![]()
¶ II – Les bases
¶ A – Premiers pas
¶ 1 – Exécuter un script
Pour exécuter un script il y a deux manière possible :
- En exécutant un fichier qui contiendra le contenu du script.
- En utilisant la commande Bash dans un terminal.
¶ 1.1 – Via un fichier script
Le fichier du script devra être écrit d’une manière bien précise.
En effet, il faudra obligatoirement que le script commence par ce qu’on appelle un « Shebang » suivi du chemin absolu de l’interpréteur de commandes qui sera utiliser au lancement du script.
Le shebang, représenté par « #! », est un en-tête d’un fichier texte qui indique au système d’exploitation que ce fichier n’est pas un fichier binaire mais un script et donc un ensemble de commandes. On indiquera également sur la même ligne l’interpréteur permettant d’exécuter ce script.
Dans notre cas, pour indiquer au système qu’il s’agit d’un script qui sera interprété par bash on placera le shebang sur la première ligne suivi de « /bin/bash » :
#!/bin/bash
Cet ensemble d’information représentera donc la première ligne du script.
Attention : il est possible de préciser d’autres interpréteur de commandes que bash comme par exemple Perl, Python, Korn Shell, sh, etc.
Pour pouvoir lancer le script, il sera également nécessaire d’avoir les droits d’exécutions sur le fichier contenant le script et ses différentes commandes :
chmod +x «fichier_du_script»

¶ 1.2 – Via la commande bash
Il est possible de lancer un script directement depuis la commande bash.
Ce type de lancement ne nécessite pas les droits d’exécution sur le fichier du script ni de « Shebang ».
En effet, ici ce n’est pas le fichier qui est exécuté mais la commande bash qui prendra en paramètre le fichier du script.
La commande bash va donc lire le fichier ligne par ligne et faire une exécution séquentielle des différentes lignes composant le fichier du script.
$bash /chemin/vers/le-fichier-du-script.sh

Ce mode de lancement peut être particulièrement pratique lorsqu’on ne souhaite pas mettre les droits d’exécution sur un fichier pour des raisons de sécurité ou simplement si l’on souhaite effectuer des tests.
Cela permet également une plus grande compatibilité avec différents systèmes d’exploitation car certains ne reconnaissent pas le « Shebang » ou différents types d’interpréteurs (ex : Windows)
¶ 2 – Démonstration
Commençons dans un premier temps par créer un répertoire.
Ce dernier sera utilisé pour stocker les différents scripts qui seront créés au cours de cette documentation.
Dans notre cas nous allons créer un répertoire appelé « scripts ».
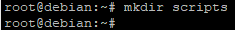
Puis nous allons nous placer dans ce répertoire

Une fois dans le répertoire « scripts » il faudra créer le fichier du script contenant les différentes commandes.
Ici nous allons l’appeler « ‘premiers-pas »
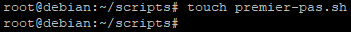
Attention : ici l’extension du fichier n’est mise qu’à titre indicatif
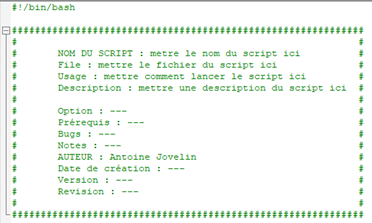
A l’aide de votre éditeur de texte préféré, ouvrez le fichier pour l’éditer et commencer à écrire le script.
Nous allons simplement y mettre une commande « echo » qui permet d’afficher les informations contenue dans une ligne, enregistrer puis quitter.
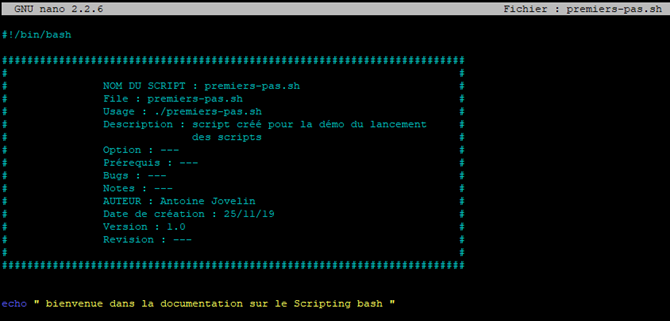
Attention : à titre informatif, j’ai personnellement l’habitude d’ajouter un en-tête qui permet d’avoir des informations sur le script lorsqu’on l’ouvre via un éditeur de texte. Ce n’est pas une obligation. Je précise également mais vous le savez déjà, le caractère « # » permet de mettre en commentaire une ligne 😉
¶ 2.1 – lancement via l’exécution du fichier
L’exécution d’un script est toujours précédé de « ./ ». Pour l’exécuter, il faudra soit :
- indiquer le chemin complet du fichier
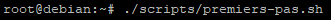
- se positionner dans le répertoire contenant le fichier
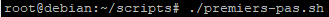
Comme nous l’avons indiqué précédemment, pour exécuter directement un script il faut obligatoirement que ce dernier ai les droits d’exécution et qu’il commence par un « Shebang » suivi de l’interpréteur à utiliser.
Dans notre exemple ce n’est pas le cas, il n’y a pas les droits d’exécution sur le fichier.
Que se passe-t-il si on tente de le lancer quand même ?
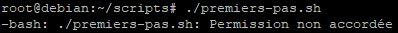
En toute logique, ça ne marche pas. Ajoutons les droits d’exécution et recommençons

¶ 2.2 – lancement via la commande bash
Comme précisé précédemment, la commande bash n’a pas besoin de « Shebang » ni même d’un interpréteur de commande pour lancer un script. Nous allons donc effectuer le test via la commande suivante :
$bash /chemin/vers/le-fichier-du-script.sh

Le script s’est lancé sans problème car la commande bash a pu passer en paramètre le contenu du fichier « premiers-pas.sh »
¶ B – Les Variables
¶ 1 - Introduction
Les « variables » sont utilisées pour stocker temporairement des informations en mémoires, elles sont la base de la programmation.
En bash, il n’y a aucun « typage » des variables, elles sont toutes considérées comme des chaînes de caractères mais peuvent aussi être évaluées comme des entiers selon le contexte.
Elles permettent par exemple une grande flexibilité pour la gestion et l’exécution des commandes.
Toutefois si l’on manque de vigilance lors de l’écriture du script, les variables peuvent nous amener à effectuer plus facilement certaines erreurs.
Il faudra faire attention particulièrement au contenu des variables et toujours garder une trace de leur usage.
¶ 2 - Déclarer une variable
Contrairement à de nombreux autres langages de programmation, Bash ne classe pas ses variables par « type ».
Pour l'essentiel, les variables Bash sont des chaînes de caractères mais suivant le contexte Bash autorise les opérations arithmétiques et les comparaisons sur ces variables, le facteur décisif étant la présence de chiffres uniquement dans la variable.
Il est très important de comprendre que sans typage une variable n’aura pas besoin d’être « déclarée » (c’est-à-dire précisée en tête du script), cependant elle sera déclarée automatiquement dès l’instant où on lui affectera une valeur.
Il est tout à fait possible de faire appel à une variable qui n’a pas encore été affectée mais celle-ci aura une valeur nulle.
Attention : une variable nulle et une variable avec une chaine de caractère vide ne sont pas du tout la même chose. En effet, une variable nulle sera une variable non initialisée ou détruite tandis qu’une variable avec une chaine de caractère vide est une variable qui s’est vu affecter une chaine de caractère vide.
Pour effectuer cette affectation, il suffit simplement d’écrire le nom de la variable suivi du symbole « = » puis de sa valeur.
Attention il n’y a pas d’espace, tout doit être attaché.
Prenons un exemple. Nous allons créer un nouveau script que l’on appellera « variables.sh »
Puis nous allons l’éditer avec notre éditeur de texte favoris.
Dans un premier temps, on y écris sur la premier ligne le Shebang ainsi que le shell utilisé
#!/bin/bash
Puis on écris la variable que l’on souhaite créer.
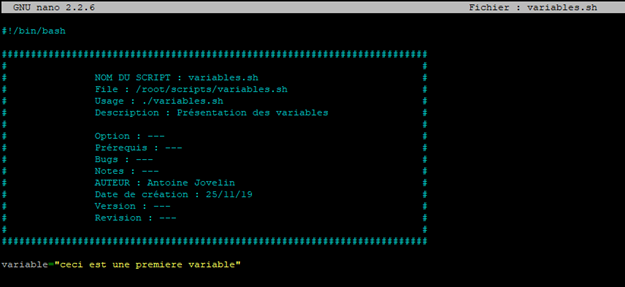
Dans cet exemple, le contenu de la variable est une phrase. A cause des espaces, il faudra obligatoirement qu’il commence et se termine soit par une simple quotte ou double quotte pour être sûr que l’intégralité de son contenu soit pris en compte.
Nous reviendrons par la suite sur l’utilisation des simples quottes ou doubles quottes
Attention : le nom de la variable est sensible à la case. Un nom avec des majuscule n’est pas la même chose que le même nom sans majuscule. Dans ce cas nous aurions deux variables différentes.
¶ 3 - Substitution de variable
La substitution de variable consiste à transformer le nom de la variable en sa valeur.
Si on reprends l’exemple précédent, cela signifie que le nom « variable » sera transformé en « ceci est une premiere variable », qui est la valeur que l’on a déclaré.
Pour effectuer cette substitution, nous allons ajouter le symbole « $ » devant le nom de la variable.
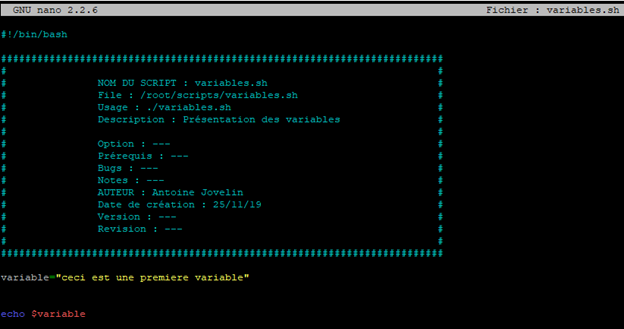
Attention : le « » est un caractère spécifique qui permet de dire « ce qui suit est une variable et il faut la transformer en sa valeur ».
On enregistre le fichier puis on va tester de le lancer pour voir si cela fonctionne.

La variable que nous avons déclarée a correctement été interprétée par son contenu.
¶ 4 - Suppression de variable
Dans l’exemple précédent, nous avons directement créer un fichier avec les lignes de commandes permettant d’affecter une variable puis d’en afficher son contenu lorsque le fichier est exécuté. Il faut cependant savoir que tout ce qui peut être fait dans un fichier script peut également être fait directement dans le terminal.
Nous aurions pu alors affecter la variable puis afficher son contenu depuis le terminal comme ceci

Il en va de même pour la suppression des variables.
Comme cette documentation est faite sur le scripting, nous allons continuer d’utiliser un fichier des script mais vous pouvez faire le test directement depuis le terminal et depuis un fichier.
Pour supprimer une variable et rendre son contenu à nulle il faudra utiliser la commande suivante
unset "nom_de_la_variable"
Gardons les informations de notre script et ajoutons cela à la suite.
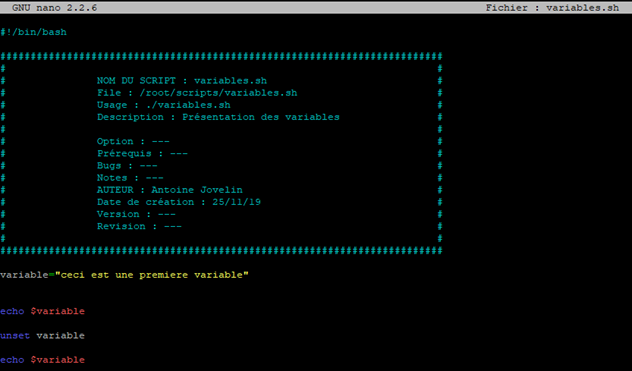
Que se passe-t-il lors de l’exécution du script ?
Dans un premier temps, la variable possède une valeur et va donc être affichée par la commande « echo » cependant avant le deuxième « echo » nous allons supprimer la variable et rendre son contenu nul.
Ceci aura pour effet d’afficher une ligne vide par le deuxième « echo ».
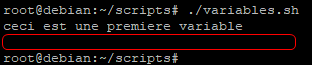
La valeur de la variable est alors nulle, comme si elle n’avait jamais été affectée.
¶ 5 -Portée d’une variable
¶ 5.1 - Variables locales
Par défaut la portée d’une variable est locale. Elle n’est définie et disponible qu’à l’intérieur du bloc de code ou de la fonction.
C’est à dire que sans définition particulière toutes les variables utilisées sont globales à tout le script et utilisables uniquement au sein du script.
Les variables locales ne sont utiles que dans des scripts locaux et dans des boucles par exemple.
Cependant, cette variable locale peut devenir une variable d’environnement via la commande « export ».
Cette dernière indique justement qu’il faut exporter et donc rendre disponible la variable aux processus enfants uniquement.
¶ 5.2 - Variables d’environnements.
Par opposition aux variables locales, il y a les variables d’environnement. Ces dernières sont accessibles en dehors du processus courant. Cependant ce n’est pas parce que l’on exporte une variable qu’elle est disponible partout.
En effet, nous l’avons mentionné, l’export n’est valable que pour l’environnement des processus enfants au processus courant.
Ainsi, une variable déclarée et exportée dans un shell est disponible dans ce shell ainsi que dans les processus lancés depuis ce dernier. Ces processus sont en effet des processus enfants et l’environnement courant leur est transmis lors de leur création.
Toutefois, si nous ouvrions deux terminaux distincts et que nous exportions une variable depuis le shell du terminal 1, celle-ci ne sera pas accessible sur le shell du terminal 2.
En effet, il y a de nouveau la notion de portée pour les variables d’environnement.
Nous en distinguons trois types de variables d’environnements :
- Variables d’environnement locales
Elles sont déclarées dans l’environnement courant et ne sont valables que pour les commandes et programmes démarrés par cet environnement et ce, jusqu’à la fin de la session courante.
Il ne faut pas croire que leur utilité est limité car ce n’est pas tout à fait le cas.
Environnement courant n’est pas obligatoirement synonyme d’interactif. De ce fait, on peut déclarer un environnement pour une « cron task » ou dans un script qui à son tour lancera un programme.
- Variables d’environnement de l’utilisateur
Pour pouvoir avoir des variables qui persistent après un reboot et qui soient accessibles depuis différentes sessions, il faut les déclarer au niveau des users.
Cependant, comme leur nom l’implique, elles ne sont disponibles que pour un utilisateur donné.
De ce fait, si l’on déclare une variable au niveau d’un utilisateur « toto » et que c’est « tata » qui lance un processus alors le processus en question ne sera pas en mesure d’accéder à cette variable.
Pour rendre cette création permanente, il faut écrire l’export de la variable le fichier « /home/$USER/.bashrc » de l'utilisateur, dans le cas où la variable ne soit que pour l'utilisateur, ou alors dans le fichier « /etc/bash.bashrc » afin de la rendre disponible pour tous les utilisateurs.
- Variables d’environnement globales
Ces variables sont disponibles pour tous les utilisateurs.
Cela peut parfois sembler plus simple à gérer, cependant, il existe un risque d’exposer des données sensibles à d’autres utilisateurs du système.
La solution la plus adaptée pour déclarer une variable globale est d’utiliser le fichier qui leur est dédié « /etc/environment ».
Comme il s’agit d’un fichier de variables d’environnement et non d’un script, il suffira simplement de déclarer la variable et sa valeur comme ceci : variable=«valeur». Toute autre chose risquerait de poser des problèmes.
Un script ne peut donc pas exporter une variable vers l’environnement du shell dont il est issu.
Il n’y aura aucune modification de l’environnement de l’utilisateur qui a lancé le script.
¶ 5.3 – Export de Variables
Pour exporter une variable il faudra déclarer la variable puis utiliser la commande « export » comme ceci :
VARIABLE="bonjour à tous!"
export VARIABLE
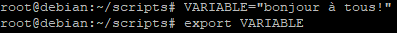
Attention : par convention, les variable d’environnement sont écrites en majuscule tandis que les variables locales en minuscules
Dans cet exemple, nous venons de créer une variable d’environnement local.
Nous pouvons également afficher son contenu

Une fois une variable passée en variable d’environnement, il est possible de la repasser en local. Pour cela nous utiliserons la commande suivante :
export -n "nom_de_la_variable"
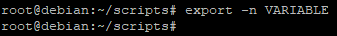
¶ 6 - Paramètres positionnels
Les scripts shell sont capables de récupérer des arguments qui auraient été placés juste après l'appel du script.
Les paramètres positionnels sont donc tous les arguments passés en « paramètres » sur la ligne de commandes lors de l’exécution d’un script.
Ils sont alors affectés aux variables locales réservées 1, 2, 3, 4, etc. et peuvent être appelés à l'aide des expressions « $1 », « $2 », « $3 », « $4 », etc.
Les variables locales « $1 », « $2 », « $3 », etc. contiennent respectivement la valeur l'argument 1, 2, 3, etc.
La variable « $0 » enregistre quant à elle la commande ayant permis de lancer le script.
La variable « $* » représente l'ensembles des paramètres sous la forme d'un seul argument
La variable « $@ » représente l'ensemble des arguments, c’est-à-dire « $1 », « $2 », « $3 », etc. avec chacune des valeurs qui leur sont associées.
La variable « # » représente le nombre de paramètres passés au script. Par exemple si 5 arguments sont passés au lancement du script alors « # » aura pour valeur 5.
Pour que ce soit plus parlant, nous allons faire un exemple et à nouveau créer un script que nous appellerons « parametres ».
Nous reprendrons la même trame que lors de la création du script sur les variables. Cependant nous allons ajouter quelques lignes « echo » pour une meilleure visibilité du résultat du script.
Le contenu est comme ceci :
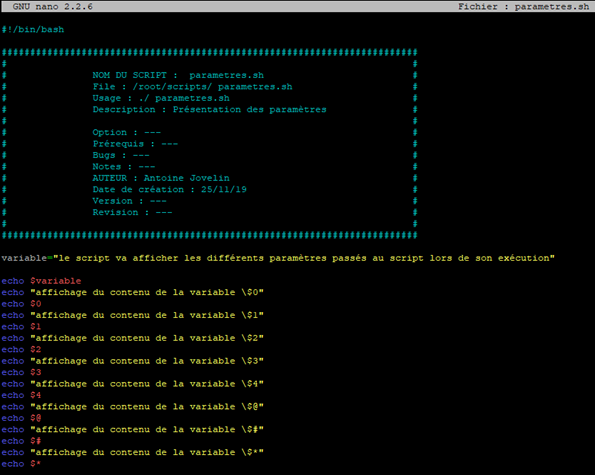
Lorsque l’on lance le script, nous obtenons le résultat suivant :
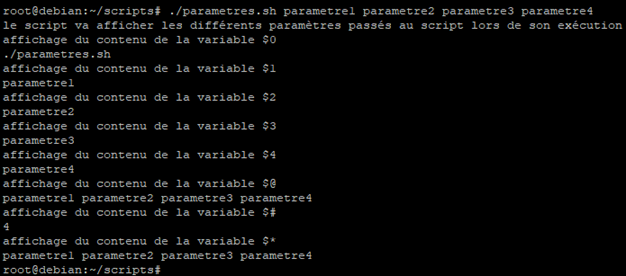
La variable « $0 » affiche effectivement la commande qui a permis de lancer le script.
La variable « $1 » affiche effectivement le premier paramètre passé en argument du script
La variable « $2 » affiche effectivement le deuxième paramètre passé en argument du script
La variable « $3 » affiche effectivement le troisième paramètre passé en argument du script
La variable « $4 » affiche effectivement le quatrième et dernier paramètre passé en argument du script
La variable « $@ » affiche correctement l’ensemble des valeurs des différentes variables « $1 », « $2 », « $3 » et « $4 »
La variable « $# » affiche le nombre d’arguments passés lors de l’exécution du script, ici 4
La variable « $* » a effectivement pris pour valeur l’ensemble des valeurs des différentes variables « $1 », « $2 », « $3 » et « $4 », c’est-à-dire « parametre1 parametre2 parametre3 parametre4 » qui correspond à UN SEUL nouvel argument.
¶ 7 - Autres paramètres spéciaux
En plus des différents paramètres précédemment cités, il existes d’autres paramètres spéciaux :
- « $- »: Ce paramètre va permettre de récupérer les options passées au script via la commande set
- « $! » : Ce paramètre va permettre de récupérer le PID du dernier processus lancé en arrière-plan
- « $? » : Ce paramètre va permettre de récupérer le code retour de la dernière commande
- « $_ » : Ce paramètre va permettre de récupérer le dernier argument de la dernière commande passée
- « $$ » : Ce paramètre va permettre de récupérer le PID su shell qui exécute le script
Passons à la pratique.
Une fois de plus nous allons créer un fichier, le rendre exécutable et l’éditer. Appelons le « test ».
Nous allons y reprendre les différentes cas que nous avons précédemment expliqué
Enregistrer puis lancer le script.
Voici ce que le script va faire :
- Déclarer et affecter une variable
- Afficher le contenu de cette variable
- Afficher le contenu d’une variable non affectée
- Afficher le contenu d’une variable dont le nom comprend une majuscule
- Afficher le contenu d’une variable dont le nom est identique à la précédente mais écrit en minuscule

Ouvrons à nouveau le script et ajoutons à la suite les lignes suivantes, elles seront utilisées par la suite :
Relançons le script :
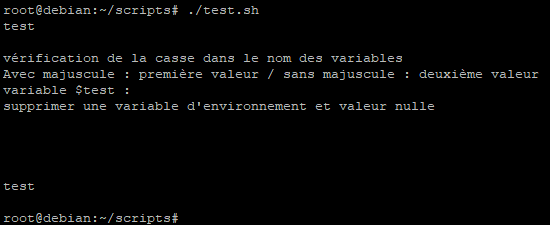
Le début du script se déroule exactement de la même manière cependant les lignes ajoutées donnent le résultat suivant :
- L’affichage de la variable test est nulle puis que celle-ci n’est pas affectée
- L’affichage de la ligne d’information sur les variables d’environnement est visible
- Certaines lignes apparaissent comme étant nulles
- Une ligne affiche test
- Une autre ligne est nulle
Que s’est-il passé ? Nous avons simplement affiché le contenu de variables non affectée ou du contenu vide.
- echo $VAR : affichage d’une variable dont la valeur est nulle
- VAR="" : affectation d’un caractère vide à cette variable
- echo $VAR : affichage du caractère vide à la variable
- VAR=" " : affectation à la variable d’une valeur composée uniquement d’espaces
- echo $VAR : affichage de la variable
- VAR="test" : affectation du contenu « test » à la variable
- export $VAR : export de la variable en tant que variable d’environnement locale (donc pour ce shell et ses enfants)
- echo $VAR : affichage du contenu de la variable
- unset $VAR : suppression de la variable d’environnement locale (avec la commande echo le résultat sera considérée comme vide contrairement à la commande test qui le montrera comme une chaine de caractère non affecté)
- echo $var : affichage d’une autre variable dont le nom est identique mais cette fois écrit différemment et dont le contenu est nul
Maintenant que le corps du script est prêt nous allons faire quelques tests.
Dans le terminal nous allons affecter la variable « test »
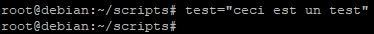
Puis relancer le script. La valeur de la variable test contenu dans le script est toujours nulle car elle n’a jamais été affectée.
En effet, la variable affectée dans le terminal n’est valide qu’en local dans le terminal.
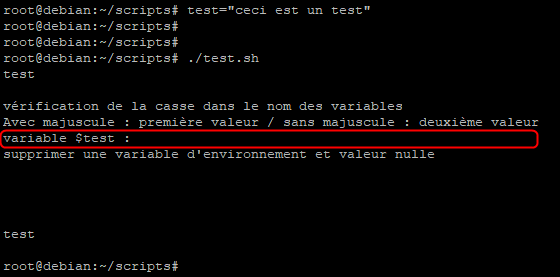
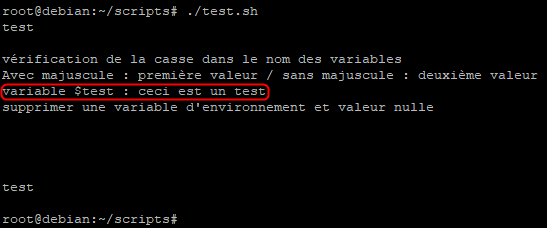
Cependant si l’on fait un export de cette variable, elle deviendra une variable d’environnement locale. C’est-à-dire une variable prise en compte par le terminal et ses processus enfants tel que le script.

Lorsque l’on relance le script cette fois ci la variable d’environnement local « test » est prise en compte et la valeur qui lui est affectée est alors affichée grâce à la commande echo.
¶ 8 – Echappements
¶ 8.1 – Echappements avec le symbole « \ »
L’échappement ou protection d’un caractère est une méthode pour dire au shell qu’il doit interpréter un caractère littéralement.
L'écriture se fait en indiquant un « \ » juste avant le caractère à interpréter littéralement.
Voici quelques exemples :
- \" : donne au guillemet sa signification littérale
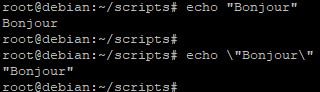
- \ » ne sera pas référencé)
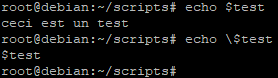
- \\ : donne à l'antislash sa signification littérale
echo "\\" # donne \
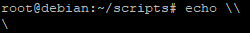
Attention : echo « \ » appellera une deuxième invite de la ligne de commande. Ce n’est pas fonctionnel dans un script et entrainera un message d’erreur.

Avec certaines commandes et utilitaires, tels que « echo » et « sed », l’échappement d’un caractère peut avoir l'effet inverse, cela peut activer un comportement particulier pour ce caractère.
Voici quelques exemples avec « echo » et « sed »
- \a : « alerte » (sonore ou visuelle)
- \b : retour en arrière (backspace)
- \c : suppression du retour-chariot final
- \f : saut de page
- \n : nouvelle ligne (fonctionne avec un « echo -e »)
- \r : retour-chariot, renvoie le curseur en début de ligne
- \t : tabulation horizontale
- \v : tabulation verticale
- \nnn : Le caractère dont le code ASCII est vaut nnn (un à trois chiffres)
- \xnnn : le caractère dont le code ASCII hexadécimal vaut nnn (un à trois chiffres)
¶ 8.2 – Echappements avec les guillemets et apostrophes
Il est également possible d’utiliser les guillemets et les apostrophes pour protéger les caractères spéciaux dans les scripts.
Cela empêchera leur interprétation par le shell et il seront également interprétés littéralement sans avoir à utiliser à chaque fois le symbole « \ ». De plus, cela permettra de les « passer » à une fonction ou à un autre programme.
Il existe cependant une différentes entre les deux :
- Les guillemets : permettent de faire des chaines de caractères dans lesquelles tout sera protégé sauf les « $ », les espace, les « * », etc. Autrement dit les substitutions de variables fonctionneront dans une chaine de caractères protégés par des guillemets.
- Les apostrophes : beaucoup plus stricte que les guillemets. Tout ce qui sera entre les apostrophes sera protégé y compris les « $ » et les « \ » et les guillemets. Les substitutions de variables ne fonctionneront pas.
Prenons un exemple. Nous allons créer un script qui comprendra deux variables contenant « guillemets » et « apostrophes » et nous allons afficher le contenu à l’aide de la commande « echo ». La première variable sera protégée par des guillemets tandis que la deuxième le sera par des apostrophes.
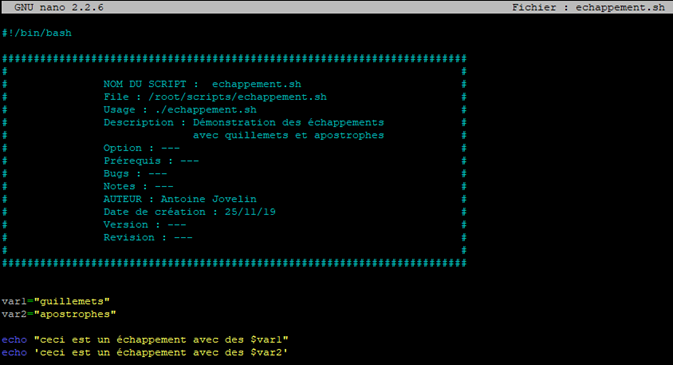
Lançons le script pour voir ce qu’il se passe.

Les guillemets ont effectivement permis de protéger la chaine de caractères du texte tout en substituant la variable, tandis que les apostrophes ont tout protégés en empêchant la substitution de la variable.
¶ 9 - Extraction et soustraction de chaine
Il est possible d’effectuer directement des manipulations sur les chaines de caractères contenues dans les variables.
Pour cela nous utiliserons des accolades « {} »
Par exemple, utiliser permettra d’afficher la longueur de la variable (en caractères).
¶ 9.1 - Extraction
Parmi les différentes manipulation possible nous pouvons extraire d'une variable une sous chaîne de caractères.
L’écriture à respecter sera alors celle-ci :
${nom_de_la_variable:position}
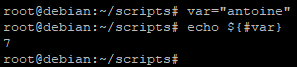
Par exemple si l’on reprend la variable var="antoine", nous pourrons extraire une sous chaine de caractères de cette variable en fonction de la position que nous indiquons
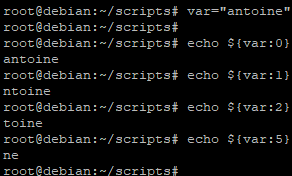
Dans cet exemple nous avons initialisé la variable var avec la valeur antoine puis nous avons affiché sa valeur à partir de la position 0, puis 1, puis 2 et pour finir 5.
Il est également possible de définir la longueur de la chaine de caractères que l’on souhaite extraire.
Pour cela il faudra reprendre la même écriture de l’extraction mais en ajoutant cette fois-ci la longueur souhaitée.
${nom_de_la_variable:position:longueur_des_caractères}
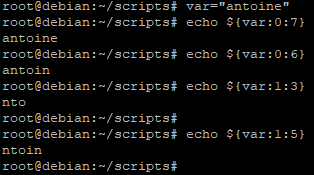
Dans l’exemple ci-dessus, nous avons repris la variable précédente pour en extraire de nouvelles chaines de caractères
- echo ${var:0:7} : affichera une chaine de 7 caractères à partir du premier caractère de la chaine contenue dans la variable
- echo ${var:0:6} : affichera une chaine de 6 caractères à partir du premier caractère de la chaine contenue dans la variable
- echo ${var:1:3} : affichera une chaine de 3 caractères à partir du deuxième caractère de la chaine contenue dans la variable
- echo ${var:1:5} : affichera une chaine de 5 caractères à partir du premier caractère de la chaine contenue dans la variable
Attention : si on indique une longueur plus importante que celle contenue par la chaine de caractères de la variable alors tous les caractères seront affichés à partir de la position sélectionnée.
Avec ce genre de manipulation il sera également possible de créer une nouvelle variable dont la valeur correspondra uniquement à la chaine de caractère extraite de la première variable.
Pour cela il faudra utiliser cette commande :
nom_de_la_nouvelle_variable=${nom_de_la_première_variable:position:longueur_des_caractères}
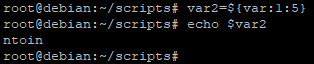
Attention : pour information le premier caractère d’une chaine a pour indice 0
¶ 9.2 - soustraction
Dans le même principe, il est également possible de faire des soustractions de sous chaine de caractères.
${nom_de_la_variable#souschaine_de_caractères}
Supprime la correspondance la plus PETITE de la sous chaine de caractères à partir du DEBUT de la variable.
${nom_de_la_variable##souschaine_de_caractères}
Supprime la correspondance la plus GRANDE de la sous chaine de caractères à partir du DEBUT de la variable.
${nom_de_la_variable%souschaine_de_caractères}
Supprime la correspondance la plus PETITE de la sous chaine de caractères à partir de la FIN de la variable.
${nom_de_la_variable%%souschaine_de_caractères}
Supprime la correspondance la plus GRANDE de la sous chaine de caractères à partir de la FIN de la variable.
Exemple :

Supprime la plus PETIT correspondance entre « a » et « C » à partir du DEBUT de la chaine de caractères (les valeurs « a » et « C » étant incluses à la suppression)

Supprime la plus GRANDE correspondance entre « a » et « C » à partir du DEBUT de la chaine de caractères (les valeurs « a » et « C » étant incluses à la suppression)

Supprime la plus PETIT correspondance entre « b » et « c » à partir de la FIN de la chaine de caractères (les valeurs « b » et « c » étant incluses à la suppression)

Supprime la plus GRANDE correspondance entre « b » et « c » à partir de la FIN de la chaine de caractères (les valeurs « b » et « c » étant incluses à la suppression)
¶ C – Les états de sortie
¶ 1 – Définition
Toutes les commandes Linux, renvoient un « état de sortie » sous forme de valeur numérique comprise entre 0 et 255 lors de leur exécution. En cas de succès la commande renvoie un « 0 » tandis qu’en cas d'échec elle renvoie une valeur supérieure à « 0 » (dite non vide). Ce code de retour est généralement interprétable comme un code d'erreur.
Il en va de même pour les scripts mais aussi pour les commandes ou fonctions se trouvant dans les scripts, chacune d’entre elles possédant son propre « état de sortie » avec son propre code de retour compris également entre 0 et 255.
La dernière commande exécutée dans la fonction ou le script détermine alors le code de sortie. En effet, si la dernière commande exécutée dans un script est en erreur alors l’état de sortie du script sera en erreur tandis que si la dernière commande renvoi un code de retour à « 0 » alors le script en fera de même et tout se sera bien déroulé.
Cet état de sortie pourra donc nous aider à déterminer si un script ou un programme s’est tout simplement bien déroulé ou non.
¶ 2 – Tester l’état de sortie d’un programme
Il est possible d’évaluer un état de sortie à l’aide de plusieurs méthodes de tests :
- if/else
- enchaînements conditionnes
- case
- La commande EXIT
- et bien d’autres
Le code erreur de la dernière commande utilisée est contenu dans la variable « $? ».
En utilisant cette variable, il sera donc possible de récupérer la valeur de sortie du programme exécuté.
Prenons l’exemple d’une commande valide en utilisant la commande echo pour afficher du texte.

L’affichage du texte ayant fonctionné, le code de retour est donc de « 0 »
Prenons maintenant l’exemple d’une commande qui n’existe pas et qui est donc non valide.

Le code de retour est « 127 », ce qui correspond à une commande Bash qui n’a pas pu être trouvée.
Attention : il y a certain codes qui sont réservés et qu’il faut éviter d’utiliser dans les scripts, tel que le code 127 par exemple
¶ 3 – Sortie d’un script
Un script étant lui-même une commande, il est possible de lui faire retourner un code d'erreur avec la commande « exit ».
exit "nnn"
Attention : « nnn » étant l’état de sortie à renvoyer
Par exemple, nous pouvons indiquer dans un script la commande « exit 1 » afin d'indiquer qu’une erreur a été rencontrée et/ou la commande « exit 0 » afin d'indiquer que tout s’est bien déroulé. Sans cette commande, c’est la valeur de sortie de la dernière opération exécutée qui sera renvoyée.
Prenons l’exemple d’un nouveau script que nous appellerons « etat_sortie.sh ».
Ce script sera utilisé pour vérifier si le 1er argument du script est égal à « non », dans ce cas le code de retour sera égal à « 1 » et dans le cas contraire le code de retour sera égal à « 0 ».
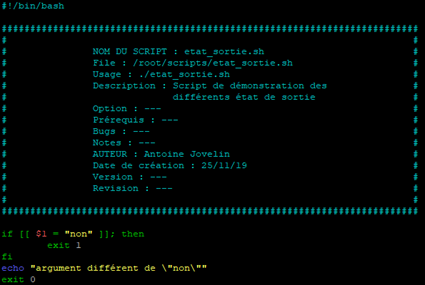
Attention : nous aurons l’occasion de voir les boules « if » plus en détail par la suite.
Testons ce script sans argument et affichons le code retour du script :
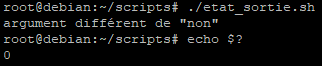
Testons ce script avec l’argument « non » et affichons le code retour du script :

Testons ce script avec un argument différent de « non » et affichons le code retour du script :

Grâce à ce genre de méthode il sera possible de tester certaines conditions ou comportement inattendus qui ne correspondent pas à ce que l’on souhaite comme résultat et d’arrêter le script avec un code retour spécifique.
Par contre à la fin du programme ou du script il faudra toujours renvoyer « 0 » pour permettre de vérifier son bon déroulement.
Attention : pour information, terminer par un « exit 0 » s’agit d’une convention à respecter. De plus, par défaut, si l’on ne met pas à la fin du script un « exit 0 », le script va exécuter un « exit $ ? » ce qui renverra le code retour de la dernière commande exécutée au lieu de celui du script en lui-même.
¶ D – les conditions
¶ 1 – Les conditions avec la commande TEST
L’une des premières commande à connaitre est la commande « test ». Elle va permettre de tester une ou plusieurs expression.
test expression
elle peut également s’écrire comme ceci (c’est d’ailleurs généralement comme ça qu’elle est écrite dans un script) :
[ expression ]
Par exemple :
- [ 2 -lt 3 ] va permettre de vérifier si 2 est inférieur à 3 (« lt » veut dire « lowerthan »)
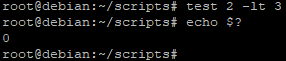
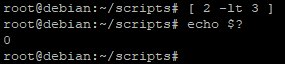
Le code retour est égal à « 0 » donc le test est correct, 2 est bien inférieur à 3
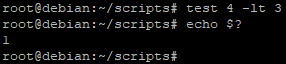
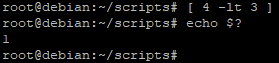
Le code retour est égal à « 1 » donc le test est incorrect, 4 n’est bien sûr pas inférieur à 3
- [ "var2" ] va permettre de vérifier si la variable $var1 est différentes de $var2 (« != » veut dire « not equal »)
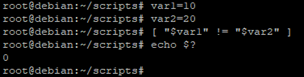
Le code retour est à « 0 », $var1 est bien différent de $var2 (10 et 20)
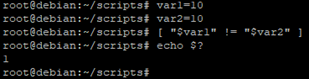
Le code retour est à « 1 », $var1 est identique à $var2 (10 et 10)
Passons à l’écriture d’un script pour illustrer un peu mieux la commande test.
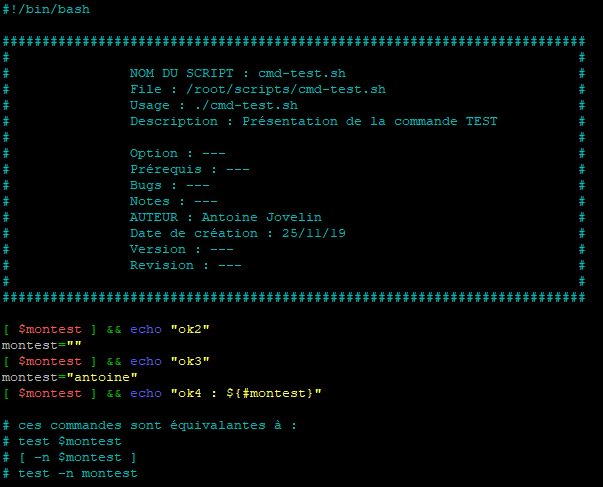
Ce script va nous permettre de tester si une chaine de caractères n’a pas une valeur nulle et d’afficher un résultat en fonction de la valeur de la variable.
Dans le premier cas, si la chaine de caractères n’a pas une valeur nulle alors le script affichera « ok2 ». Toutefois, comme elle n’a pas été initialisée elle n’a pas de valeur et donc sa valeur est par défaut nulle. Dans ce cas le script ne devrai pas envoyer « ok2 »
Dans le deuxième cas on affecte une chaine de caractères vides à la variable, sa valeur est donc toujours nulle et le script ne devrai pas afficher « ok3 ».
Dans le dernier cas, on affecte une valeur à la variable. La chaine de caractères n’étant pas nulle, le script devrai renvoyer « ok4 ».
Nous en profitons également pour afficher la longueur en nombre de caractères contenus dans la valeur de la variable à l’aide de « ${#montest} ».
On l’exécute :

Il est possible de faire en sorte que nos commandes s’effectuent en fonction de l’exécution d’autres commandes et ceci de manière :
- Séquentielle : commande1 ; commande 2
Ici la « commande 2 » s’exécutera quelque que soit le résultat de la « commande 1 »
- Parallèle : commande1 & commande 2
Ici les deux commandes vont s’exécuter en même temps MAIS sans prendre en compte la valeur de retour de l’une ou de l’autre
- Sur erreur (« ou logique ») : commande1 || commande 2
Ici on va exécuter la commande 1 ou la commande 2. Si la commande 1 renvoi un code de retour différent de 0 alors la commande 2 sera exécutée. Si la commande 1 renvoi un code de retour à 0 alors la commande 2 ne sera pas exécutée.
Il s’agit d’un « ou logique ».
- Sur succès (« et logique ») : commande1 && commande 2
Ici on va exécuter la commande 1 et la commande 2 mais uniquement si la commande 1 renvoi un code de retour à 0, dans ce cas la commande 2 sera elle aussi exécutée. Si la commande 1 renvoi un code de retour différent de 0 alors la commande 2 ne sera pas exécutée.
Il s’agit d’un « et logique ». C’est pour cela que dans le script précédent nous utilisons « && » pour afficher le résultat de la commande « echo » en fonction du résultat du test de la variable $montest.
¶ 2 – Les conditions avec « si, alors, sinon et sinon si »
Les « conditions » constituent un moyen rapide et simple de faire en sorte dans un script que « SI le résultat d’un test est comme-ci ou comme-ça », « ALORS une action sera faite », « SINON une autre action sera faite », « SINON SI…….ALORS ».
¶ 2.1 – « si » et « alors »
Le type de condition le plus utilisé est le « if » qui a pour signification « si » suivi d’un « then » qui a pour signification « alors ».
Cette condition doit être vue sous la forme suivante :
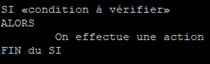
Pour utiliser cette condition dans un script la syntaxe en bash à utiliser sera la suivante :
if [ condition_à_vérifier ]
then
action_à_effectuer
fi
Il existe une autre manière de l’écrire en positionnant le « if » et le « then » sur la même ligne.
Dans ce cas, il faudra impérativement ajouter un « ; » après la condition qui sera vérifiée par le « if ».
Cette façon de faire est la plus répandue.
if [ condition_à_vérifier ]; then
action_à_effectuer
fi
Comme on peut le remarquer, une condition « if » doit toujours se terminer par l’écriture du mot « fi » (qui correspond à « if » mais écris à l’envers). Il sert à indiquer que la condition « if » en cours s’arrête là.
Tout ce qui est entre le « then » et le « fi » sera alors exécuté uniquement SI le test est vérifié.
Pour effectuer un test, nous allons créer un nouveau script que nous appellerons « conditions.sh ».
Nous utiliserons ce même script pour les différents tests de conditions que nous allons effectuer.
Dans un premier temps, notre script comprendra un test « if » avec les deux types de syntaxes afin de montrer que les deux manières de procéder fonctionnent.
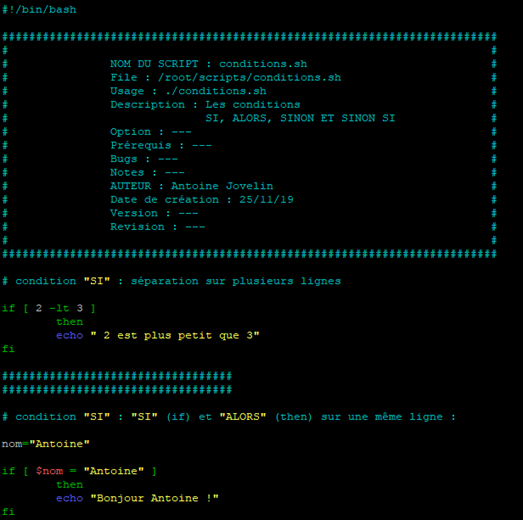
Au lancement du script, les deux conditions vont être testées, dans l’ordre d’écriture et indépendamment l’une de l’autre car l’écriture du script ici est séquentielle.
Si l’une ou l’autre des conditions vérifiées s’avère exacte et renvoie un code de retour à 0 alors la commande echo affichera la phrase lui correspondant.
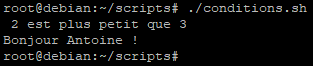
Nous pouvons remarquer que les deux tests de conditions que nous avons effectués sont correctes :
- 2 est plus petit que 3, la commande echo a affiché le message
- $nom est bien égal à Antoine, la commande echo a affiché le message
Dans le cas ou l’un ou l’autre des tests n’aurait pas rempli les conditions souhaitées alors le script n’affichera rien.
Effectuons un test en remplaçant le « A » de « Antoine » par un « a »
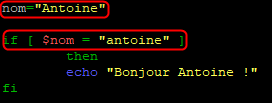
Seule la première condition est vérifiée et seul sont résultat sera affiché.

En effet comme nous l’avons déjà vu précédemment, les noms des variables ainsi que leur valeur sont soumis à la casse.
Ici « Antoine » n’est pas égal à « antoine » et ne remplit donc pas la condition pour afficher le résultat de la commande echo.
¶ 2.2 – « Sinon »
Lorsqu’une condition à vérifier n’est pas remplie, il est possible de préciser une autre action à effectuer que celle prévue à l’origine si la condition avait été remplie. Cela permet d’avoir plusieurs actions réalisables en fonction du résultat pour la même condition.
Dans ce cas il faudra alors ajouter dans la condition « if » un « SINON » qui permettra de réaliser la deuxième action.
Cette condition doit être vue sous la forme suivante :
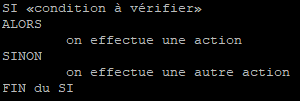
Pour retranscrire cette condition dans un script la syntaxe en bash à utiliser sera la suivante :
if [ condition_à_vérifier ]
then
action_à_effectuer
else
action_à_effectuer
fi
Reprenons le script « conditions.sh » pour l’éditer un peu afin de mettre en place cette nouvelle condition.
Profitons en également pour revoir l’utilisation des paramètres passer au lancement d’un script.
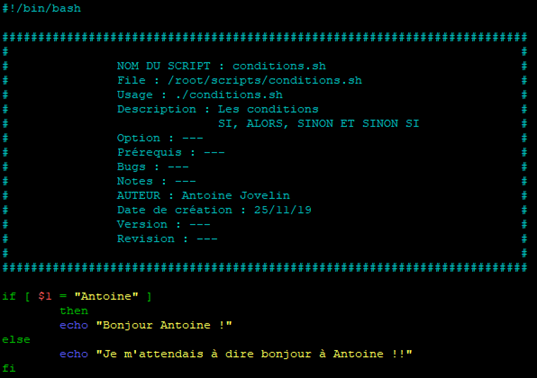
Le script vérifie si le paramètre qui lui a été passé lors de son lancement correspond à Antoine.
SI c’est le cas ALORS il affiche « Bonjour Antoine ! », SINON il affiche « Je m'attendais à dire bonjour à Antoine !! »
On lance le script avec comme argument Antoine
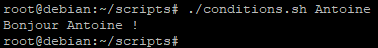
Attention : Le script affiche une erreur s’il n’est pas lancé avec au moins un paramètre. Pour bien faire, il faudrait d'abord vérifier à l’aide d’un « if » si un paramètre a été ajouté à la ligne de commande permettant de lancer le script. Nous en reparlerons un peu plus loin dans cette documentation.
Puis on lance le script avec un autre argument que Antoine

Ici, nous pouvons remarquer que le message affiché correspond à la deuxième commande echo de notre script, signifiant que le paramètre qui a été passé au script ne remplit pas la condition.
¶ 2.3 – « Sinon Si »
En plus des différentes conditions vues précédemment, il en existe une autre qui permet d’ajouter une condition à la suite d’une autre condition en fonction du résultat de la première.
Il s’agit de la commande « elif » (abréviation de « else if ») qui peut se traduire par « sinon si »
Cette condition doit être vue sous la forme suivante :
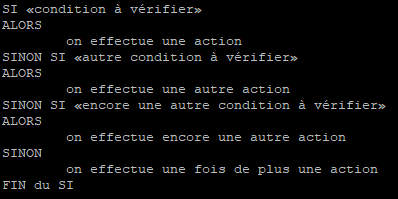
Il est possible d’utiliser autant de fois que l’on veut la condition « SINON SI » (ou « elif » en bash).
Dans l’exemple ci-dessus il y en a deux mais il pourrait très bien y en avoir une seule ou beaucoup plus. Tout dépend du besoin du script. Par contre il n’est possible de mettre qu’un seul « SINON » qui sera alors exécuté à la fin des tests de conditions si aucune des précédentes n’a été vérifiée.
Bash va d'abord analyser la première condition. Se elle est vérifiée, il effectuera la première action indiquée, si elle ne l'est pas alors il ira au premier « sinon si » puis au second, ainsi de suite jusqu'à trouver une condition qui soit vérifiée.
Si aucune condition ne l’est, c'est le « sinon » qui sera alors lu.
Pour retranscrire cette condition dans un script la syntaxe en bash à utiliser sera la suivante :
if [ condition_à_vérifier ]
then
action_à_effectuer
elif [ autre_condition_à_vérifier ]
then
autre_action_à_effectuer
elif [ encore_autre_condition_à_vérifier ]
then
encore_autre_action_à_effectuer
else
action_à_effectuer
fi
Attention : on pourra remarquer que « elif » est suivi d’un « then » mais ne se termine pas par un « fi » contrairement au « if ». Seul le « if » se fini par un « fi ».
Reprenons notre script « conditions.sh » pour y apporter quelques modifications afin d’illustrer tout ça
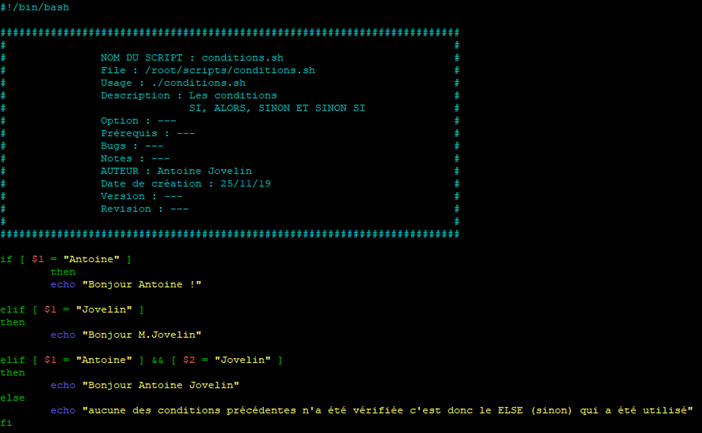
Attention : Le script affichera une erreur s’il n’est pas lancé avec au moins un paramètre. Pour rappel, ici nous ne gérons pas le comportement du script si aucun paramètre n’a été ajouté lors de l’appel au script.
Le script va se comporter de la manière suivante :
- SI le premier paramètre passé au lancement du script est « Antoine » ALORS il affichera « Bonjour Antoine ! »
- SINON SI le premier paramètre passé au lancement du script est « Jovelin » ALORS il affichera « Bonjour M.Jovelin »
- SINON SI le premier paramètre est « scripting » ET le deuxième paramètre est « bash » ALORS il affichera « Bonjour et bienvenue dans l'introduction au scripting bash »
- SINON il affichera « aucune des conditions précédentes n'a été vérifiée c'est donc le ELSE (sinon) qui a été utilisé »

¶ E – Les tests
En plus de vérifier des conditions, il est possible d’effectuer trois types de tests différents en bash :
- des tests sur des chaînes de caractères
- des tests sur des nombres
- des tests sur des fichiers
¶ 1 - Tests sur des chaînes de caractères
Comme nous l’avons indiqué précédemment, toutes les variables en bash sont considérées comme des chaînes de caractères.
Il sera alors très facile de tester la valeur d’une chaîne de caractères à l’aide du tableau suivant :
| Conditions | Significations |
| $chaine1 = $chaine2 | Permet de vérifier si les deux chaînes sont identiques (Attention à la casse, bash y est sensible). Il est aussi possible d'écrire « == » |
| $chaine1 != $chaine2 | Permet de vérifier si les deux chaînes sont différentes. |
| -z $chaine | Permet de vérifier si la chaîne est vide. |
| -n $chaine | Permet de vérifier si la chaîne est non vide. |
Par exemple, vérifions si deux paramètres sont différents.
Pour cela nous allons créer un script appelé « test-chaines.sh » comme ceci :
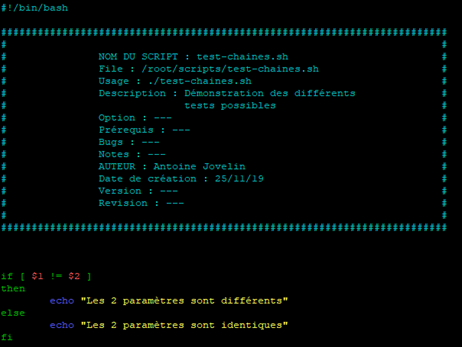
Lançons le script avec deux paramètres différents :

Puis avec deux paramètres identiques :

Reprenons ce script et modifions le pour vérifier un paramètre existe en utilisant « -z » comme indiqué dans le tableau.
Prenons en exemple la vérification de l’existant ou non du premier paramètre que l’on peut passer lors d’un appel au script : $1
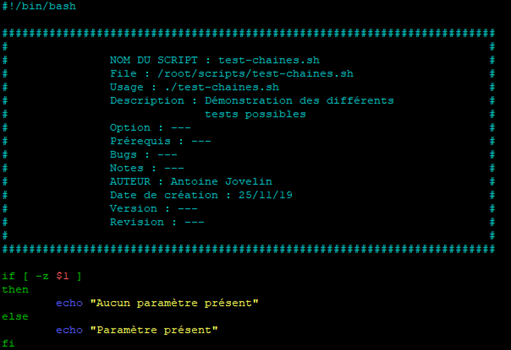
Lançons le script avec un paramètre puis sans paramètre :
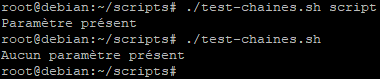
Rappel : Une variable non définie est considérée comme vide par bash.
¶ 2 - Tests sur des nombres
Même si Bash gère les variables comme des chaînes de caractères, il est tout à fait possible d’effectuer des comparaisons de nombres si nos variables en contiennent.
Vous trouverez les différents types de tests disponibles sur le tableau suivant.
| Conditions | Significations |
| $num1 -eq $num2 | Permet de vérifier si les nombres sont égaux. « eq » veut dire ici « equal ». À ne pas confondre avec le « = » qui sert à comparer deux chaînes de caractères. |
| $num1 -ne $num2 | Permet de vérifier si les nombres sont différents. « ne » veut dire ici « nonequal ». À ne pas confondre avec le « != » qui est utilisé sur des chaînes de caractères. |
| $num1 -lt $num2 | Permet de vérifier si num1 est inférieur à num2. « lt » veut dire ici « lowerthan » ( < ) |
| $num1 -le $num2 | Permet de vérifier si num1 est inférieur ou égal à num2. « le » veut dire ici « lowerorequal » ( <= ) |
| $num1 -gt $num2 | Permet de vérifier si num1 est supérieur ànum2. « gt » veut dire ici « greaterthan » ( > ) |
| $num1 -ge $num2 | Permet de vérifier si num1 est supérieur ou égal à num2. « ge » veut dire ici greaterorequal ( >= ) |
On reprend à nouveau le script « test-chaines.sh » pour le modifier :
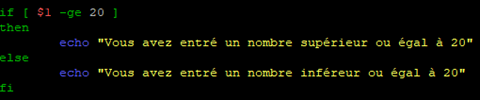
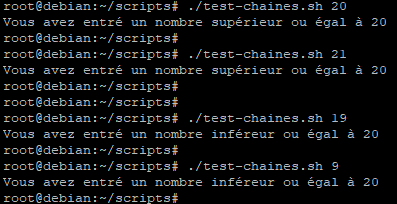
Puis on lance le script avec les paramètres souhaités pour faire le test
¶ 3 - Tests sur des fichiers
Parmi les nombreux avantages de bash sur d'autres langages, nous retrouvons le fait de pouvoir effectuer des tests sur des fichiers pour savoir par exemple :
- s'ils existent
- si on peut écrire dedans
- s'ils sont plus vieux
- plus récents
- etc.
Le tableau suivant présente les différents types de tests disponibles.
| Conditions | Significations |
| -e $nomfichier | Permet de vérifier si le fichier existe. |
| -d $nomfichier | Permet de vérifier si le fichier est un répertoire. Attention sous Linux, tout est considéré comme un fichier y compris les répertoires |
| -f $nomfichier | Permet de vérifier si le fichier est un fichier (un vrai fichier et non un répertoire). |
| -L $nomfichier | Permet de vérifier si le fichier est un lien symbolique (raccourci). |
| -r $nomfichier | Permet de vérifier si le fichier est lisible (droit « r »). |
| -w $nomfichier | Permet de vérifier si le fichier est modifiable (droit « w »). |
| -x $nomfichier | Permet de vérifier si le fichier est exécutable (droit « x »). |
| $fichier1 -nt $fichier2 | Permet de vérifier si fichier1 est plus récent que fichier2. « nt » veut dire ici « newerthan). |
| $fichier1 -ot $fichier2 | Permet de vérifier si fichier1 est plus vieux que fichier2. « ot » veut dire ici « olderthan ». |
Une fois de plus nous allons éditer le script « test-chaines.sh » pour le modifier
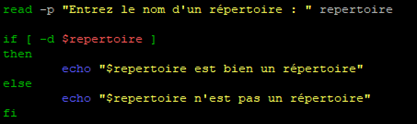
Au lancement du script, celui-ci va nous demander d’entrer le nom d’un répertoire.
il va ensuite lire notre réponse et la placer comme valeur pour la variable « $repertoire »
Pour finir il va tester la condition demander et vérifier si la valeur de notre variable correspond ou non à un répertoire.
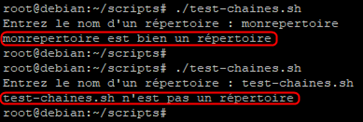
Attention : il est bien sûr possible d’entrer le chemin complet d’un répertoire et non pas seulement son nom. Dans mon exemple le répertoire se trouve à l’endroit où sont stockés les scripts.
¶ 4 - Effectuer plusieurs tests à la fois
Comme nous l’avons évoqué précédemment, il est possible d’effectuer plusieurs tests à la fois.
De manière général on utilise cette vérification multiples avec un « if » et on va chercher à savoir :
- si un test est vrai ET qu'un autre test est vrai
- si un test est vrai OU qu'un autre test est vrai.
Les deux symboles qui seront à utiliser dans ce cas sont :
- && : qui signifie « et » (ou plutôt un « et logique »)
- || : qui signifie « ou » (ou plutôt un « ou logique »)
Lors de leur utilisation, il faudra encadrer les conditions à tester par des crochets.
if [ condition_à_vérifier ] && [ autre_condition_à_vérifier ]
then
action_à_effectuer
fi
Comme il s’agit d’un « if », il sera également possible d’utiliser « elif » et « else » selon les besoins
if [ condition_à_vérifier ] && [ autre_condition_à_vérifier ]
then
action_à_effectuer
elif [ une_autre_condition_à_vérifier ]
then
autre_action_à_effectuer
elif [ encore_une_condition_à_vérifier ]
then
encore_autre_action_à_effectuer
else
action_à_effectuer
fi
Comme précédemment, modifions notre script « conditions.sh »

Ici la script va vérifier les choses suivantes :
- qu'il y ai au moins un paramètre passé au script (autrement dit si « $# » est supérieur ou égal à « 1 »)
- que le premier paramètre correspond bien à « Antoine » (autrement dit si « $1 » est égal à « Antoine »).
Si c’est le cas alors le premier message sera affiché, dans le cas contraire c’est le deuxième message qui sera affiché.

Attention : Bash vérifie d'abord qu'il y ai au moins un paramètre. Si ce n'est pas le cas, il ne fera pas le second test puisque la condition ne sera de toute façon pas remplie. les tests sont effectués l'un après l'autre et seulement s'ils sont nécessaires.
¶ 5 - Inverser un test
Nous pouvons effectuer des tests de manière inversée, c’est-à-dire en utilisant la négation.
Pour cela il faudra utiliser « ! »
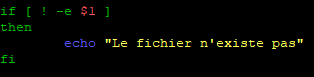
Rappel « -e » permet de vérifier si le fichier existe. Par conséquent « ! -e » permet de vérifier si le fichier n’existe tout simplement pas
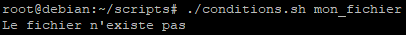
¶ 6 - case : tester plusieurs conditions à la fois
Dans la partie précédente nous avons pu voir un « if » assez compliqué faisant appel à des « elif » et un « else » :
if [ condition_à_vérifier ]
then
action_à_effectuer
elif [ autre_condition_à_vérifier ]
then
autre_action_à_effectuer
elif [ encore_condition_à_vérifier ]
then
encore_action_à_effectuer
else
une_action_à_effectuer
fi
Ce genre de « if » est parfaitement fonctionnel mais lorsqu’il teste toujours la même variable cela peut devenir rapidement illisible.
Il est possible alors de le remplacer par l’instruction « case ».
« Case » permet de tester la valeur d’une même variable mais de façon beaucoup plus lisible avec moins de lignes à écrire.
Il sera représenté de comme ceci :
case $1 in
"valeur")
action_à_effectuer
;;
"autre_valeur")
autre_action_à_effectuer
;;
"encore_une_valeur")
encore_action_à_effectuer
;;
*)
une_action_à_effectuer
;;
esac
Attention : « case » n’utilise pas d’expression régulière mais du « pattern matching » qui correspond aux différentes valeurs indiquées et les actions qui en découlent. Le «symbole « * » n’a donc pas la même valeur qu’en « reg ex »
Le « case » peut paraître un peu compliqué au premier regard mais on va l’analyser.
- case $1 in
Cette partie indique que nous allons tester la valeur de la variable « $1 ». Evidemment « $1 » est un exemple et il est possible de tester la valeur de n’importe quelle variable.
- "valeur")
Cette partie permet d’indiquer la valeur à tester. C’est un équivalant à « si $1 est égale à la valeur ». Pour information il est possible de vérifier des valeurs avec une étoile « * » telles que « ant* ». Dans ce cas toutes les valeurs commençant par « ant » seront prises en compte.
- action_à_effectuer
ici rien de bien compliqué c’est l’action à effectuer si la valeur testée est vérifiée.
- ;;
Cette partie est très importante et ne doit pas être oubliée.
Dans le cas où la valeur de la variable est vérifiée et que l’action choisie a été faite, le double point-virgule dit à bash d'arrêter à cette endroit la lecture du case et de passer à la ligne qui suit le « esac » signalant la fin du case.
- *)
Cette notation correspond à un « else » pour le « case ».Si aucun des différents tests précédents n'a été vérifié, c'est alors cette section qui sera lue.
- esac
Cette partie marque la fin du « case » au même titre qu’un « fi » marque la fin d’un « if ».
Le « case » doit toujours se terminer par un « esac » (qui correspond à case à l’envers), il ne faut donc pas l’oublier non plus.
Si l’on souhaite effectuer une même action en fonction de plusieurs valeurs possibles dans le cas où l’une d’entre elles est vérifiée, il sera alors possible d’utiliser des « ou » dans la syntaxe :
case $1 in
"valeur1" | "valeur2" | "valeur3")
action_à_effectuer
;;
"valeur4" | "valeur5" | "valeur6")
autre_action_à_effectuer
;;
*)
encore_action_à_effectuer
;;
esac
Attention : dans ce cas précis il faudra mettre un seul « | » et non deux comme vu précédemment.
¶ F – Opérations
¶ 1 – Opérateurs arithmétiques
Les opérateurs arithmétiques que l’on peut retrouver sont généralement toujours les mêmes et assez « classiques ».
| Opérateurs | Descriptions |
| + | Permet de faire des additions |
| - | Permet de faire des soustractions |
| / | Permet de faire des divisions |
| * | Permet de faire des multiplications |
| ** | Permet de gérer les puissances (seulement dans Bash 2.02 et supérieur) |
| % | Modulo (récupère le reste de la division entière) |
Certains opérateurs ayant une signification particulière pour le shell, ceux-ci devront être protégés.
De plus, il faut savoir que Bash ne comprend pas l’arithmétique à virgule flottante (les nombres décimaux) et interprète les nombres décimaux comme des chaines de caractères. Toutes les opérations seront donc toujours entières.
Pour des calcules plus complexes il est conseillé d’utiliser le langage « bc »
¶ 2 – Affectation arithmétique
Associe affectation et opérateur arithmétique pour modifier la valeur d’une variable par le résultat d’une opération entre sa valeur précédente et une constante.
| Opérateurs | Descriptions |
| = | affectation arithmétique |
| += | incrémentation |
| -= | décrémentation |
| /= | affectation par division |
| *= | affectation par multiplication |
| %= | affectation du reste de la division entière |
¶ 3 – Opérateurs Binaires
Ces opérateurs s'utilisent sur des binaires (sur des « 1 » et des « 0 »).
| Opérateurs | Descriptions |
| « | décalage d'un bit à gauche (multiplication par deux) |
| » | décalage d'un bit à droite (division par deux) |
| & | « ET » binaire |
| | | « OU » (inclusif) binaire |
| ~ | NON binaire |
| ^ | XOR (« OU exclusif ») binaire |
Tous ces opérateurs peuvent également être associés à l’affectation comme opérateurs arithmétiques.
Exemple : « <<= »
Attention : Certains de ces caractères ayant une signification différentes dans les commandes, ils sont évidemment à utiliser dans le cadre de certaines syntaxes seulement.
¶ 4 – Opérateurs Logiques
| Opérateurs | Descriptions |
| && | « ET » logique |
| | | « OU logique » |
| ! | Permet d’inverser le retour d’une commande et d’agir comme un « NON » logique. Par exemple « != » équivaut à « n’est pas égal » |
¶ 5 – Evaluation arithmétique
Pour utiliser tous ces différents opérateurs nous utiliserons soit la commande « let » soit les doubles parenthèses (qui sont généralement plus souvent utilisées).
Les syntaxes sont les suivantes :
let "expression"
par exemple :
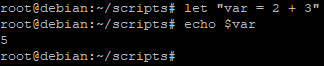
Dans cet exemple, nous faisons l’évaluation de l’opération « 2 + 3 » et faire une affectation de sa valeur dans la variable « var »
Il est possible de mettre ou non des espaces autour des opérateur, le résultat sera le même.
(( "expression" ))
L’utilisation des doubles parenthèses :
- apporte les mêmes fonctionnalités que la commande « let »
- permet la manipulation de variables à la manière du C
- permet une « substitution » d’évaluation arithmétique (de la même manière que l’on peut faire des substitutions de variables)
¶ 6 – quelques Exemples d’opérations
¶ 6.1 – Virgule flottante
Prenons l’exemple d’une opération comprenant une virgule flottante.
Nous allons faire le test avec un script que nous appellerons « operations.sh »
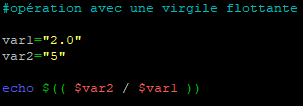
Ici le script va tenter de diviser la variable « var2 » dont la valeur est 5 par la variable « var1 » donc le valeur est 2,0
Comme nous l’avons indiqué, Bash ne permet pas d’effectuer ce type d’opération.

Bash interprète le script par une tentative de division de 5 par une chaine de caractère représentée par « 2,0 ». Forcément cela ne marche pas
¶ 6.2 – division entière
Reprenons le même script pour effectuer une division entière.
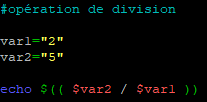

Le résultat peut paraitre étonnant mais comme il s’agit d’une division entière, Bash ne tient compte que de l’entier dans le résultat et non du reste avec la virgule (c’est-à-dire « ,5 » dans notre exemple)
¶ 6.3 – Modulo
Toujours avec le même script que nous modifions encore, nous allons voir concrètement le résultat d’une opération avec l’opérateur « % » pour effectuer un « modulo »
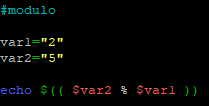

Le résultat est « 1 ».Qu’est-ce que cela signifie ?
Bash va dans un premier temps faire la division de 5 par 2 mais en tenant compte uniquement d’un résultat entier.
On sait par l’exemple précédent que le résultat de cette opération est égal à 2.
Cependant ici nous souhaitons avoir le « modulo » de l’opération, c’est-à-dire le reste de la division ou « ce qui a été mis de côté dans le résultat de la division » mais également sous forme d’entier.
5/2=2,5 : Bash affiche alors un résultat de 2 car il s’agit de l’entier résultant de la division.
Le reste de la division est donc « 0,5 ».
Dans ce cas Bash, ne donnant que des résultats sous forme d’entier, va afficher un résultat de « 1 »
Le « modulo » de 5/2 est donc de 1.
Nous allons nous arrêter ici pour les exemples car nous pourrions en faire pendant des heures et des heures.
¶ G – Les Boucles
Dans cette partie de la documentation, nous allons voir un élément particulièrement important lorsqu’on fait du scripting : les boucles.
En effet, elles permettent de répéter une partie du code autant de fois que nécessaire mais il faut faire particulièrement attention à la syntaxe car il est très facile de faire une faute de frappe entrainement un problème dans l’exécution du script.
¶ 1 – La boucle « While » ou « Tant que »
La boucle « while » est l’une des boucles que l’on retrouve le plus souvent dans les scripts.
Cette boucle doit être vue sous la forme suivante :
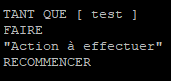
En Bash cette boucle va s’écrire comme ceci :
while [ test ]
do
'Action à effectuer en boucle'
done
Cette boucle permet d'exécuter la ou les commandes présentes entre le « do » et le « done » tant que le ou les tests placés à droite du « while » retourne un résultat qui est vrai.
Tout comme pour le « if » il est possible d’écrire cette boucle d’une autre manière en plaçant les deux premières lignes ensemble à condition de les séparer obligatoirement par un « ; ».
Cette façon de l’écrire est d’ailleurs la plus répandue.
while [ test ] ; do
'Action à effectuer en boucle'
done
¶ 1.1 – Premier exemple
Nous allons créer un nouveau script que nous appellerons « while.sh ».
Le but de ce script sera d’effectuer deux tests :
- Est-ce que la variable « $reponse » est vide ?
- Est-ce que la variable « $reponse » est différent de « Bonjour » ?
Dans ce script nous allons utiliser un « ou logique » à l’aide de « || ». Son utilisation va nous permettre de faire en sorte que tant que l'un des deux tests est vrai, on recommencera la boucle indéfiniment.
On peut voir la boucle comme étant « tant que la réponse est vide ou qu’elle est différente de Bonjour ».

Pour être sûr que le script fonctionne il va falloir que nous commencions par vérifier si la variable n'est pas vide puisque si elle l’était le second test ne fonctionnerai pas.
Essayons le script :
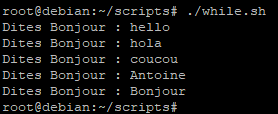
On peut voir que tant qu’on à pas écrit « Bonjour » la boucle continue.
¶ 1.2 – Deuxième exemple
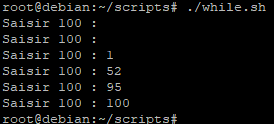
Nous allons modifier notre script « while.sh » pour qu’il demande de saisir 100 et qu’il continue tant que ce n’est pas fait.
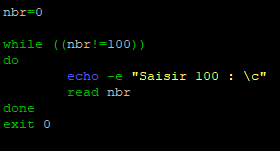
Contrairement au premier exemple, nous n’effectuons pas de vérification pour savoir si ce qu’entre l’utilisateur est vide ou non.
En effet, dans le script nous indiquons que la variable « nbr » est égale à la valeur « 0 » (donc une variable non nulle) ce qui implique que si l’utilisateur ne saisit pas quelque chose et appui sur entrée alors la variable sera égale au chiffre « 0 » et la boucle continuera de demander à ce que l’utilisateur saisisse quelque chose jusqu’à ce qu’il saisisse « 100 »
¶ 2 – La boucle « Until » ou « jusqu’à ce que »
La boucle « until » est l’inverse de la boucle « while » et doit être vue sous la forme suivante :
En Bash cette boucle va s’écrire comme ceci :
until [ test ]
do
"Action à effectuer en boucle"
done
A l'inverse de « while », la commande « until » exécute la ou les commandes situées entre le « do » et le « done » tant que le ou les tests situés à droite du « until » retourne un résultat qui est faux.
Cette boucle peut elle aussi être écrite avec les deux premières lignes en une seule :
until [ test ] ; do
"Action à effectuer en boucle"
done
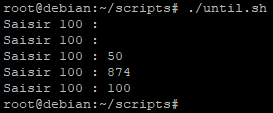
A nouveau nous créons un script. Nous l’appellerons « until.sh ».
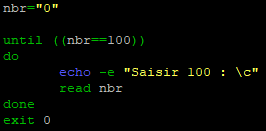
Ici la script exécutera la boucle indéfiniment « jusqu’à ce que » le nombre saisi par l’utilisateur soit EGAL à « 100 »
¶ 3 – La boucle « for » : faire une boucle sur une liste de valeurs
¶ 3.1 – Explication
Une autre boucle très intéressante est la boucle « for ».
Elle permet de parcourir une liste de valeurs et de boucler autant de fois qu'il y a de valeurs dans la liste.
Autrement dit à chaque tour de boucle, la variable sera initialisée avec une des valeurs de la liste et l’action demandée sera faite en prenant compte de cette valeur.
Les valeurs sont traitées dans l'ordre de leur énumération.
- Liste de valeurs citées directement
for variable in valeur1 valeur2 valeur3
do
'Action à effectuer en boucle'
done
- Liste de valeurs contenues dans une variable
for valeurs in $variable
do
'Action à effectuer en boucle'
done
- Liste de valeurs générées par substitution de commande
for valeurs in 'commande'
do
'Action à effectuer en boucle'
done
- Liste de valeurs générées par substitution de caractères de génération de noms de fichiers
for valeurs in *.extension
do
'Action à effectuer en boucle'
done
- Liste par défaut : Arguments de la ligne de commande
for var
do
'Action à effectuer en boucle'
done
for var in $*
do
'Action à effectuer en boucle'
done
- Avec incrémentation d'une variable
for (( valeur=valeurMin; valeur<=valeurMax; valeur++ ))
do
'Action à effectuer en boucle'
done
¶ 3.2 quelques exemples
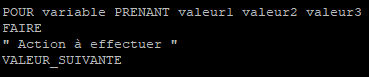
Lorsqu’on écrit une boucle « for » il est tout à fait possible de le faire en citant directement les différentes valeurs
Dans ce cas il faudra voir cette boucle de cette façon :
Nous l’avons vu précédemment, en bash elle s’écrira comme ceci :
for variable in valeur1 valeur2 valeur3
do
'Action à effectuer en boucle'
done
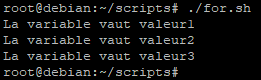
Pour cette exemple nous allons créer un script appelé « for.sh ».

Comme nous l’avons indiqué lors d’une boucle « for » la variable sera initialisée avec une des valeurs de la liste (dans l’ordre de leur énumération).
Dans cette exemple, la variable sera tour à tour initialisée avec « valeur1 » puis « valeur2 » et en fin « valeur3 » et le script affichera ce que vaut la variable à chaque tour de boucle.
Cependant, la liste de valeurs n'a pas besoin d'être définie directement dans le code du script.
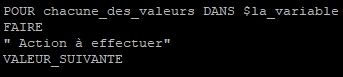
Il est également possible décrire une boucle « for » qui utilisera une liste de valeur contenues dans une variable.
Dans cette manière de faire, il faudra voir cette boucle de cette façon :
Cette fois-ci en Bash on écrira la boucle comme ça :
for valeurs in $variable
do
'Action à effectuer en boucle'
done
Modifions notre script « for.sh » comme ceci :
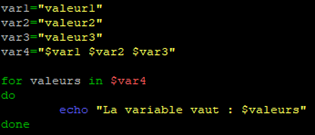
Dans cet exemple, nous commençons par définir des variables.
En effet notre script n’étant qu’un exemple, aucune valeur n’était prédéfinie. Dans un script « complet » il sera possible en fonction de ce que vous voulez mettre en place
Parmi ces variable nous allons définir la 4ème variable la valeur de chacune des autres variables.
Ensuite, la boucle « for » va permettre d’initialiser une autre variable appelée « valeurs » avec une des valeurs qui seront dans la 4ème variable.
Pour finir nous affichons le contenu de la variable « $valeurs » dans l’ordre de leur énumération
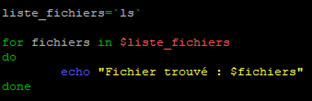
Un autre exemple consiste à effectuer une substitution de commande.
Pour cela nous commencerons par définir une variable qui aura pour valeur une commande à effectuer (dans notre cas « ls »).
Puis nous allons mettre en place la boucle sur cette variable.
variable
for valeurs in $variable
do
'Action à effectuer en boucle'
done
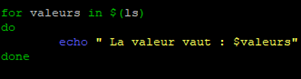
ou alors aussi
for valeurs in $(commande_linux)
do
'Action à effectuer en boucle'
done
On lance le script :
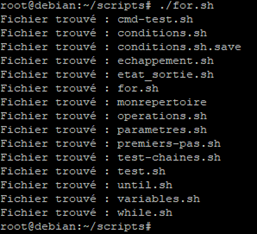
Ici le script va lire la variable qui équivaut à une commande et donc exécuter cette dernière. Puis pour chacune des valeurs retrouvées, autrement dit chacun des fichiers listés par la commande, il effectuera l’action demandée par la boucle « for ».
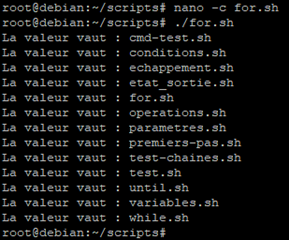
C’est pourquoi nous avons la liste des fichiers un par un qui sont contenus dans le répertoire ou se trouve le script.
Dans cet exemple nous pouvons remarquer qu’il y a deux fichier qui ne sont pas des scripts :
- monrepertoire
- conditions.sh.save
Toute fois nous pouvons très bien utiliser une substitution de caractères de génération de noms de fichiers pour ne lister QUE les fichiers en « .sh » qui correspondent à nos script.
De ce fait nous ne verrons plus les deux fichiers cités au-dessus.
for valeurs in *.extension
do
'Action à effectuer en boucle'
done
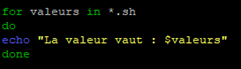
Lançons le script :
¶ 3.3 – La commande « seq »
Dans les autres langages de programmation, la boucle « for » est une boucle qui permet de faire prendre à une variable une suite de nombres. Cependant comme nous venons de le voir, en bash cette boucle permet de parcourir une liste de valeurs.
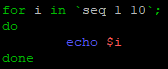
Il existe toutefois une commande permettant de « simuler » une boucle « for » un peu plus classique comme le ferai les autres langages de programmation. Cette commande s’appelle « seq ».
for valeurs in 'seq valeurX valeurY';
do
'Action à effectuer en boucle'
done
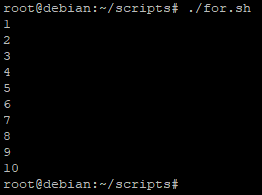
Ici la commande « seq » génère tous les nombres allant du premier paramètre au dernier paramètre (dans notre cas de 1 à 10) et ils seront tous pris en compte dans les valeurs à traiter de la boucle « for »
Il est également possible de définir si le « saut » se fera de 1 en 1 comme dans l’exemple précédant ou par exemple de 5 en 5.
Dans ce cas il faudra écrire la boucle comme ceci :
for valeurs in 'seq valeurX nb valeurY';
do
'Action à effectuer en boucle'
done
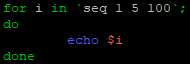
On lance le script :
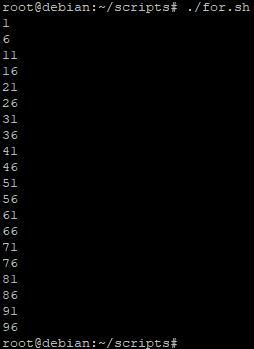
Le script utilise effectivement les paramètres compris entre 1 et 100 mais en effectuant un « saut » de 5 en 5.
¶ 5 – contrôle de boucles
Lors de l’exécution des boucles, il est possible d’utiliser des commandes permettant de les contrôler telles que « break » et « continue » .
Elles peuvent s'utiliser à l'intérieur des boucles « for », « while », « until » et « select ».
La commande « break » permet de sortir d'une boucle tandis que la commande « continue » permet de faire un saut à la prochaine itération (répétition) de la boucle, oubliant les commandes restantes dans ce cycle particulier de la boucle.
¶ 5.1 – Exemple de commande « continue »
Pour notre exemple, nous allons créer encore un script que nous appellerons « continue.sh »
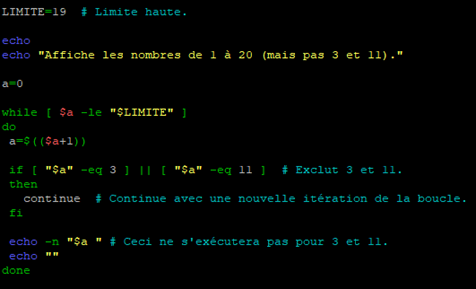
Dans ce script, nous allons initialiser une variable « $limite » à une valeur de 19.
Ensuite, nous allons créer une variable « limite ».
SI la valeur de la variable « $a » est égale à 3 ou 11 alors la commande « continue » sera exécutée, effectuant un saut à la prochaine répétition de la boucle et ceci sans exécuter les commandes restantes dans ce cycle particulier de la boucle.
Pour finir on affiche la valeur de la variable « $a » à chaque tour de la boucle.
Maintenant lançons le script pour voir le résultat.
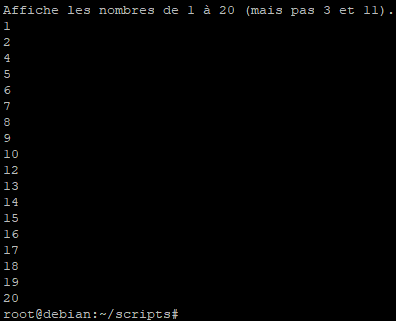
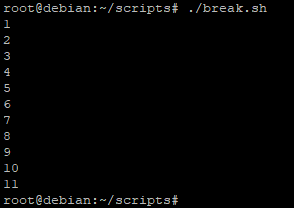
Le script à effectivement traité la boucle « while » et n’a pas affiché les valeurs « 3 » et « 11 ».
¶ 5.2 – Exemple de commande « break »
Reprenons notre script pour le modifier avec la commande « break ».
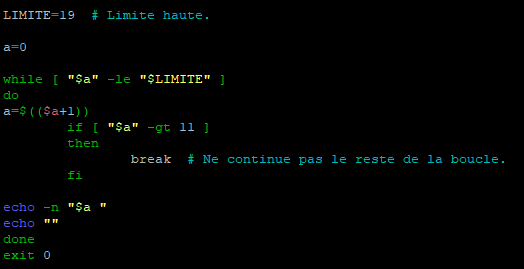
Ici le script va agir de la même manière que précédemment sauf que cette fois-ci la boucle s’arrêtera lorsque la valeur sera supérieur à « 11 » et ceci sans effectuer les commandes qui auraient du l’être dans ce cycle de la boucle.
¶ H – Les Substitutions de commandes
¶ 1 - Définition
Une substitution de commande réassigne la sortie d'une ou de plusieurs commandes.
On dit qu’elle « branche » la sortie d'une commande dans un autre contexte.
Autrement dit, la substitution de commandes extrait la sortie d'une commande (« stdout ») et l'affecte en utilisant l'opérateur « = », permettant ainsi de remplacer une commande par le résultat de son exécution.
Cela permet par exemple :
- L’affectation de la sortie d’une commande à une variable
- L’utilisation de la sortie d’une commande comme argument d’une autre commande
- Etc.
¶ 2 - Syntaxe
La syntaxe d’une substitution de commande est assez simple et il existe deux syntaxes.
Pour la première syntaxe, la commande doit être mise entre des anti-quotes (AltGr + 7) :
`ma commande`
Pou la deuxième syntaxe, qui est la plus utilisée et la plus recommandée, il faudra encadrer la commande avec des parenthèses précédées d’un « $ »
$(la commande)
Attention à ne pas confondre cette syntaxe avec l’évaluation arithmétique qui elle se fait avec des doubles parenthèses.
Cette syntaxe permet une meilleur lisibilité mais également l’imbrication ou autrement dit de faire de la substitution de commande dans de la substitution de commande.
¶ 3 - Exemples
¶ 3.1 – Substitution de commande comme argument d’un test
Comme nous l’avons indiqué il est possible faire une substitution de commande pour utiliser le résultat comme un argument lors d’un test par exemple avec un « if ».
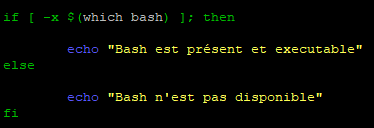
Nous allons faire un test pour vérifier si « Bash » est présent et s’il est exécutable.
Pour cela, nous utiliserons « -x » qui permet de faire cette vérification.
On commence par créer un nouveau script appelé « substitution_cmd.sh »
Ensuite on lance le script

¶ 3.2 – Substitution de commande comme argument d’une boucle for
Cette exemple est très simple à démontrer, nous l’avons réaliser précédemment lorsque nous avons utilisé la commande « seq ».
Nous allons effectuer la même chose mais cette fois-ci en utilisant la syntaxe la plus conseillée.
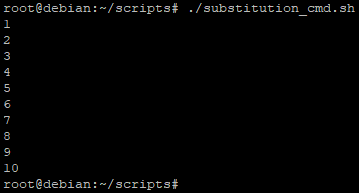
for valeurs in $(seq valeurX valeurY);
do
'Action à effectuer en boucle'
done
On commence par modifier le script « substitution_cmd.sh »
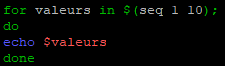
Puis on l’exécute.
Pour rappel, ici la commande « seq » génère tous les nombres allant de 1 à 10. Chacun des résultats de cette commande sera affecté comme valeurs de la variable « $valeurs » qui sera traité par la boucle « for »
¶ 3.3 – Substitution de commande pour une affection
Nous l’avons dit, il est aussi possible de faire une substitution de commande et de passer le résultat de sortie de cette commande comme valeur d’une variable.
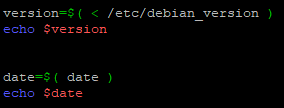
Dans ce cas il faudra la déclarer comme ceci :
variable=$(la commande)
Reprenons le script « substitution_cmd.sh » pour y ajouter un exemple de deux variables :
Puis on lance le script

Il est également possible de l’écrire de la manière suivante
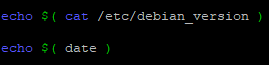
Mise à part l’heure, le résultat sera alors identique
