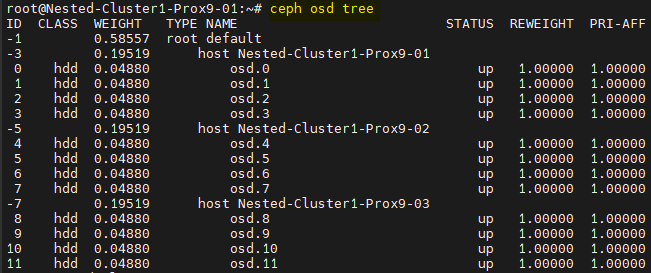
Ainsi que leur état avec la commande ceph osd stat.

| État | Signification |
|---|---|
| up | daemon actif |
| down | daemon arrêté |
| in | participe au cluster |
| out | exclu du cluster |
ATTENTION : Il est tout à fait possible d'ajouter des "OSD" supplémentaires cependant il sera obligatoire d'en ajouter le même nombre sur chacun des serveurs. Si vous ajoutez un "OSD" sur un serveur il faudra donc en faire autant sur les autres serveurs du Cluster.
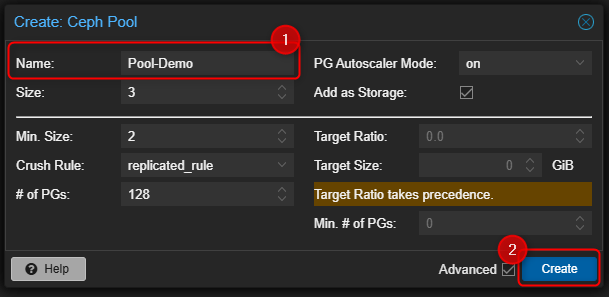
¶ Création du Pool
Après avoir préparé les OSD, nous allons devoir créer un ou plusieurs "Pool" selon les besoins.
Un "Pool" est un espace de stockage logique créé dans Ceph et sert à organiser et répartir les données (disques de machines virtuelles, sauvegardes, objets, etc.).
- Sélectionner un serveur PVE puis en dessous de Ceph cliquer sur "Pools"
- Dans la partie de droite cliquer sur "Create"
- Activer les options avancées en cochant la case "Advanced".
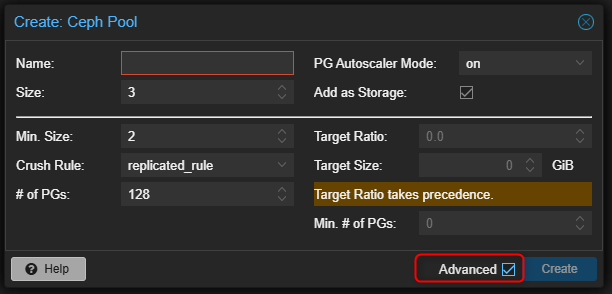
| Options | Descriptions |
|---|---|
| Name | Nom du pool. Il permet d’identifier l’espace de stockage dans le cluster. |
| Size | Définit le nombre de copies (réplicas) des données dans le cluster Ceph. Une valeur de 3 signifie que chaque donnée est stockée sur trois nœuds différents afin d’assurer la redondance. |
| Min. Size | Nombre minimal de répliques devant être disponibles pour autoriser l’accès aux données. Si ce seuil n’est plus respecté, le pool devient inaccessible afin de protéger l’intégrité des données. |
| Crush Rule | Règle utilisée par l’algorithme CRUSH pour déterminer sur quels nœuds ou disques les données seront réparties. La règle replicated_rule est la configuration standard pour un stockage répliqué. |
| # of PGs | Nombre de Placement Groups utilisés pour répartir les données dans le cluster. Les PG influencent directement l’équilibrage et les performances du stockage. |
| PG Autoscaler Mode | Permet à Ceph d’ajuster automatiquement le nombre de PG en fonction de la taille et de l’utilisation du pool. Le mode on est généralement recommandé. |
| Add as Storage | Ajoute automatiquement le pool comme espace de stockage utilisable dans Proxmox VE après sa création. |
| Target Ratio | Définit la proportion estimée d’utilisation du cluster pour ce pool. Cette valeur aide l’autoscaler à calculer le nombre optimal de PG. |
| Target Size | Taille estimée que le pool devrait atteindre. Cette information est utilisée par l’autoscaler pour optimiser le nombre de PG. |
| Min. # of PGs | Nombre minimal de PG que le pool doit conserver, même si l’autoscaler souhaite réduire cette valeur. |
- Par défaut, pour créer un "Pool", il suffit d'entrer un nom puis de cliquer sur "Create"
¶ Installation en CLI
¶ Installation des paquets Ceph
- Installer les paquets de Ceph sur chacun des serveurs :
pveceph install
- Valider en tapant "y" lorsque c'est demandé.

Cette commande installe tous les paquets Ceph, configure les dépendances, prépare systemd et télécharge la version recommandée.
Elle installera notamment :
- ceph-mon.
- ceph-osd.
- ceph-mgr.
- ceph-common.
- librados.
- librbd.
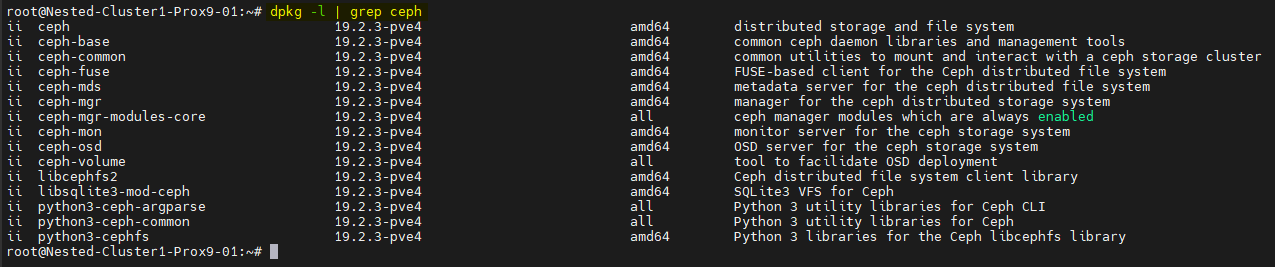
Nous pouvons vérifier les paquets avec la commande dpkg -l | grep ceph
et la version avec la commande ceph -v

¶ Initialisation du cluster Ceph
- Initialiser le cluster Ceph en tapant cette commande sur chacun des serveurs :
pveceph init --network IP_CEPH/MASK



¶ Création des MON
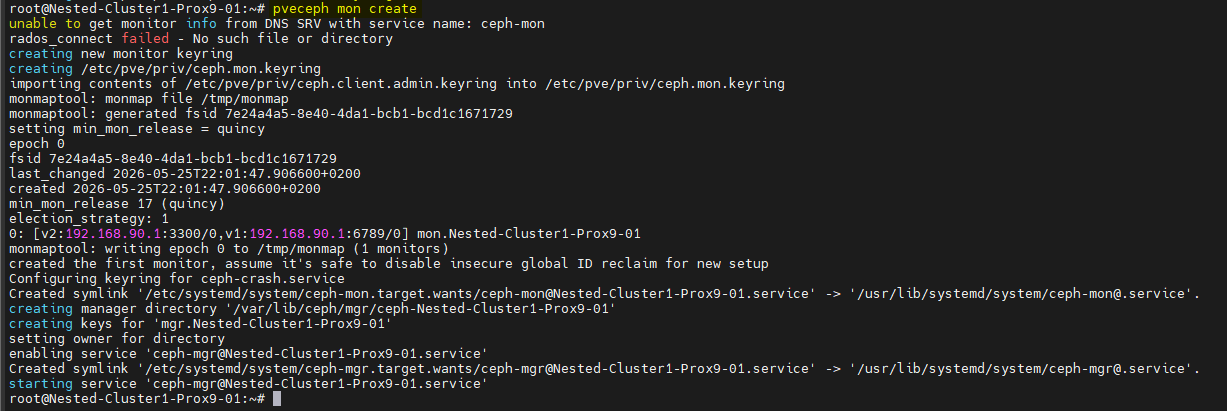
- Créer les MON en tapant cette commande sur chacun des serveurs :
pveceph mon create


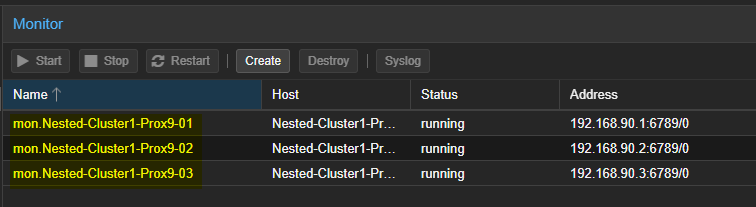
- Les trois serveurs seront visibles dans la liste des "Monitors"
¶ Création des MGR
- Créer les MGR en tapant cette commande uniquement sur les deux derniers serveurs :
pveceph mgr create


ATTENTION : Par défaut le premier serveur sera déjà Manager.
Il ne sera donc pas nécessaire de faire cette commande.
- Les trois serveurs seront visibles dans la liste des "Managers"
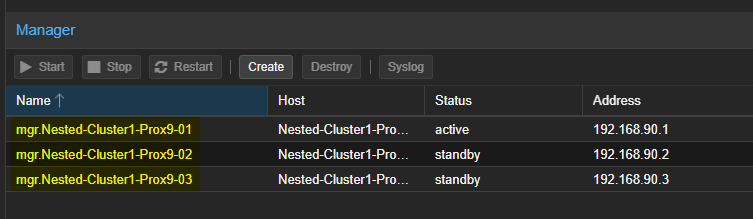
¶ Création des OSD
- Lister les disques à utiliser pour connaitre leur identifiant.
Je ne mets pas les screen mais le résultat sera identique sur mes deux autres serveurs PVE.
lsblk
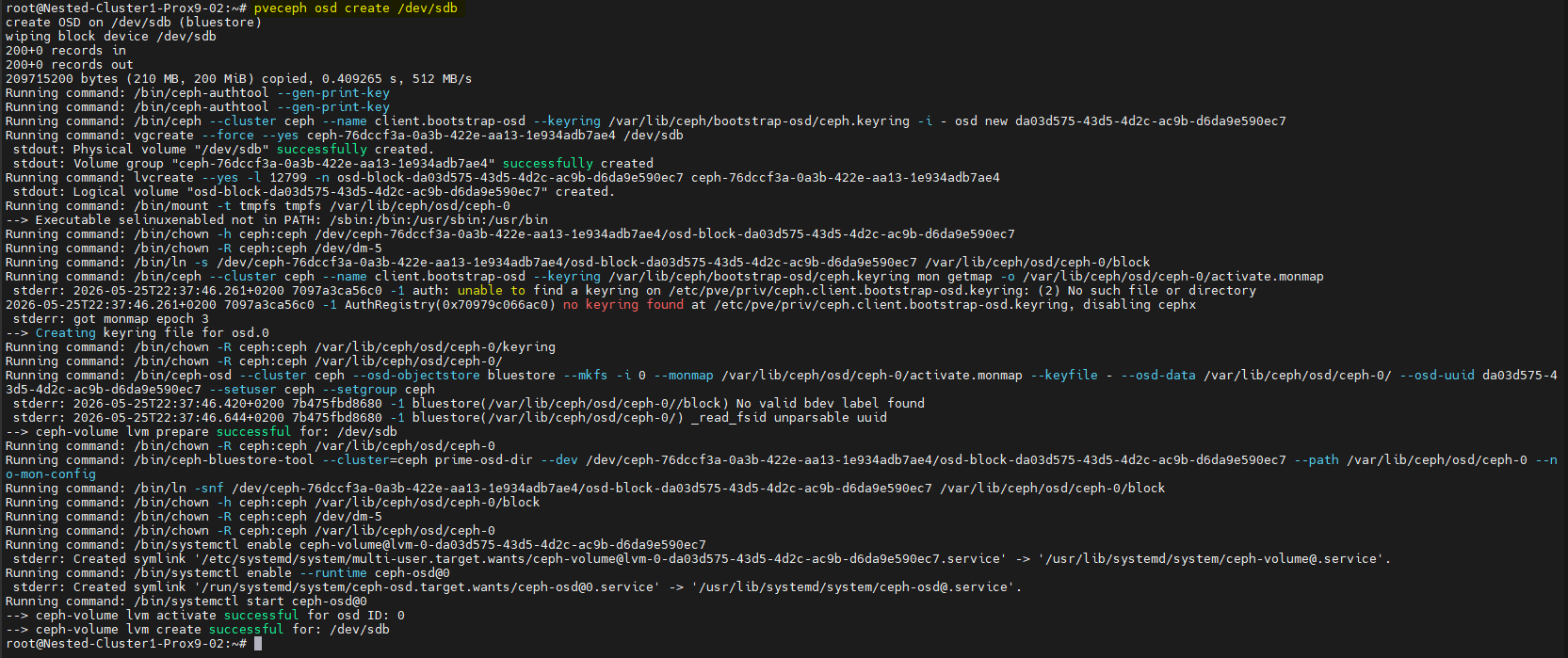
- Créer les OSD en tapant cette commande sur chacun des serveurs :
pveceph osd create /dev/sdb
pveceph osd create /dev/sdc
pveceph osd create /dev/sdd
pveceph osd create /dev/sde
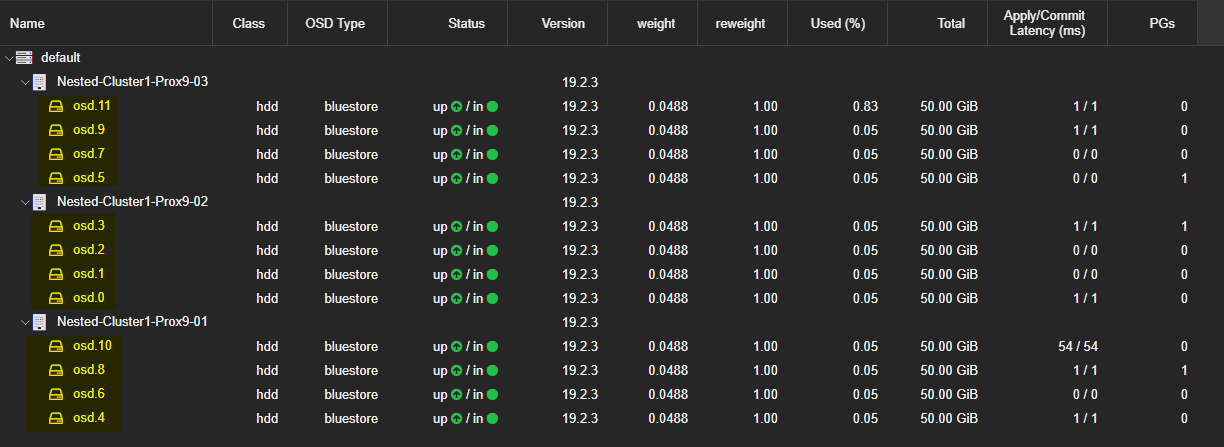
- L'ensemble des OSD sera visible dans l'interface graphique.
¶ Création d’un pool
- Créer le Pool en tapant cette commande sur le premier serveur :
ceph osd pool create Pool-Demo 128

- Vérifier la présence du Pool en tapant cette commande sur le premier serveur :
ceph osd pool ls

¶ Configuration de la réplication
- Configurer la réplication du Pool en tapant cette commande sur le premier serveur :
ceph osd pool set Pool-Demo size 3

¶ Initialisation du Pool
- Initialiser le Pool en tapant cette commande sur le premier serveur :
rbd pool init Pool-Demo

¶ Initialisation RBD
- Initialiser le RBD en tapant cette commande sur le premier serveur :
rbd pool init Pool-Demo

¶ Intégration dans Proxmox
- Ajouter le Pool comme stockage dans chacun des serveurs en tapant cette commande sur le premier serveur :
pvesm add rbd Pool-Demo \
--pool Pool-Demo \
--monhost "192.168.90.1 192.168.90.2 192.168.90.3" \
--content images,rootdir

- Le Pool sera visible comme stockage depuis l'interface graphique.
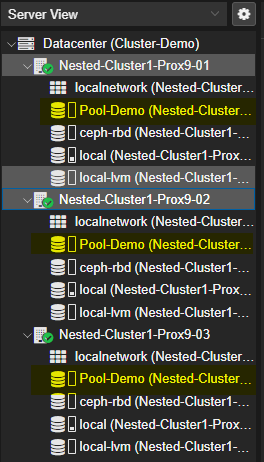
¶ Vérification du Cluster Ceph
Nous pouvons vérifier l'état de santée du Cluster Ceph avec la commande ceph -s
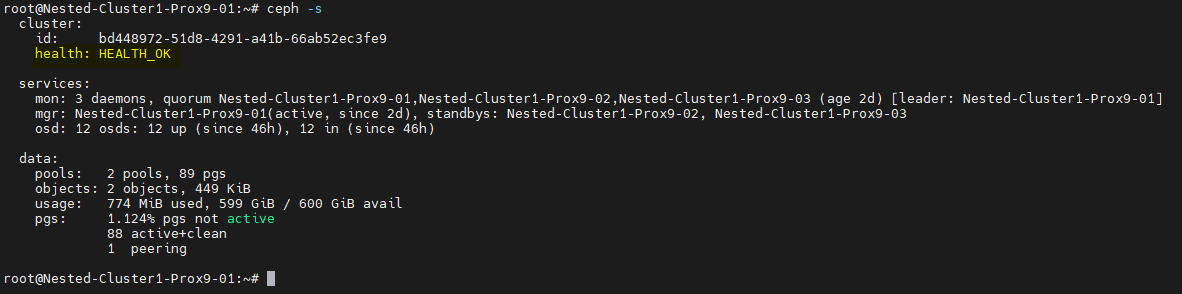
Nous pouvons également vérifier l'ensemble des composants du Cluster Ceph à l'aide des commandes suivantes.
| Vérification | Commande |
|---|---|
| MON | ceph mon stat |
| MGR | ceph mgr stat |
| OSD | ceph osd tree |
| Pools | ceph osd pool ls |
| Usage | ceph df |
¶ Création d'une VM
La configuration de notre Cluster Ceph est terminée et nous pouvons à présent l'utiliser pour stocker nos VMs et CT.
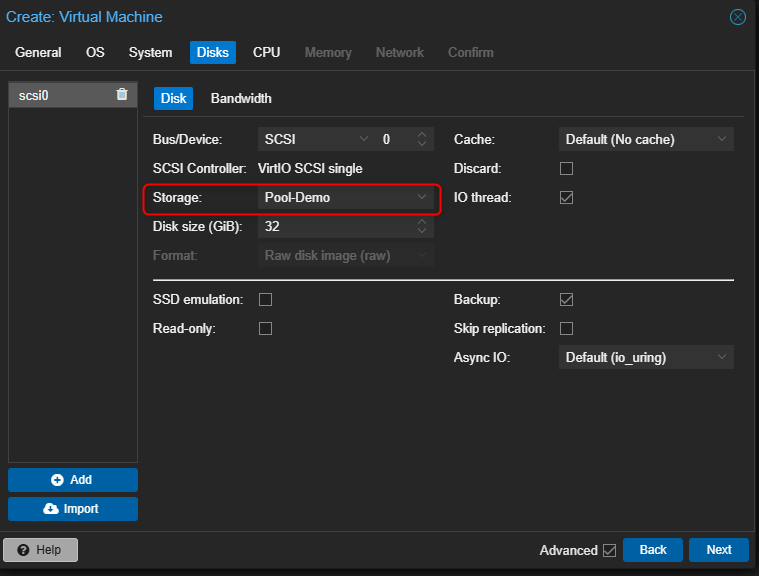
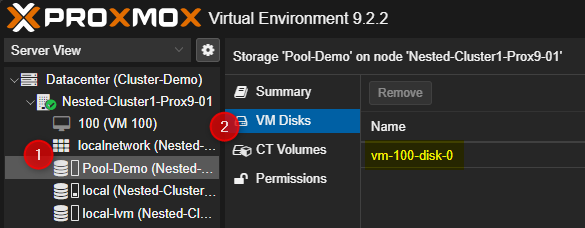
Lors de la création d’une VM ou d'un CT il suffira simplement de définir le Pool comme stockage.
Dans mon cas ce sera "Pool-Demo"
¶ Activation et configuration du HA
¶ Services HA
- Sur chaque nœud, activer les services suivants :
systemctl enable pve-ha-lrm
systemctl enable pve-ha-crm
systemctl start pve-ha-lrm
systemctl start pve-ha-crm
¶ Vérification
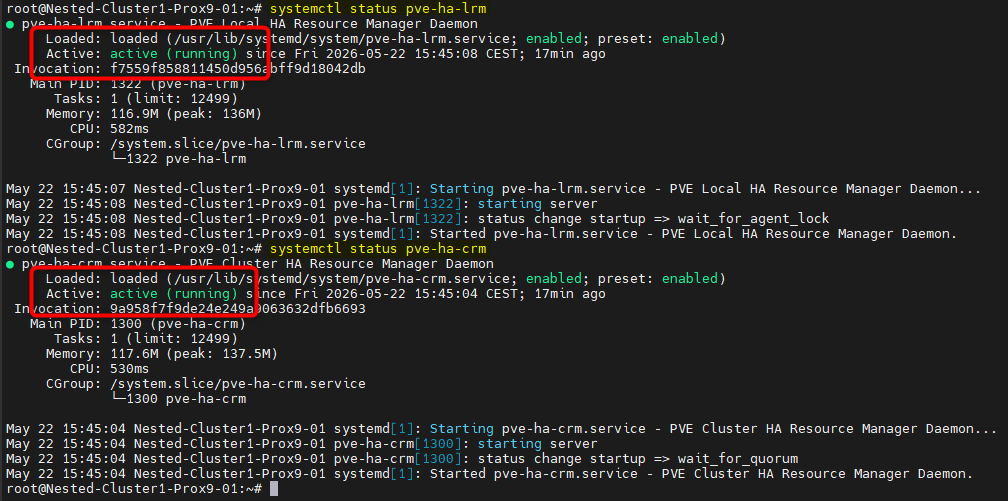
- Sur chaque nœud, vérifier le status des services :
systemctl status pve-ha-lrm
systemctl status pve-ha-crm
Les services doivent être actifs sur chacun des PVE
¶ Fichiers de configuration HA
Tous les fichiers du HA sont dans le répertoire /etc/pve/ha/
- Fichier resources.cfg :
/etc/pve/ha/resources.cfg
Ce fichier définit :- Les VM gérées en HA
- Leur comportement
- Fichier manager_status :
/etc/pve/ha/manager_status
Ce fichier contient l’état interne du cluster HA (Il ne pas modifier manuellement)
¶ Configuration du HA sur une VM
- Ajout du HA sur une VM
ha-manager add vm:100

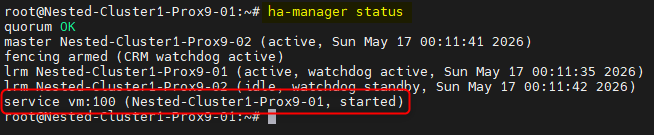
- Vérification du HA sur une VM
ha-manager status
- Modification des paramètres
ha-manager set vm:100 --max_restart 5 --max_relocate 2

¶ Fonctionnement interne du HA
-
CRM (Cluster Resource Manager)
- Lit /etc/pve/ha/resources.cfg
- Décide où démarrer les VM
-
LRM (Local Resource Manager)
- Exécute les actions localement
- Démarre/arrête les VM
Ces composants communiquent via Corosync.